

![]()
Bu yazımda 2019 başlarında ilk commiti yapılmış benim henüz farkedip test etme imkanım olan bir Python kütüphanesinden bahsedeceğim. Daha önce Python veya Knime ile eğittiğim modelleri farklı dillerde -mesela Java- kullanmak için o dilde pmml dosyasını okuyup sonuç üretecek bir kütüphane olmasını bekliyordum. Mesela Java için bu iş pmml4s ile kolaylıkla yapılıyorken. Golang için bulduğum en iyi kütüphane olan goscore sadece 4 farklı algoritmayı destekliyor -mesela svc desteklemiyor-. Bu konu üzerinde alternatifler ararken çok fakrlı bir alternatif olan m2cgen kütüphanesiyle karşılaştım.
m2cgen – Model To Code Generator
Bu kütüphane önceden kullandığım yöntemin aksine tekrar tekrar, farklı dillerde kullanılabilecek bir model değil de istenen dilde doğrudan tahmini yapan native bir kod çıkartıyor. Bu yazıyı yazmadan önce yeteri kadar test ettiğimi düşünüyorum ve sonuç olarak hatasız çalıştığını düşünüyorum ama yine de kullanmadan önce dikkatlice test etmenizi tavsiye ederim. Gördüğüm kadarıyla tek dezavantajı çıkardığı kodun büyüklüğü, çünkü tamamen native yani herhangi bir kütüphaneye bağımlı olmayan kodlar üretiyor ve lineer regresyonda kısa bir kod çıkarırken random forest gibi bir algoritma için çıkaracağı kodun büyüklüğünü tahmin edebilirsiniz. Verdiği çıktının tamamen native olmasının tabi avantajları da var. 7 farklı programlama dilinde yazılmış uygulamalarınıza (Java, C, Python, Go, JavaScript, Visual Basic, C#) kolayca entegre edebilirsiniz hem de hiç bir kütüphaneye ihtiyaç duymadan.
Desteklenen Algoritmalar
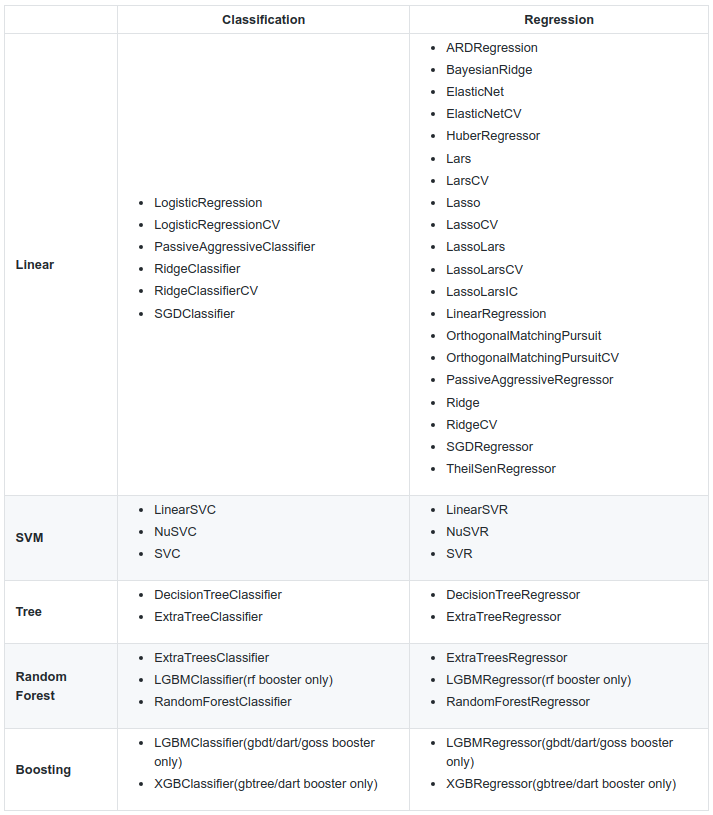
İhtiyaca göre hayat kurtarabilecek bu kütüphanenin kullanımı da oldukça basit. İsterseniz bunu örnekleriyle göstereyim:
Örnekler (Scikit-Learn –> Java, C, C#)
Python (Scikit-Learn) ile modelin eğitilmesi:
import numpy as np from sklearn.linear_model import LinearRegression import m2cgen as m2c # Eğitim verisinin tanımlanması X = np.array([[1, 1], [1, 2], [2, 2], [2, 3]]) y = np.dot(X, np.array([1, 2])) + 3 # Modelin eğitilmesi reg = LinearRegression().fit(X, y)
Eğitilen modelin Java koduna dönüştürülmesi:
# Eğitilen modelin Java koduna dönüştürülmesi code = m2c.export_to_java(reg) print(code)
Native Java kodu:
public class Model {
public static double score(double[] input) {
return ((3.0000000000000018) + ((input[0]) * (1.0000000000000002))) + ((input[1]) * (1.9999999999999991));
}
}Eğitilen modelin C koduna dönüştürülmesi:
# Eğitilen modelin C koduna dönüştürülmesi code = m2c.export_to_c(reg) print(code)
Native C kodu:
double score(double * input) {
return ((3.0000000000000018) + ((input[0]) * (1.0000000000000002))) + ((input[1]) * (1.9999999999999991));
}Eğitilen modelin C# koduna dönüştürülmesi:
# Eğitilen modelin C# koduna dönüştürülmesi code = m2c.export_to_c_sharp(reg) print(code)
Native C# kodu:
namespace ML {
public static class Model {
public static double Score(double[] input) {
return ((3.0000000000000018) + ((input[0]) * (1.0000000000000002))) + ((input[1]) * (1.9999999999999991));
}
}
}Bu yazımda yeni keşfettiğim ve mutlaka bir yerde işinize yarayabileceğini düşündüğüm bu kütüphaneyi tanıtmak istedim. Umarım gerçekten işinize yarar. Son olarak dezavantajını görebilmeniz için bir random forest örneği paylaşacağım:
Modelin oluşturulması:
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
import m2cgen as m2c
df = pd.DataFrame({
"a": [1,0,1,0,0,0,0,1,1,0,0,1,1],
"b": [1,0,0,0,0,1,1,1,1,0,0,1,0],
"c": ["a", "a", "a", "b", "b", "b", "a", "a", "a", "b", "b", "b", "a"]
})
X = df.drop(columns=["c"])
y = df.filter(["c"])
clf.fit(X, y)
code = m2c.export_to_java(clf)
print(code)Kod çok büyük olduğundan doğrudan burada görüntülenmesini istemedim. Bu bağlantıya giderek elde ettiğimiz native Java kodunu görüntüleyebilirsiniz.