
![]()
Giriş
Son yıllarda oldukça popüler olan yapay sinir ağlarının ne olduğundan bahsederken aynı zamanda SPSS paket programı aracılığıyla araç satışlarını yapay sinir ağları ile modelleme ve tahminleme uygulaması yapacağız. Yapay sinir ağlarının tek bir tanımı yoktur ama genel olarak insan beyninin öğrenme şeklini kopyalamış bir bilgi işleme sistemidir. Yapay sinir ağı kelimelerini okurken aklınızda canlanan görsel nedir? Aşağıdaki görsel ya da görsele yakın bir şey mi hayal ettiniz? Eğer öyleyse başlıyoruz…
Yapay Sinir Ağları

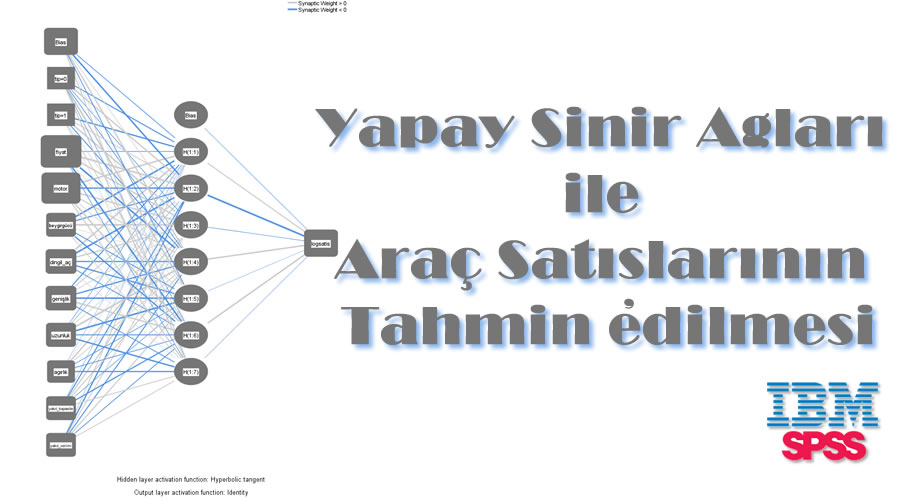
Noktaları olan ve bu noktaları birbirine bağlayan çizgiler… İşte bu görseldeki noktaların insan beynindeki sinir hücreleri veya nöronlar olduğunu varsayarsak aradaki bağlantı kuran çizgiler bir diğer deyişle sinapslar ise insanın doğduğu andan itibaren yaşayarak ve deneyerek öğrendiği, hafızaya aldığı, bilgiler arasında ilişki kurduğu kapasitelerdir. İnsan nasıl doğduğu andan itibaren düşünür gözlemler ve bir olayla karşılaştığında gözlemlerinden faydalanarak hareket eder, gelişir ve deneyimledikçe sinaptik bağlar oluşur hatta bağlantılar sürekli artarsa, işte YSA’da aynı bu şekilde, eğitme (training) yoluyla örnek alarak öğrenir.
Yüzbinlerce sinir hücresinin birbiriyle ilişki içerisinde bulunması sonucunda, sonsuz denilebilecek sayıda sinaptik birleşme söz konusu olacaktır. Bu sayıdaki sinaptik birleşimi gerçekleştirecek bir bilgisayarın, dünyadan daha büyük bir hacmi kaplayacağı hesaplanmaktadır. Ortalama 1,5 kilogram olan insan beyninin karmaşıklığı, bu örnekle olanca yalınlığı ile ifade edilebilmektedir (Cüceoğlu, 1991).
Yapar sinir ağı modelleri, birden fazla isimlendirmeye sahip olsa da hepsi temel de biyolojik sinir sisteminden esinlenmiş ve yüksek performans amaçlanan basit hesaplama araçlarının yoğun bağlantılarından meydana gelmektedir. Basit işlemlerde performansa ihtiyaç duyulmayacağı için hedefi yoğun hesaplamalar gerektiren modellerde örneğin, yüz tanıma, el yazısı tanıma, churn analizi vb. uygulamalarda yüksek performans elde etmektir.

