

![]()
Başlık çarpıcı geldi değil mi? İnanmazsınız ancak doğru. Spark işlerini genelde client kütüphanelerinin kurulu olduğu makinelerden, yani Spark’ın Hadoop’un nerede olduğundan haberdar ve konfigürasyonları yapılmış makinelerden, başlatırız. Bu durum bizim spark işini başlatma (spark-submit) konusunda client kütüphanelerine bağımlı kılar. İşte bu kısıttan kurtulmak için “Spark işlerini her yerden başlat (Submit Jobs from Anywhere)” sloganıyla bir Apache projesi başlatılmış. Projenin adı: Apache Livy. Apache Livy rest api kullanarak bizim Spark işi başlatmamızı sağlıyor. Üstelik hem batch iş başlatabiliyoruz hem de interaktif shell işi başlatabiliyoruz. Biliyorsunuz veri bilimi ve veri analizi personeli Zeppelin ve Jupyter gibi notebookları yaygın olarak kullanılıyor.
Bu yazımızda Apache Livy Server kurulumu, temel konfigürasyonu ve YARN üzerinde örnek bir Spark uygulaması başlatmayı öğreneceğiz.
Apache Livy Mimarisi
Livy mimarisi aşağıdaki gibidir. Görsel Livy’nin resmi sitesinden alınmıştır.

Yukarıda Şekil-1’de gördüğümüz gibi aslında Livy Server client ile Spark arasında giriyor ve oradan oraya al gülüm ver gülüm modunda çalışıyor.
Apache Livy’nin sağladığı bazı faydalar
- Farklı notebooklar arasında aynı SparkContex’e erişim sağlar.
- Daha etkin kaynak kullanımı. Kaynakları sonsuza dek tutmaz.
- User impersonation: İşi başlatan kullanıcı Spark işinin kullanıcısı olur.
- Spark’ı yarn-cluster mode kullanmaya olanak verir.
Kurulum, Konfigürasyon ve Uygulama
Ortam Bilgileri
Spark: 3.0.0
Livy: 0.7.1
Java: 1.8.0
Hadoop: 3.1.2
İşletim Sistemi: CentOS7
Yukarıda paylaştığım bilgiler benim bu çalışmayı yaptığım anda sahip olduğum ortam bilgileridir. Aynı uygulamayı yapmak için aynı ortam ve sürümleri kullanmak zorunlu değildir.
Apache Livy Kurulumu
Download
wget https://ftp.itu.edu.tr/Mirror/Apache/incubator/livy/0.7.1-incubating/apache-livy-0.7.1-incubating-bin.zip
Unzip
unzip apache-livy-0.7.1-incubating-bin.zipSoft Link
ln -s apache-livy-0.7.1-incubating-bin livy
Apache Livy Konfigürasyon
Add environment
export LIVY_HOME=/opt/manual/livy/ export LIVY_CONF_DIR=/opt/manual/livy/conf/
Livy server binary dizinini PATH’e ekleyelim.
export PATH="$PATH:/opt/manual/livy/bin"
Şimdi template olan konfigürasyon dosyalarını kopyalayarak ve adını değiştirerek kullanılabilir hale getirelim.
cd /opt/manual/livy/conf/ cp livy.conf.template livy.conf cp livy-env.sh.template livy-env.sh
livy.conf içinde livy.spark.master ‘ı yorumdan çıkartıp local yerine yarn yazalım
livy.spark.master = yarnApache Livy Server Başlatma
Hadoop YARN servisleri çalışıyorsa Livy Server başlayabilir.
livy-server start
Durumunu status ile öğrenebiliriz.
livy-server status Çıktı: livy-server is running (pid: 5761)
Apache Livy Server Web UI
Livy server web arayüzüne sahip. Bu arayüze varsayılan port 8889’dan ulaşabiliriz.

