

![]()
Merhaba VBO okuyucuları, korona virüsü sebebiyle hepimiz çok zor günler geçirmekteyiz. Evde geçirdiğimiz bu günleri kendimizi daha fazla geliştirerek değerlendirmeliyiz. Ben de bu süreçte Türkçe metinlerde konu tahmini üzerine bir uygulama yaparak sizleri bilgilendirmek istedim.
Bu yazımda konu tahmini için hem denetimli hem de denetimsiz makine öğrenmesi modelleri kullanarak metinlerin hangi konuları kapsadığını tahmin etmeye çalıştım. Tahminleri yaparken kullandığım modellerden bir tanesi OneVsRest çoklu sınıflandırma yöntemi. Bu yöntem bire karşı hepsi olarak da bilinen bir denetimli sınıflandırma modelidir. Daha fazla detaylı bilgi almak isteyenler buraya tıklayarak öğrenebilirler. Denetimsiz olarak ise Latent Dirichlet Allocation(LDA) modelini kullandım. LDA modeli, bayes teorisini kullanarak hangi kelimenin hangi dokümanda hangi konuyu temsil ettiğini tahmin etmeye çalışan bir denetimsiz sınıflandırma modelidir.
Bu kadar ön bilgi yeterli daha fazla bilgi almak isteyenler kaynaklarda bıraktığım dokümanları inceleyebilirler 🙂 . Gelelim bu işin en temeli ve neredeyse %80’ini kapsayan veriye ve onu işlemesine. Veriye aşağıdaki butona tıklayarak erişebilirsiniz.
Gelin biraz verimizi tanıyalım.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import nltk
import re
import warnings
from collections import Counter
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
#verinin tanımlanması
data = pd.read_excel('topic_modeling.xlsx')
data.head()
#veriye ön bakış data.info()
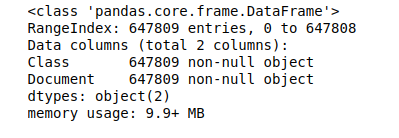
Verimiz iki değişkenden oluşmakta. Biri metinlerin bulunduğu Document değişkeni diğeri ise metinlerin etiketlerinin bulunduğu Class değişkeni. 647809 adet veri bulunmakta ve 49 adet etikete sahip.
#etiketlerin elde edilmesi class_ = Counter(data['Class']).keys() class_
dict_keys(['astronomi', 'hükümet', 'yasa', 'bölge', 'televizyon', 'bilgisayar', 'işletme', 'film', 'tıp', 'askeri', 'zaman', 'organizasyon', 'spor', 'futbol', 'inşaat', 'coğrafya', 'müzik', 'oyunlar', 'insanlar', 'kraliyet hanedanı', 'eğitim', 'ödül', 'biyoloji', 'internet', 'simgeler', 'kitaplar', 'ortak_medya', 'görsel_sanat', 'travel', 'kurgusal_evren', 'havacılık', 'ulaşım', 'kimya', 'dil', 'finans', 'otomotiv', 'opera', 'çizgiromanlar', 'basketbol', 'yemek', 'interests', 'tiyatro', 'din', 'ölçü_birimi', 'moda', 'meteoroloji', 'mühendislik', 'exhibitions', 'fizik'])#etiketlerin içerisindeki veri sayıları sum_ = Counter(data['Class']).values() sum_
dict_values([4997, 19921, 3083, 89926, 20612, 7366, 8258, 42623, 12107, 21378, 11146, 14847, 32363, 8560, 5023, 7340, 53235, 5685, 129943, 7683, 8423, 14214, 18917, 2357, 5160, 21726, 6155, 3984, 3552, 7883, 3982, 4156, 4696, 5352, 942, 2448, 4125, 1782, 3721, 4222, 1479, 2101, 6734, 1228, 460, 212, 1078, 129, 495])Yukarıda etiketlerimizin ve her birinin sahip olduğu metin sayılarına bakıyoruz. Gelin bir de görselleştirerek bakalım etiketlerimize.
