

![]()
Veri ön işleme yazı dizimize devam ediyoruz. Bu yazıda ilk yazımızda kullanmaya başladığımız veri seti üzerinden uygulamalı olarak veri setimizi ne şekilde eğitim ve test verisi olarak parçalayıp yeni değişkenlere atayacağız onu göreceğiz. Böyle bir şeyi niçin yapıyoruz biraz bahsedelim:makine öğrenmesinde özellikle de denetimli (supervised) öğrenmede modelimizi veri ile eğitiriz. Yani veriden model öğrenir ve başka veri setlerinde öğrendiklerini kullanır bize sonuçlar sunar. Biz bu eğitimin ne kadar doğru ve sağlıklı olduğunu da test verileriyle test ederiz ki modelin kullanılabilir olup olmadığına karar verelim. Aslında insanlar olarak biz de hayatımızda aynı mantığı yürütürüz. Çocukluktan beri hayatta bir çok durumla karşılaşırız veya benzer durumlarla karşılaşanları gözlemleriz. Buradan elde edilen tecrübelerimizi yeni durumlar karşısında kullanırız. Yani daha önce sınıflandırdığımız durumları kullanarak karşılaştığımız yeni durumu da o sınıflardan birine atarız ve ona göre davranırız.
Python ile Veri Seti Ayırma
Python ile kütüphanelerimizi indirerek başlıyoruz.
from sklearn.cross_validation import train_test_split
Dört tane yeni değişken oluşturacağız. Bunlardan ilk ikisi bağımsız değişkenler matrisi için eğitim ve test, diğer ikisi bağımlı değişken için eğitim ve test.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
cross_validation kütüphanesinin modülü olan train_test_split()’e vereceğimiz ilk iki parametre X ve y, yani veri kaynağı olarak ne kullanılacak onu belirtmiş oluyoruz. test_size parametresi ile test için ne kadar bir veri ayrılacak onu belirtiyoruz. Yukarıdaki 0.2 verinin % 20’sini test için ayır demek. Bu parametreyi atamakla aslında train_size’ı da dolaylı olarak 0.8 yapmış oluyoruz. Yani yukarıda veri setinin %20’sini test, % 80’ini eğitim olarak ayırmış bulunuyoruz. Örneklem için bir random_state değeri belirliyoruz. Aynı sonuçlar için aynı rakamlar kullanılması tavsiye edilir. Yukarıdaki kodları çalıştırdıktan sonra bakalım neler olmuş? Spider variable explorer penceresi:
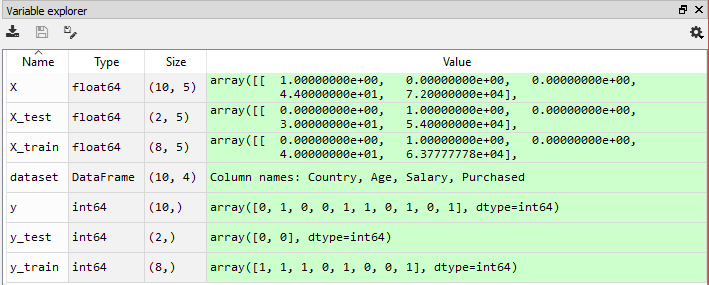
Yukarıda oluşturduğumuz dört yeni değişkeni bu pencerede görebiliyoruz. Şimdi değişkenlerin dördüne de bir göz atalım bakalım nasıl görünüyorlar:
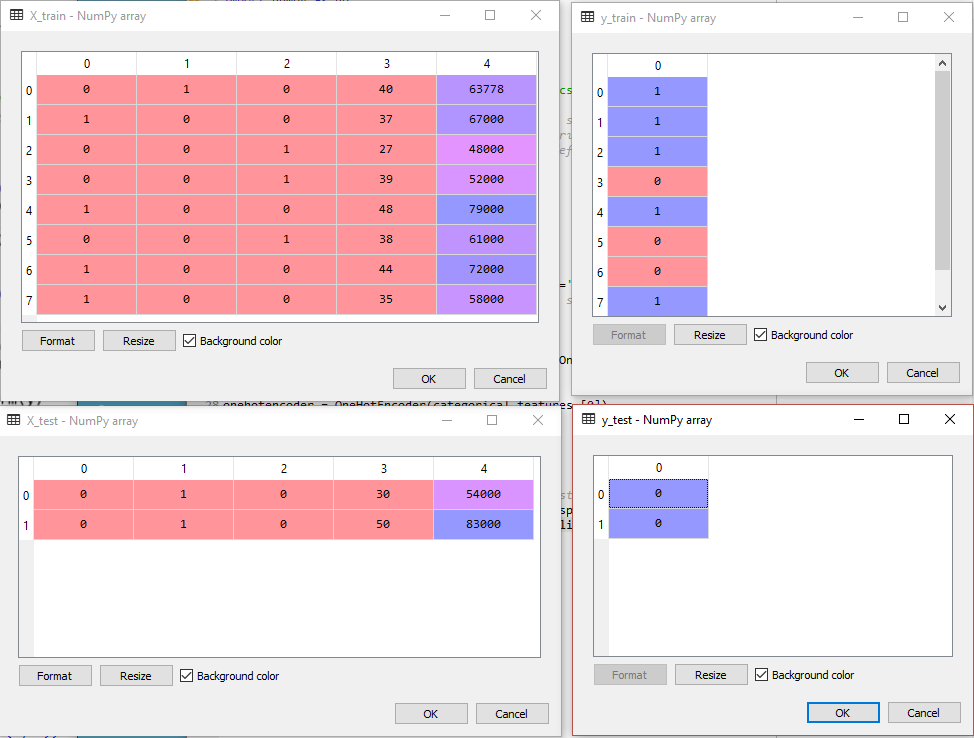
Evet, tam istediğimiz gibi %80-%20 bölünmüşler.
