

![]()
Herkese merhabalar,
Bu yazımda, “Riske Maruz Değer (Value at Risk – VaR) kavramı nedir? Bir portföyün, pozisyonun veya tek bir finansal varlığın risk ölçümü nasıl yapılır? Riske Maruz Değer kapsamında kullanılan istatistiksel yöntemler nelerdir?” gibi bir çok soruya cevap bulacağız.
Uygulamayı R programlama dilinde yapacağız. #banvt ve #nthol hisse senedi fiyatlarına ait milisaniye cinsinden veriler ile çalışacağız.
Value at Risk nedir?
Riske Maruz Değer (VaR), belirli bir zaman dilimi boyunca bir firma, portföy veya pozisyondaki finansal risk seviyesini ölçen ve nicelendiren bir istatistiktir. Bu metrik, en çok yatırım bankaları ve ticari bankalar tarafından kurumsal portföylerindeki potansiyel zararların kapsamını ve gerçekleşme oranını belirlemek için kullanılır.
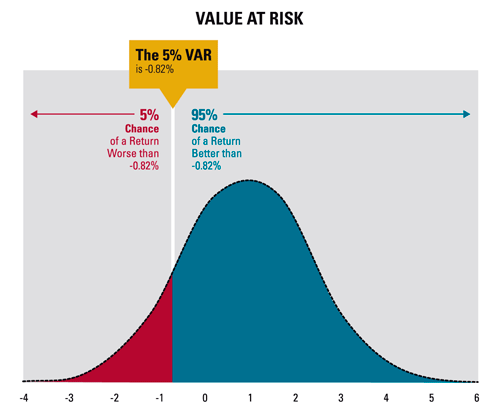
Yukarıdaki grafiğe göre, Value at Risk araştırması yapılan bir veri setinde, VaR değeri %95 güvenle -0.0082’dir. Yani VaR değeri, bir sonraki periyot %5 hata payı ile 0.0082 birimden daha fazla kaybetmeyeceğimi söylemektedir. Burada hesaplanan güven aralığı tek yönlüdür ve VaR değeri her zaman negatiftir.
VaR hesaplamalarında kullanılan yöntemler nelerdir?
Veri setinin dağılımı, kullanılan yöntemlerin etkin çalışabilmesi ve doğru sonuç verebilmesi için çok önemlidir. Aşağıda kullanılan yöntemler listelenmiştir;
– Parametrik VaR
– Tarihsel VaR
– Monte Carlo Simülasyonu
– Üssel Hareketli Ortalama Yöntemi
Bu kavramları bir sonraki bölümlerde uygulamalar ile açıklayacağım.
Not: Uygulama sadece 30 dakikalık veriler ile yapılmıştır, diğer veri setleri üzerindeki işlemleri github üzerinden inceleyebilirsiniz.
Uygulama
Veri Seti
Aşağıda görüldüğü üzere veri seti milisaniye cinsinden kapanış ve hacim değerlerini içermektedir. Bu yazı kapsamında hacim verisini kullanmayacağız fakat işlem hacminin fiyat üzerindeki etkisi araştırılması ve ölçülmesi gereken bir konudur.
Ek olarak veri seti 2020.02.11 tarihi ile 2020-05-08 tarihleri arasındadır. Yani covid-19 hastalığının Türkiye’de ilk olarak görüldüğü 2020.03.11 tarihi bu veri setinde mevcuttur.
readxl::read_xlsx("stocks202005111746b.xlsx", sheet = "banvt") %>%
arrange(Timestamp) %>%
mutate(symbol = "banvt",
Timestamp = format(as.POSIXct(Timestamp),
format = "%Y-%m-%d %H:%M:%OS3")) %>%
head()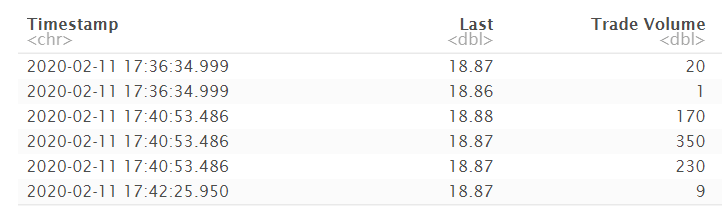
Zaman Manipülasyonu İşlemleri
Veri setini tek bir zaman boyutunda incelemek, yaptığımız VaR araştırması için doğru değildir. VaR modelinin en çok günlük verilerde doğru sonuç verdiği bilinmektedir ancak farklı zaman aralıklarında da araştırma yapmak mümkündür. Çalışmada 1, 15, 30 dakikalık ve 1 günlük skalada veri manipülasyonu işlemleri yapılmıştır.
banvt_1m <- cbind(to.minutes(banvt_xts),rowMeans(to.minutes(banvt_xts)[,2:3]))[,5]
banvt_15m <- cbind(to.minutes15(banvt_xts),rowMeans(to.minutes15(banvt_xts)[,2:3]))[,5]
banvt_30m <- cbind(to.minutes30(banvt_xts),rowMeans(to.minutes30(banvt_xts)[,2:3]))[,5]R’da xts paketini kullanarak to.minutes() fonksiyonu ile kolaylıkla zaman dönüştürme işlemleri yapabilirsiniz. Veriyi 30 dakikalık olarak çevirince oluşan veri seti aşağıdaki gibidir. Fonksiyon, ilk olarak verideki ilk tarihi baz alarak önündeki 30 dakikaya giriş fiyatını, en yüksek ve en düşük fiyatları ve son olarak başlangıçtan itibaren 30. dakikadan çıkış fiyatını göstermektedir.
Burada verideki oynaklığı da hesaba katmak için en yüksek ve en düşük değerlerin ortalamalarını alarak 30 dakikalık veri seti oluşturulmuştur.