#elde edilen etiketlerin ve içerdiği sayıları görselleştirmek için dataframe yapısına çeviriyoruz.
df = pd.DataFrame(zip(class_,sum_), columns = ['Class', 'Toplam'])
#etiketlerin görselleştirilmesi - çubuk grafiği
df.plot(x = 'Class' , y = 'Toplam',kind = 'bar', legend = False, grid = True, figsize = (15,5))
plt.title('Kategori Sayılarının Görselleştirilmesi', fontsize = 20)
plt.xlabel('Kategoriler', fontsize = 15)
plt.ylabel('Toplam', fontsize = 15);
#etiketlerin görselleştirilmesi - pasta grafiği
fig, ax = plt.subplots(figsize=(15, 10))
ax.pie(df.Toplam, labels =df.Class, autopct = '%1.1f%%', startangle = 90 )
ax.axis('equal')
plt.show()
Görmüş olduğunuz gibi elimizdeki veri çok fazla etikete sahip. Ben burada herhangi bir etiketi elemeden devam edeceğim ama isterseniz siz etiketlerden bir kaçını eleyebilirsiniz. Şimdi veriye biraz önişleme metotları uygulayarak noktalama işaretlerini ve günlük hayatta çok fazla kullanılan ama tek başına bir anlam ifade etmeyen stopwords olarak adlandırdığımız kelimeleri kaldıralım ve bütün metinlerimizi küçültelim. Bu sayede elimizde kullanabileceğimiz daha temiz ve düzenli bir veri olacaktır.
#Burada nltk kütüphanesinde bulunan Türkçe stopword'leri bir değişkene atıyoruz.
WPT = nltk.WordPunctTokenizer()
stop_word_list = nltk.corpus.stopwords.words('turkish')
#Daha sonra verimizdeki noktalama işaretlerini kaldırıp stopword'lerden arındırıyoruz.
docs = data['Document']
docs = docs.map(lambda x: re.sub('[,\.!?();:$%&#"]', '', x))
docs = docs.map(lambda x: x.lower())
docs = docs.map(lambda x: x.strip())
#stopword'leri kaldırıyoruz buradaki fonksiyon ile
def token(values):
filtered_words = [word for word in values.split() if word not in stop_word_list]
not_stopword_doc = " ".join(filtered_words)
return not_stopword_doc
docs = docs.map(lambda x: token(x))
data['Document'] = docs
print(data.head(20))Verimizin son hali aşağıdaki gibidir.
Class Document
0 astronomi ngc 5713 başak takımyıldızı bölgesinde bulunan...
1 astronomi birçok katalogda sarmal gökada olarak sınıflan...
2 hükümet corina casanova i̇sviçre federal şansölyesidir
3 yasa casanova i̇sviçre federal yüksek mahkemesi esk...
4 hükümet corina casanova bir federal parlementerdir
5 bölge casanova hristiyan demokrat halk partisi üyesi...
6 hükümet i̇sviçre dışişleri bakanlığı i̇sviçre federal ...
7 hükümet i̇sviçre'nin dış ilişkilerini sürdürmekle göre...
8 bölge gilgit baltistan pakistan kuzey bölgeler urduc...
9 bölge 72496 km alan kaplamakta oldukça dağlık bir ar...
10 bölge bölgesel başkenti gilgit'dir
11 bölge urduca peştuca wakhi shina balti khuar buruşas...
12 bölge denton amerika birleşik devletleri'nde teksas ...
13 bölge coğrafî olarak oklahoma teksas sınırının 61 ki...
14 bölge şehir kuzey teksas'ın büyük üniversitesi olan ...
15 televizyon howard stark marvel'ın kurgusal bir karakteridir
16 bilgisayar mac os x snow leopard sürüm 106 türkçe kar leo...
17 bilgisayar i̇lk genel gösteri dünya çapında pazarlamadan ...
18 bilgisayar mac os x'in sürümü selefi mac os x v105 leopar...