Yukarıdaki şekilde görüldüğü gibi, n adet katmanın (layer), her katmanda biyolojik sinir hücrelerine benzer işlevi yerine getiren ve değişik sayılarda olabilen hesaplama elemanları, katmanlar boyunca bu hesaplama elemanları arasındaki yoğun bağlantılardan meydana gelmektedir. Çeşitli YSA modellerinde kullanılan hesaplama elemanları, yapay sinir hücresi (artifical neuron), düğüm (node), birim (unit) veya işlem elemanı (processing element) olarak isimlendirilir (Haldun AKPINAR, 2017, 306).
Bahsedilen düğüm sistemine örnek yukarıdaki şekildir ve biyolojik sinir sistemine benzetilmektedir. Görüldüğü üzere birden fazla girdi katmanı bulunmakta ve sistemdeki diğer düğümlere gönderebileceği tek bir çıktı katmanı bulunmaktadır. Yapay sinir ağlarına genel giriş yaparak, doğumunun nereden esinlenildiği ve birkaç adet nedir noktalarına değindik.
Adım Adım Araç Satışlarının Tahmin Edilmesi
Şimdi yazının devamında SPSS paket programı aracılığıyla araç satışlarını yapay sinir ağları ile modelleme ve tahminleme uygulaması yapacağız. SPSS neural networkd modülünde yaygın kullanılan iki adet YSA metodu vardır. Birincisi Multi Layer Perceptron (MLP), ikincisi Radial Basis Function (RBF) yapay sinir ağları modelleridir. MLP nonlineer ağ parametrelerini kullanmaktadır, RBF lineer parametreler ile çalışmaktadır ve her iki metod aynı uygulama alanlarında kullanılabilirdir. Veri setini indirmek için lütfen tıklayınız. Veri seti SPSS programıyla beraber gelen Samples dosyasının içindeki car_sales.sav dosyasının türkçeleştirilmiş hali arac_satis.sav dosyasıdır. Girdi olarak araçlara ait karakteristik değerleri kullanacağız. Veriye ait detayları aşağıdaki görselde görebilirsiniz.

Veri setini test/training ayırmak…
Öncelikle veri setini ayıracağız bunun sebebi ise, ayırılan kısımı daha sonra kurulan modelin sağlamasını yapmak için kullanmaktır. Verilerin %80’ini modellemek (training) için %20’sini model sağlamasında kullanmak (testing) için ayıracağız. Bu işlemi Bernoulli dağılımına göre rastgele sonuçlandırdık. SPSS partition (kısımlandırma) mantığında veri setindeki pozitif değerler training, sıfır görünen değerler test verisi ve negatif değerler holdout veri olarak algılanmaktadır. Aşağıda ki görselde bulunan adımlar izlenmelidir.

Dipnot: Analize geçmeden önce ise yukarıda veri setini ayırdığımız Compute Variables bölümünden logaritmik dönüşüm işlemi yapılabilmektedir. Logaritmik dönüşüm işlemleri normal dağılıma uymayan değişkenlere uygulanarak kolayca normal dağılıma uymaları sağlanmakta ve oldukça yaygın kullanılmaktadır. Yukarıdaki görselde, Kısımlandırma (1) yazan alana Ln_satis yazılarak ve Bernoulli (4) yazan alana da Ln(satis) yazılarak bu işlemi sonuçlandırabilirsiniz. Daha sonra normalleştirdiğiniz veri seti ile Regresyon modellemesi yaparak YSA ile Regresyon modellemesinin karşılaştırmasını yapabilirsiniz. YSA için normallik varsayımı gerekli değildir.
Analyze –> Neural Networks –> Multilayer Perceptron

Adımlar izlendiğinde aşağıda bulunan çok sekmeli bir ara yüzle karşılaşacağız. Öncelikle bağımlı ve bağımsız değişken olarak tanımladığımız değişkenleri alanlarına atıyoruz.

Variables sekmesinde çalışacağımız ve model kuracağımız veri yapısını belirleyeceğiz (training).
Adım 1: Dependent variables alanına bağımlı değişkenimizi atıyoruz.
Adım 2: Factors alanına sayısal olarak değerlendiremeyeceğimiz kategorik değişkenlerimizi atıyoruz.
Adım 3: Covariates alanına sayısal tipindeki tahmin edici değişkenlerimizi atıyoruz.
Adım 4: Rescaling of Covariates alanındaki ComboBox’tan modele dahil ettiğimiz değişkenlerin modele nasıl dahil edileceğini belirliyoruz. Dönüşüm yapıp yapmayacağımıza karar veriyoruz. Standardize (Standartlaştırma) seçeneği ile devam ediyoruz.