Yukarıdaki satırlar ben daha önceden deneme yaptığım için. Siz de muhtemelen ilk çalıştırdığınızda boş gelecektir.
Apache Livy Server üzerinden örnek Spark uygulaması başlatma
Bu linkte batch işi başlatma esnasında Livy POST isteğinde kullanılabilecek seçenekler var, ihtiyaca göre bunları kullanabilirsiniz. Ben aşağıda basit bir iş başlatacağım. Çalıştıracağım spark uygulaması:
from pyspark.sql import SparkSession
from pyspark.sql import SparkSession, functions as F
spark = SparkSession.builder \
.appName("Apache Livy Example") \
.getOrCreate()
df = spark.read.format("csv")\
.option("header", True) \
.option("inferSchema", True) \
.load("/user/train/datasets/Advertising.csv")
df2 = df.filter(F.col("Sales") > 20)
df2.show()
df2.write.format("csv"). \
mode("overwrite") \
.save("/user/train/advertising_gt_20")
Bu uygulama dosyasını hdfs’te /user/train/main.py adıyla taşıdım, main.py adı şart değil başka bir isim de olur.
Şimdi başlatıyorum.
curl -X POST \
--data '{"file": "/user/train/main.py", "proxyUser":"abuzittin","name":"My Livy Example Session"}' \
-H "Content-Type: application/json" \
192.168.206.130:8998/batchesBaşlattıktan sonra Livy web arayüzüne gidip bakalım.
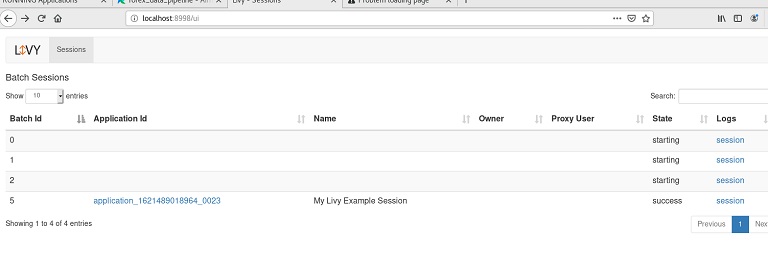
Burada application_xxxxxx linkine tıkladığımızda bizi önce YARN resource manager ara yüzüne, orada Application master linkine tıkladığımızda ise spark uygulama arayüzüne yönlendirecektir.
Uygulama sonuçlarını bir görelim hdfs’e yazmış mı?
hdfs dfs -ls /user/train/advertising_gt_20 Çıktı: Found 2 items -rw-r--r-- 1 train supergroup 0 2021-05-21 09:55 /user/train/advertising_gt_20/_SUCCESS -rw-r--r-- 1 train supergroup 752 2021-05-21 09:55 /user/train/advertising_gt_20/part-00000-96c03902-f725-4196-8be2-1062ad4e417a-c000.csv hdfs dfs -head /user/train/advertising_gt_20/part-00000-96c03902-f725-4196-8be2-1062ad4e417a-c000.csv Çıktı 1,230.1,37.8,69.2,22.1 16,195.4,47.7,52.9,22.4 18,281.4,39.6,55.8,24.4 31,292.9,28.3,43.2,21.4 37,266.9,43.8,5.0,25.4 40,228.0,37.7,32.0,21.5 43,293.6,27.7,1.8,20.7 48,239.9,41.5,18.5,23.2 53,216.4,41.7,39.6,22.6 54,182.6,46.2,58.7,21.2
Yukarıda gördüğümüz gibi satış değeri 20’den büyük olanları hedef dizin olan /user/train/advertising_gt_20 yazmış.
Peki ya cep telefonu?
Başlıkta dikkatimizi çektiniz hani nerede cep telefonundan başlatma işi? Arkadaşlar http isteği gönderebildiğiniz her yerde artık spark işi başlatabilirsiniz, yeter ki Livy server’a cep telefonunuzun ağ bağlantısı olsun.
Başka bir yazıda görüşmek dileğiyle…
Kapak: Reinhart Julian on Unsplash