19 bilgisayar aynı zamanda ilk mac os sürümü system 712'den ...Verimizi tahminleme yapmak için sayısal veri haline getirmemiz gerekiyor. Tfidf skorlama yöntemini kullanarak veriyi sayısallaştırmadan önce test ve train olarak veriyi ayırıyoruz.
dataDoc = data['Document'].values.tolist() dataClass = data['Class'].values.tolist() #test ve train olarak verinin ayrılması x_train, x_test, y_train, y_test = train_test_split(dataDoc, dataClass, test_size = 0.3, random_state = 42) #tfidf işlemi ## max_df 0,9 tfidf skorundan fazla olanları kelimeleri alma ## min_df 5 frekansından düşük olan kelimeleri alma tfidf_vectorizer = TfidfVectorizer(ngram_range=(1,2), max_df=0.9, min_df=5) x_train_tfidf = tfidf_vectorizer.fit_transform(x_train) x_test_tfidf = tfidf_vectorizer.transform(x_test)
Tfidf skorlama yöntemi dokümanda sıkça geçen kelimelerin baskın olması ve dokümanı temsil etmesinin önüne geçilmesini sağlar. Burada n_gram_range olarak unigram ve bigram yani tekli ve ikili kelimeleri göz önüne almasını istedim, max_df ve min_df ise kelime dağarcığı oluştururken kelimelerin metinde geçen sıklığına göre ayarlama yapılmasıdır.
Train datası olarak ayırdığımız veride en fazla geçen ilk 20 kelimeye bakalım.
words_counts = Counter([word for line in x_train for word in line.split(' ')])
most_common_words = sorted(words_counts.items(), key=lambda x: x[1], reverse=True)[:20]
most_common_words[:20][('bir', 121182),
('olarak', 48115),
('olan', 39859),
('yılında', 30484),
('tarafından', 24377),
('sonra', 23792),
('ilk', 23313),
('büyük', 16955),
('yer', 15010),
('arasında', 12783),
('oldu', 12070),
('kadar', 11815),
('the', 11342),
('2', 10580),
('iki', 10370),
('bulunan', 9993),
('aynı', 9876),
('1', 9866),
('dünya', 9489),
('adlı', 9265)]Denetimli Tahminleme Yöntemi
Artık verimiz tahminleme yapmak için hazır. Ben önce OneVsRest çatı modelini kullanarak üç adet denetimli modelde tahminleme yaptım ve her birinin başarı oranını karşılaştırdım. Burada kullandığım modeller Lojistik Regresyon, LineerSVC ve Stochastic Gradient Descent. Modelleri seçerken herhangi bir özel sebebim yok tamamen rastgele bu modelleri seçip tahminleme yaptım. Tabi daha iyi sonuçlar veren modeller olacaktır.
from sklearn.metrics import accuracy_score
from sklearn.linear_model import LogisticRegression,SGDClassifier
from sklearn.multiclass import OneVsRestClassifier
#logistic regresyon
model = OneVsRestClassifier(LogisticRegression(penalty = 'l2', C=1.0))
model.fit(x_train_tfidf, y_train)
print ("Logistic Regression Accuracy={}".format(accuracy_score(y_test, model.predict(x_test_tfidf))))
logisticpred = accuracy_score(y_test, model.predict(x_test_tfidf))
#stochastic gradient descent
model2 = OneVsRestClassifier(SGDClassifier(loss = 'hinge', penalty = 'elasticnet', max_iter = 5))
model2.fit(x_train_tfidf, y_train)
print ("SGD Accuracy={}".format(accuracy_score(y_test, model2.predict(x_test_tfidf))))
sgdpred = accuracy_score(y_test, model2.predict(x_test_tfidf))
#lineersvc
from sklearn.svm import LinearSVC
from sklearn.pipeline import Pipeline
SVC_pipeline = Pipeline([
('clf', OneVsRestClassifier(LinearSVC(), n_jobs=1)),
])
SVC_pipeline.fit(x_train_tfidf, y_train)
prediction = SVC_pipeline.predict(x_test_tfidf)
print('LineerSVC accuracy is {}'.format(accuracy_score(y_test, prediction)))Logistic Regression Accuracy=0.6042203732575909
SGD Accuracy=0.45770107490364975
LineerSVC accuracy is 0.645472180629094#test accuracy'lerinin görselleştirilmesi accuracys = [logisticpred,lineersvcpred,sgdpred] plt.plot(["Log", "LineerSVC", "SGD"],accuracys , marker = "x" , markersize = 9 , color = "red");

Denetimsiz Tahminleme Yöntemi
Görmüş olduğunuz gibi modellerin başarısı biraz düşük kaldı, özellikle stochastic gradient descent modeli çok düşük bir tahmin başarısı gösterdi. Tabi bu verinin büyüklüğü ya da model parametrelerinin daha iyi ayarlanmasıyla yükseltilebilir ya da başka modeller deneyerek veri için daha uygun bir model bulunabilir. Gelin bir de denetimsiz model olan Latent Dirichlet Allocation(LDA) modeline bakalım.