Partitions sekmesi yapay sinir ağları için oldukça önemlidir. Çünkü YSA modellemeleri üç bölümden oluşmaktadır. Model training verisiyle kurulacak, overtraining yani aşırı öğrenme ile karşılaşmamak için test edilecek olan kısım ve kurulan modelin başarısının ölçüleceği kısım (holdout veri tarafsızlık açısından model kurulumunda kullanılmamaktadır).
Adım 5: Partitioning Variable alanına kısımlandırma değişkeni atılır.

Architecture alanında modelin mimarisi kurgulanmaktadır.
Adım 6: SPSS programının bize sunduğu otomatik mimari seçimi işaretlenir.
Adım 7: Detaylı incelendiğinde girdi aktivasyon fonksiyonu olarak hiperbolik tanjant fonksiyonu kullanıldığı ve çıktı katmanında ise identify fonksiyonu kullanıldığı görülmektedir.
Hyperbolic Tangent: Veriyi -1 ile 1 arasında bir değere dönüştürmektedir.
Sigmoid: Değişkenleri 0 ile 1 arasında bir değere dönüştürmektedir.
Identity: Değişken üzerinde herhangi bir değişiklik yapmıyor.
Softmax: Modeldeki tüm bağımlı değişkenler kategorik ölçekte ise kullanılmaktadır.

Training alanında öğrenme yöntemleri seçilmektedir. Online öğrenme yöntemini seçtik ve SPSS default (varsayılan) ayarları ile oynamadık.
Batch öğrenme yöntemi: Küçük veri setleri için ideal bir yöntemdir. Batch tipi öğrenme de sinaptik ağırlıklar tüm veri setinin üzerinden geçildikten sonra güncellenir, hatayı minimize eden ve sık kullanılan bir yöntemdir. Fakat her güncelleme aşamasında veriler baştan işleme alındığı için işlem süresi bakımından dezavantajlıdır.
(Adım 8) Online öğrenme yöntemi: Büyük veri setleri için online öğrenme yöntemi bacth tipi öğrenme yönteminden daha iyidir. Bunun sebebi ise, sinaptik ağırlıklar her training verisi için güncellenir yani online öğrenme veriden bir kez yararlanır ve ağırlıkları sürekli olarak günceller. Güncelleme işlemi dur kriterlerinden birisi sağlanana kadar devam etmektedir. Eğer tüm verilerin üzerinden geçilmesine rağmen dur kriteri sağlanmazsa tekrar başa dönülerek süreç baştan işletilir. Veri setindeki girdiler çoksa ve veriler bizim örneğimizdeki gibi birbirinden tamamıyla bağımsız değil ise online öğrenme kullanılmalıdır.
Mini-batch öğrenme yöntemi: Veri setiyaklaşık olarak aynı boyutlarda parçalanır. Sinaptik ağırlıklar bir grup tümüyle geçildikten sonra güncellenir ve mini-batch öğrenme yönteminde sadece bir grubun bilgisinden faydalanmış olur. Gerekli görürse diğer gruplara geçer. Mini-batch online öğrenmenin ve batch öğrenmenin karışımıdır (SPSS Neural Network, 2010).

Output alanında da default (varsayılan) ayarlara ek olarak; Predicted by observed chart, Case processing summary ve Independent variable importance analysis seçenekleri seçildi. Özellikle independent variable importance analysis seçeneğini işsaretlememiz önemlidir. Sekmenin altında bu işlemin uzun süreceği uyarısı verilse de uyarının çok büyük veri setleri için geçerli olduğu unutulmamalıdır. Modelde hangi değişkenin çıktı üzerinde etkisi daha fazladır sorusunun cevabını hem grafikler hem de bu seçenek işaretlenerek gösterilmektedir. YSA modellerinde temel sorun tüm seçenekler aynı kalsa da atanan ilk ağırlıkların rastgele olması sebebiyle sonuçların az da olsa farklı çıkmasıdır. Sonuç olarak, değişkenlerin önem sıralaması değişebilmektedir. Çözüm olarak ise, en iyi modeller defalarca denenerek ortalamaları kullanılabilir (Pektaş ve Erdik, 2013).

Save alanında kurulan modelin çıktısı olarak tahmin edilen satış değerlerinin saklanıp saklanmayacağını ve kayıt edilirken otomatik isimlendirme ile mi yoksa özel bir değişken ismi ile mi kayıt edilmek istenildiği seçeneklerinin ayarları yapılmaktadır.
Adım 9: Kurulan model sonucu tahmin edilen satış değerleri saklansın.
Adım adım kurduğumuz YSA modelinin sonuçlarına ulaşmak için OK tuşuna basıyoruz…

Yukarıdaki tablo modelin detaylarını yer aldığı bir özet tablosudur. Kurduğumuz modelin mimarisi ve ağ bağlantıları bir sonraki görseldedir.