R ile Veri Seti Ayırma
Python ile işimiz bitti. Şimdi aynı işlemi R ile yapalım.
Önce gerekli kütüphaneleri yükleyelim:
install.packages('caTools')Bu komut sonunda RStudio ‘https://cran.rstudio.com/bin/windows/contrib/3.3/ caTools_1.17.1.zip’ adresine gidip ilgili paketi R’ın windows kütüphanesine indirecektir. Ancak bu kütüphaneyi kullanmak için bir adım daha atmamız gerekiyor. Diske inen kütüphaneyi R bağlamında ana belleğe çağırmalıyız. Bunun için kodumuz aşağıdadır. Aynı işlemi RStudio Packages penceresinde ilgili pakete tıklayarak da yapabiliriz.
library(caTools)
Veri setini eğitim ve test olarak parçalara ayırma konusunda genel mantık Python ile aynı olsa da R’ın tarzı biraz daha farklı. Yine Python’daki gibi örneklem için bir rakam ayarlıyoruz. Daha sonra split adındaki değişkene hedef niteliği (Purchased) baz alarak belirlediğimiz bir oranda (%80) rastgele ayrıştırma yapıyoruz. Bu ayrışmada R her bir satır için TRUE ve FALSE değerlerinden oluşan bir vektör oluşturuyor. Bu vektördeki %80 TRUE değerlere denk gelen satırları eğitim seti, FALSE’e denk gelen satırları da test değişkenine atıyoruz. Bu anlattıklarımı yapan kod parçası aşağıdadır:
set.seed(123) split = sample.split(dataset$Purchased, SplitRatio = 0.8) training_set = subset(dataset, split == TRUE) test_set = subset(dataset, split == FALSE)

selam
hocam, pythonda test ve eğitim setlerimizi kendimiz belirleyemez miyiz ? örneğin 1,7,8,9. satırlar test olsun, diğer kalanları eğitim yapmak istiyorum ?
Selam. Belirleyebilirsiniz elbette. Test seti, veri setini temsil etme gücünü kaybetmediği sürece sorun yok. Yüzbinlerce satırdan oluşan setlerde bunu elle yapmak pek mümkün olmayacağından rassal olarak seçim yapılıyor.
Hocam merhaba yarışmalarda veri setleri ayrılmış bir şekilde geliyor. Hedef değişken train verisinde bulunurken test verisinde bulunmuyor. Model tahmininin skorunu öğrenmek için y_test’i nereden almam gerekir?
Selam
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)buradan geliyor.
Hocam bana yardımcı olursanız sevinirim,bir ödevim var , yapay sinir ağları, veri seti normalize edilerek eğitim ve test veri seti hazırlayın dediler,ama benim alanım değil ama yapmak mecburiyetindeyim, yüzde 85 eğitim,yüzde 15 test veri seti olacak şekilde istendi, yardımcı olursanız çok çok sevinirim, teşekkür ederim.