LDA modeli için veriyi CountVectorizer sınıfı ile uygun hale getiriyoruz. Daha sonra model parametrelerini ayarlayarak modeli eğitiyoruz. Burada ben modele 30 etiket vermesini söyledim ve 5 iterasyonda kendini en iyi şekilde eğitmesini söyledim. Verinin ilk 8 çıktısı aşağıda gördüğünüz gibi.
from sklearn.decomposition import LatentDirichletAllocation as LDA
from sklearn.feature_extraction.text import CountVectorizer
#denetimsiz olarak modeli tahmin etmek için countvectorizer ile train verisini sayısal hale getiriyoruz.
tf_vectorizer = CountVectorizer(max_df=0.95, min_df=2, max_features=10000)
tf = tf_vectorizer.fit_transform(dataDoc)
tf_feature_names = tf_vectorizer.get_feature_names()
#modelin oluşturulması
lda = LDA(n_components=30, max_iter=5, learning_method='online', learning_offset=50.,random_state=0).fit(tf)
def display_topics(model, feature_names, no_top_words):
for topic_idx, topic in enumerate(model.components_):
print("Topic %d:" % (topic_idx))
print(" ".join([feature_names[i]
for i in topic.argsort()[:-no_top_words - 1:-1]]))
display_topics(lda,tf_feature_names,30)Topic 0:
bir küçük şekilde on iki talyan türü spor ilgili japon olur dizi kız amacıyla yerel idi filmidir oyuncusudur familyasından adam adında yahudi dizisi komedi verdiği kullanılır kitap çocuğu tamamen şeklinde
Topic 1:
nın dünya nda kupası savaşı ii yapılan sırasında kazandı gün pek şampiyonası doğru 1992 yaz nı fifa olimpiyatları yunanistan kinci karşı azerbaycan şampiyon madalya kulüp brezilya oyunları doğusunda altın stadyumu
Topic 2:
birlikte ye alman ocak uzun kısa 12 de temsil geniş arkadaşı parti tan lı asıllı para aktör halen eşi macaristan doğan yu von kısmı kodu kasım yalnızca bulundu destek yıllar
Topic 3:
da de oldu ya yeni ilk almanya başladı nın olarak sonunda ulusal grup kişi kurulan talya başkenti sahibi yaşında londra amerikalı girdi başlayan hollanda şehrinde 1986 düzenlenen polonya 1984 2014
Topic 4:
tarafından ikinci yılında şarkı üzere 2004 albümü albüm olmak çıkan sahiptir isimli rock sıra 1996 albümün stüdyo yanı ev ndan sanatçı şarkısı iç güzel yayınlandı yarışması eurovision başta jackson 1991
Topic 5:
iki iyi devam roma rağmen cumhuriyeti rusya savaş geri yaklaşık erkek kadın ortaya profesyonel kalan mparatorluğu nin insanlar buna başlar akdeniz etmektedir olmuş person_name bile bilgi var adet hala yaş
Topic 6:
tarihinde yıl etti yi önce 10 ekim na ağustos nisan osmanlı mart ran olarak 25 30 tam mö rus grubun eyaleti 28 insan yanında bin 22 2009 kendisine devleti yardımcı
Topic 7:
yer arasında olarak aldı mayıs kabul aralık yılları görev haziran 2009 alır ın sırada almaktadır 100 yol 26 11 böylece edilir güneyinde 1970 bilinir video 27 yapmış tarihleri listesinde kudüsGelin modelimizin tahmin ettiği konuları görselleştirip bir de o şekilde bakalım.