Zaman Senkronizasyonu İşlemi
Veri setinde, #banvt ve #nthol veri setleri arasında 7 dakikalık bir fark vardır. Ek olarak veri seti milisaniyelik cinsten olduğu için işlemlerin aynı anda gerçekleşme olasılığı çok düşük olacağından dolayı iki veri setini birleştirmek aslında kendi içerisinde çoklanmış bir veri seti oluşturmak anlamına gelmektedir. Aşağıda 30 dakikalık zaman aralığında zaman senkronizasyonu uygulayan kodu inceleyelim;
default_data_30 <- merge.xts(banvt = banvt_30m, nthol = nthol_30m, all = TRUE)
xts_wo_30 <- na.locf(default_data_30, fromLast=TRUE) %>% na.exclude() %>%
`colnames<-`(c("banvt", "nthol"))- merge.xts() fonksiyonu ile 30 dakikalık iki hisse senedine ait veri setlerini birleştirdik. Ek olarak “all = TRUE” parametresi ile gözlem kaybetmeden iki veri kümesini birleştirmiş olduk.
- Veri setinde çok fazla NA değer oluşacağından bu değerleri na.locf() fonksiyonunu kullanarak “fromLast = TRUE” parametresi ile eksik değerleri üstte bulunan dolu ilk gözlem ile doldurmuş olduk.
Getiri Hesaplama İşlemleri
Son manipülasyon işlemi olarak, oluşturulmuş farklı zaman aralıklarındaki veri setleri üzerinden getiri hesaplama işlemi yapacağız.
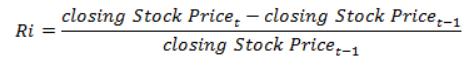
Yukarıdaki formül ile getiri hesaplamak mümkündür. Ek olarak literatürde hesaplanan getirilerin logaritması alınarak da Value at Risk araştırması yapılmıştır. R’da ROC() fonksiyonunu kullanarak getiri hesaplaması yapmak mümkündür.
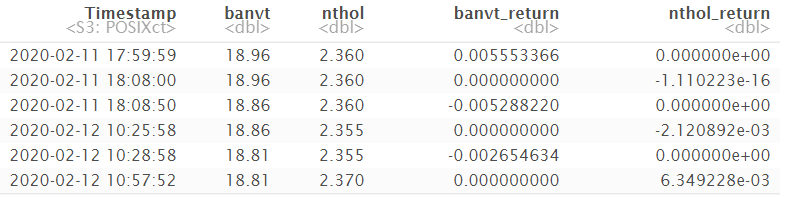
tbl_30 %<>% mutate(banvt_return = ROC(banvt),
nthol_return = ROC(nthol)) %>% na.exclude()Sonuç olarak gerekli manipülasyon işlemlerinden sonra oluşan yeni veri seti aşağıdaki gibidir. 30 dakikalık skalada 2065 gözlem, 15 dakikalık skalada 3995 gözlem, 1 dakikalık skalada ise 46852 gözlem ve son olarak günlük skalada isen 51 gözlemli veri setleri oluşturulmuştur.
Parametrik VaR
Veri setinin dağılımının normal olduğu varsayılmaktadır. Verinin ortalaması ve standart sapması ile işlem yapıldığından normal dağılıma sahip verilerde tutarlı sonuçlar vermektedir.
alpha_ <- 0.05
z <- qnorm(alpha_)
mean_dr_banvt <- mean(tbl_30 %>% pull(banvt_return))
mean_dr_nthol <- mean(tbl_30 %>% pull(nthol_return))
sd_dr_banvt <- sd(tbl_30 %>% pull(banvt_return))
sd_dr_nthol <- sd(tbl_30 %>% pull(nthol_return))
parametric_var_banvt <- -mean_dr_banvt + z*sd_dr_banvt
parametric_var_nthol <- -mean_dr_nthol + z*sd_dr_nthol
tibble(Parametric_banvt = parametric_var_banvt,
Parametric_nthol = parametric_var_nthol)Getirilerin ortalamaları ve standart sapmaları hesaplanır ve güven aralığının alt sınırı hesaplanır. Bu alt sınıra karşılık gelen değer %95 güvenle hesaplanan VaR değeridir. Aşağıdaki tablo, #banvt hissesinin 0.0153, #nthol hissesinin ise 0.0126’dan fazla kaybetmeme olasılığının %95 olduğunu göstermektedir.