Model training kısmı için tahmin ve gözlem değerlerinin saçılım grafiği ve R2 değeri yukarıda gösterilmektedir. Veri setinde model kurulum aşamasının R2 değerinin 0,59 olduğu görülmektedir. Model kurulurken hiç kullanılmayan holdout verisi ile gözlenen R2 değeri 0,70’dir.

Kurulan modelde yukarıdaki çıktıyı alabilmek için, Independent variable importance analyze sekmesini işaretlemiştik. Sonuç olarak hassaslık analizi yapıldığında modele giren değişkenlerin normalize edilmiş önem sıralamalarını görüyoruz. Araç satışlarını etkileyen en önemli değişkenin fiyat olduğunu ve ikinci olarak ise motor olduğunu anlarız.
Şimdi sizlere önerim bu adımları tekrarlayarak bu kez model değişkenini de modele faktör olarak dahil etmeniz ve elde ettiğiniz R2 değerlerinin farkını incelemeniz. Tahminen R2 değerlerinde artış gözlenecektir ve bu da yapay sinir ağları modellerinin ordinal değişken tiplerini işleyebilmesi özelliği ile üstünlüklerini göstermektedir.
Sonuç
Bu yazıda SPSS ile yapay sinir ağı modelleme uygulaması yaptık. Yaptığımız uygulamada, genel modelleme mantığını kavramaya çalıştık. Tarafsız kısımlandırma verisi seçiminin nasıl yapılabileceğine de değindik. Umarım faydalı olmuştur. Sorularınız için alttaki yorum bölümünden ve linkedln profillerimizden bize ulaşabilirsiniz.
Bol verili günler dilerim. 🧐
Kaynakça
- Wikipedia. “Yapay Sinir Ağarı.” Erişim 24 Ekim, 2019. https://www.wikizeroo.org/index.php?q=aHR0cHM6Ly90ci53aWtpcGVkaWEub3JnL3dpa2kvWWFwYXlfc2luaXJfYcSfbGFyxLE
- Taşpınar, Haldun. Data. 2.Baskı/İstanbul: Papatya Yayınları, 2017.
- Osman Pektaş, Ali. SPSS ile Veri Madenciliği. 1.Baskı/İstanbul: Dikeyeksen Yayınları, 2013.
- Aklınızı Keşfedin. “Sinaptik Boşluklar.” Erişim 24 Ekim, 2019. https://aklinizikesfedin.com/sinaptik-bosluk-nedir/
merhabalar yüksek lisans tezimde matlab programı ile hisse senedi fiyat tahminlemesi yapmak istiyorum ve bunun için kaynak arıyorum. yardımcı olabilir misin?
VBO sitesi taşındıktan sonra yorumlarımız da kaybolmalar oldu. Bu nedenle mail adresinize tekrar birkaç kaynak ilettim.
İyi günler dilerim.
emeğinize sağlık ilk okumamda tam olarak kafama oturtamadım ama faydali oldu rsimler tam olarak görünmüyor bu konuda iyileşirme yaparsanız dah ıyı olabilir tekrar tesekkur ediyrum
Özgür Bey merhaba, size uygulamada kullandığım görselleri mail ile ilettim. Daha net görüneceğini düşünüyorum. Bundan sonraki yazılarda da görüntü kalitesine dikkat edeceğim. Teşekkür ederim.
Uygulamalı yazılar her zaman anlaşılması daha kolay oluyor. Elinize sağlık. Çok güzel anlatmışsınız. Devamını bekliyorum.
ben de python ile hisse senedi fiyat tahminlemesi yapmak istiyorum ve bunun için kaynak arıyorum. yardımcı olur musunuz?
merhaba fuzzy logic (bulanık mantık) çalışmak istiyorum temel kaynak öneriniz var mı ?
mail adresinizi alabilrmiyim yapay sinir ağlarında normalizasyon nasıl yapılıyor
Merhaba,
YSA ile bağımsız değişkenler verilip ve target değişkenin bir kısmı verilip kalanı tahmin edilebiliyor mu?
Ben sizin anlatımınızda göremedim kendim de denedim olmadı
Yardım rica ederim.
Buarada anlatım çok anlaşılır olmuş teşekkürler