import pyLDAvis.sklearn pyLDAvis.enable_notebook() panel = pyLDAvis.sklearn.prepare(lda,tf, tf_vectorizer, mds = 'tsne' )
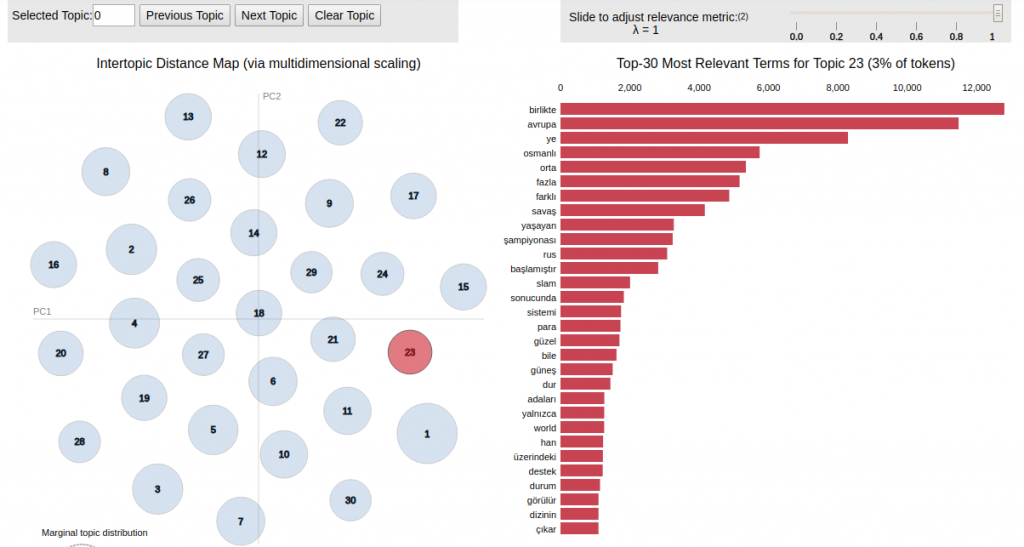
Görselleştirmedeki ilk parametremiz oluşturmuş olduğumuz model, ikinci ve üçüncü parametreler CountVektorizer ile oluşturduğumuz kelime matrisimiz ve dördüncü parametrede hangi yöntemle çizeceğimizi belirtiyoruz.
Gördüğünüz gibi tahmin edilen konuların içeriğinde hangi kelimelerin olduğunu ve konuların nasıl dağıldığını görebiliyoruz. Burada kodları ayrı ayrı atarak hem yazının okunabilirliğini düşürmek istemedim hem de toplu bir şekilde ulaşırsanız daha iyi olacağını düşündüm. Aşağıdaki github linkinden kodun tamamına erişebilirsiniz.
github : https://github.com/serkanars/turkishtopicmodeling
Bu yazımda sizlere Türkçe metinler üzerinde hem etiketli hem de etiketsiz olarak konu tahmini üzerine bilgiler aktarmaya çalıştım. Diğer yazıda görüşmek dileğiyle, veriyle kalın.
Kaynakça
* https://nlpforhackers.io/topic-modeling/
* https://towardsdatascience.com/latent-dirichlet-allocation-lda-9d1cd064ffa2
* https://stackoverflow.com/questions/42819460/what-is-the-difference-between-onevsrestclassifier-and-multioutputclassifier-in
* https://medium.com/hackernoon/presidential-debate-sentiment-analysis-with-lstm-onevsrest-linearsvc-nlp-step-by-step-guide-b9683e2c8ed9?source=extreme_sidebar———2-16———————-
merhaba serkan bey . Dokuz eylül üniversitesin istatistik bölümü öğrencisiyim. bir proje ödevi üzerinde çalışıyorum . pca , lda ve knn nin nasıl yorumlanması gerektiği hakkında bilgi edinmek istiyorum. yorumlama yaparken nelere dikkat etmem gerekiyor ? bu konuda yardımcı olabilirseniz çok sevinirim.