Tarihsel VaR
Parametrik VaR verinin ortalaması ve standart sapmasını hesaplayarak bir güven aralığı üzerinden hesaplama yapar. Tarihsel VaR ise verinin belirlenen alpha düzeyine göre karşılık gelen yüzdelik dilimidir. Aşağıda quantile() fonksiyonuna parametre olarak verilen 0.05 alpha_ değeri, verinin sıralandıktan sonra ilk %5’ini kapsayan değeri hesaplar.
historical_var_banvt <- quantile(tbl_30 %>% pull(banvt_return), alpha_)
historical_var_nthol <- quantile(tbl_30 %>% pull(nthol_return), alpha_)
tibble(historical_banvt = historical_var_banvt,
historical_nthol = historical_var_nthol) %>% kable()Aşağıdaki tablo, #banvt hissesinin 0.0087, #nthol hissesinin ise 0.0086’dan fazla kaybetmeme olasılığının %95 olduğunu göstermektedir.

Monte Carlo Simülasyonu Metodu
Monte carlo simülasyonu, bir veri setinin dağılımının bilindiği durumlarda çok etkili bir yöntem olarak bilinir. Bu bölümde, getirilerin normal dağıldığı varsayımı altında 1000 defa tekrarlanan bir Monte Carlo simülasyonu oluşturulmuştur. Ek olarak çeşitli empirik yöntemler ile verinin dağılımı fonksiyonel olarak tahmin edilebilir ve monte carlo simülasyonu bu dağılım üzerinden uygulanabilir.
mean_dr_banvt <- tbl_30 %>% pull(banvt_return) %>% mean()
mean_dr_nthol <- tbl_30 %>% pull(nthol_return) %>% mean()
calculate_one_period_change <- function(mean, sd){-mean+sd*rnorm(1)}
simulated_returns_banvt <- replicate(1000,
calculate_one_period_change(mean = mean_dr_banvt,
sd = sd_dr_banvt))
simulated_returns_nthol <- replicate(1000,
calculate_one_period_change(mean = mean_dr_nthol,
sd = sd_dr_nthol))
mc_var_banvt <- quantile(simulated_returns_banvt, alpha_)
mc_var_nthol <- quantile(simulated_returns_nthol, alpha_)
tibble(mc_banvt = mc_var_banvt,
mc_nthol = mc_var_nthol) %>% kable()Kodlara bakıldığında aslında Parametrik VaR yöntemi ile Tarihsel VaR yönteminin birleştirilmiş hali olarak görülebilir. Ancak verinin dağılımı normal dağılımdan farklı bir dağılım olduğunda yöntem yapısal olarak değişecektir. Monte Carlo Simülasyonu replicate() fonksiyonu ile, belirtilen dağılıma göre 1000 kez tekrar ettirilmiş ve bir veri seti oluşturulmuştur. Oluşan veri setinin alpha_ düzeyine göre yüzdeliğine karşılık gelen değer monte carlo simülasyonu ile hesaplanan VaR değeridir.
Aşağıdaki tablo, #banvt hissesinin 0.0151, #nthol hissesinin ise 0.0119’dan fazla kaybetmeme olasılığının %95 olduğunu göstermektedir.

Üssel Hareketli Ortalama Yöntemi
Bu bölüme kadar veriler üzerinde herhangi bir ağırlıklandırma yapmadan direk olarak verinin dağılımı üzerinden işlemler yaptık. Ancak hisse senedi verilerine bir bütün olarak yaklaşmak bazı durumlarda hatalı veya yanlı sonuçlar doğurabilir.
Uzun vadede tüm varlık fiyatları artma eğilimindedir ancak kısa vadede fiyatı oluşturan birçok etken vardır. Herhangi bir risk durumunda ilk olarak finansal piyasalar etkilenmektedir. Piyasalar, riskin türüne ve büyüklüğüne göre anlık olarak fiyatlanır. Dolayısıyla bir hisse senedi verisine baktığımızda, aslında son günlerdeki gelişmeler fiyat üzerinde daha çok etkilidir. Bu noktada Üssel Hareketli Ortalama Yöntemi, veri seti üzerinde lambda parametresi ile ağırlıklandırma işlemi yaparak son günlere daha çok ağırlık verirken, günler arttıkça gözlemlerin fiyat üzerindeki etkisini azaltılmış olur. Şimdi adımları sırasıyla inceleyelim;
1- Eşit Ağırlıklı Tarihsel Veri Seti
Öncelikle normal ağırlıklandırılmış veri seti oluşturulur. Burada Periods_30 değişkeni 30 dakikalık veri setini gün bazında temsil etmektedir. Getiriler küçükten büyüğe sıralanır ve her bir gözlem eşit ağırlığa sahip olacak şekilde yeni bir ağırlıklandırma değişkeni oluşturulur. Son olarak belirtilen alpha düzeyine göre VaR değerini gözlemlemek için ağırlıkların kümülatif toplamları hesaplanır.
basic_histor_banvt <- tbl_30 %>% select(banvt, banvt_return) %>%
mutate(Periods_30 = 1:nrow(tbl_30)) %>%
arrange(banvt_return) %>%
mutate(eq_weights = 1/nrow(tbl_30),
cum_eq_weigths = cumsum(eq_weights))

Yukarıdaki tabloda görüldüğü üzere cum_eq_weights değişkeni hesaplanan kümülatif ağırlıkları temsil etmektedir. Bu değişkende %5 önem düzeyine karşılık gelen banvt_return değeri, eşit ağırlıklandırma yöntemi ile hesaplanmış VaR değerini temsil etmektedir.
2- Ağırlıklandırılmış Tarihsel Veri Seti
Yukarıda oluşturulan basic_histor_banvt değişkeni üzerine, belirtilen lambda ağırlık parametresi ile hesaplanan ağırlıklandırılmış değişkenler eklenmiştir. Aşağıdaki formül ile lambda parametresini kullanarak ağırlandırma işlemi yapılmıştır.

lambda: Ağırlıklandırma parametresi
i: İlgili gözlemin periyot değeri
n: Gözlem sayısı
basic_histor_banvt %>%
mutate(hybrid_weights = ((1-lambda)*(lambda^(Periods_30-1)))/(1-lambda^k),
hybrid_cum_weights = cumsum(hybrid_weights)) Formül uygulandığında veri setindeki her bir Periods_30 değerinin ağırlıkları hesaplanmış olur. Aşağıdaki tabloda görüldüğü üzere hybrid_weights değişkeni Periods_30 değerlerinin küçük değerlerine daha çok ağırlık verirken, uzak değerlerine daha düşük ağırlık vermiştir.

Burada problem, elde edilen hybrid_cum_weights değişkenine göre 0.05 anlam düzeyini yakalayıp bu değere karşılık gelen return değerini bulmanın zorluğudur. Bunun için de istatistikte yaygın olarak kullanılan interpolasyon işlemi uygulanmıştır.
3- İnterpolasyon İşlemi
R’da approx() fonksiyonu ile bir değişkenin olasılıksal olarak karşılığını bulmak mümkündür.
ewh_var_banvt <- approx(x =ewh_banvt$hybrid_cum_weights,
y = ewh_banvt$banvt_return,
xout=alpha_)$yÜssel Hareketli Ortalama Yöntemi’ni kullanarak elde edilen sonuçlar aşağıdaki gibidir.

Sonuç
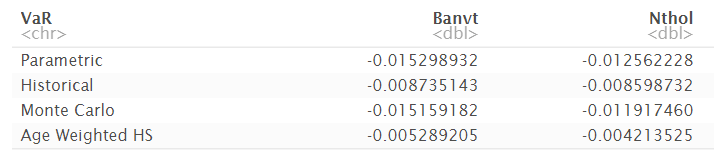
Sonuç olarak, çeşitli istatistiksel yöntemler ile VaR değerleri hesaplamış olduk. Burada hangi yöntemin uygun olduğuna karar vermek için çeşitli yöntemler vardır.
İki bölümden oluşacak bu yazı dizisinin diğer bölümünde “sliding” işlemi uygulanarak veri setini parçalara ayırıp backtest yöntemleri uygulayacağız. Uygulamada 1, 15, 30 dakikalık verilerde hangi yöntemin daha iyi olduğunu, günlük bazda uygulandığında (ki ideal uygulama biçimi bu şekildedir) hangi yöntemin daha uygun olduğunu göstereceğiz.
Şimdilik hoşcakalın.
Versiyon bilgileri: R version 4.0.2
IDE: RStudio
Mustafa Bey çalışma için çok teşekkür ederim. Yeni R eğitimi almış olan bir bankacıyım. Veriyi BİST sitesinde bulamadım acaba paylaşmanız mümkün mü?
Çok teşekkürler iyi çalışmalar