

![]()
Başlatmış olduğum “Lanet Veriler” serisinin ikinci yazısına hoş geldiniz. Bu yazıda lanet olası federallerin canlarına okumaya çalışacağız!
FBI Verisi
Amerika Birleşik Devletleri Bölgelerinde Suç, Coğrafi Bölüm ve Eyalet, 2015–2016
Veri Seti: https://ucr.fbi.gov/crime-in-the-u.s/2016/crime-in-the-u.s.-2016/topic-pages/tables/table-2
Açıklamalar
Bir veri ile işlem yapmadan önce mutlaka o verinin ne olduğunu, neyi ifade ettiğini anlamaya çalışalım! İnternet sitesindeki bazı açıklamaları veriyi anlamak için yazalım.
- Population (Popülasyon) değişkeni ABD Nüfus Sayımı Bürosu tarafından 1 Temmuz 2016 itibariyle tahmin edilen nüfus rakamlarıdır.
- Şiddet içeren saldırı değişkenleri “Murder” (Cinayet), “Rape” (Tecavüz), “Robbery” (Soygun) ve “Aggravated Assault” (Ağır Saldırı) değişkenleridir. Diğer suç değişkenleri ise “Property Crime” (Mülkiyet Suçları), “Burglary” (Ev Soygunu), “Larceny-Theft” (Hırsızlık) ve “Motor Vehicle Theft” (Motorlu Araç Hırsızlığı) değişkenleridir.
- Her bir bölgede olan tahmini suç sayısını ve her bir bölgedeki suç oranını (100.000 kişi başına düşen suç), “Rate per 100,000” ile görüyoruz.
- Veri, Metro Transit Polisi ve Columbia İtfaiye ve Acil Sağlık Hizmetleri: Arson Soruşturma Birimi tarafından bildirilen suçları içerir.
Veriler hakkındaki tüm bilgileri bilmemiz ve anlamamız tüm işlemlerimizde bize yardımcı olacaktır. Ayrıca internet sitesinde “Overview” kısmında ise veri üzerinde elde edilen bulgulardan bahsedilmiş. Bunlara da bir göz atmanız sizin için yararlı olacaktır.
Veri açıklaması: https://ucr.fbi.gov/crime-in-the-u.s/2016/crime-in-the-u.s.-2016/tables/table-2/table-2.xls/@@template-layout-view?override-view=data-declaration
Veri içerisinde dikkat etmemiz gereken ise veri hem ABD toplamını, hem Bölgeler toplamını hem de Eyaletleri içermektedir.
- Amerika toplamı: United States Total6, 7, 8, 9
- Bölgeler (Region): Northeast6 / Midwest6 / South6, 7, 8 / West6
- Eyaletler
Dikkat etmemiz gereken bir diğer nokta değişkenlerin, bölgelerin ve eyaletlerin yanında 1,2,3,4,5,6,7,8,9 sayıları mevcut. Bu sayılar internet sitesinde ve verinin en aşağısında gözüken açıklamalardır.
Kütüphaneler
library(dplyr) library(tidyr) library(stringr) library(readxl)
Verinin Yüklenmesi
FBI verisini iki kere yükledim, elimde bir adet ham verinin durmasını istiyorum.
fbi_ham <- read_excel("fbi.xls")
fbi <- read_excel("fbi.xls")
Manipülasyona başlamadan önce daha önce yazmış olduğum “R ile Veri Manipülasyonu Sersi” ve “Uygulama” yazılarımdaki prensiplere bağlı kalarak işlemleri gerçekleştireceğim.
R ile Veri Manpülasyonu: https://veribilimiokulu.com/r-ile-veri-manipulasyonu-bolum-1/ Uygulama: https://veribilimiokulu.com/r-ile-veri-manipulasyonu-uygulama/
Veri manipülasyonu için üç aşamayı takip edeceğiz.
- Ham verileri keşfetmek
- Düzenli veri formatı – Tidy data
- Veriyi analizler için hazırlamak
İlk olarak ham veriyi keşfetmemiz gerekiyor.
- Verinin yapısını anlamak,
- Veriyi gözlemlemek,
- Görselleştirme yapmak.
İkinci aşamamız ise düzenli veri prensiplerini uygulamak olacaktır.
Düzenli Veri Prensipleri: – Gözlemler satır olmalıdır, – Değişkenler satır olmalıdır ve – Tablo başına gözlem birimi bir tür olmalıdır.
Üçüncü aşamamız ise veriyi analizler için hazırlayacağız.
- Tarih formatı
- Değişken dönüşümleri
- Eksik, Aykırı ve Beklenmeyen Gözlemler.
Operasyon Başlasın!
Verinin yapısını anlamak için str veya dplyr kütüphanesinden glimpse fonksiyonları kullanılabilir.
str(fbi_ham)
## Classes 'tbl_df', 'tbl' and 'data.frame': 213 obs. of 23 variables: ## $ Table 2: chr "Crime in the United States1" "by Region, Geographic Division, and State, 2015–2016" "Area" NA ... ## $ X__1 : chr NA NA "Year" NA ... ## $ X__2 : chr NA NA "Population2" NA ... ## $ X__3 : chr NA NA "Violent crime3" NA ... ## $ X__4 : chr NA NA NA "Rate per \n100,000" ... ## $ X__5 : chr NA NA "Murder and \nnonnegligent \nmanslaughter" NA ... ## $ X__6 : chr NA NA NA "Rate per \n100,000" ... ## $ X__7 : chr NA NA "Rape\n(revised definition)4" NA ... ## $ X__8 : chr NA NA NA "Rate per \n100,000" ... ## $ X__9 : chr NA NA "Rape\n(legacy definition)5" NA ... ## $ X__10 : chr NA NA NA "Rate per \n100,000" ... ## $ X__11 : chr NA NA "Robbery" NA ... ## $ X__12 : chr NA NA NA "Rate per \n100,000" ... ## $ X__13 : chr NA NA "Aggravated assault" NA ... ## $ X__14 : chr NA NA NA "Rate per \n100,000" ... ## $ X__15 : chr NA NA "Property crime" NA ... ## $ X__16 : chr NA NA NA "Rate per \n100,000" ... ## $ X__17 : chr NA NA "Burglary" NA ... ## $ X__18 : chr NA NA NA "Rate per \n100,000" ... ## $ X__19 : chr NA NA "Larceny-theft" NA ... ## $ X__20 : chr NA NA NA "Rate per \n100,000" ... ## $ X__21 : chr NA NA "Motor vehicle theft" NA ... ## $ X__22 : chr NA NA NA "Rate per \n100,000" ...
veya
glimpse(fbi_ham)
## Observations: 213 ## Variables: 23 ## $ `Table 2` <chr> "Crime in the United States1", "by Region, Geographi... ## $ X__1 <chr> NA, NA, "Year", NA, "2015", "2016", "Percent change"... ## $ X__2 <chr> NA, NA, "Population2", NA, "320896618", "323127513",... ## $ X__3 <chr> NA, NA, "Violent crime3", NA, "1234183", "1283058", ... ## $ X__4 <chr> NA, NA, NA, "Rate per \n100,000", "384.6000000000000... ## $ X__5 <chr> NA, NA, "Murder and \nnonnegligent \nmanslaughter", ... ## $ X__6 <chr> NA, NA, NA, "Rate per \n100,000", "4.900000000000000... ## $ X__7 <chr> NA, NA, "Rape\n(revised definition)4", NA, "126134",... ## $ X__8 <chr> NA, NA, NA, "Rate per \n100,000", "39.29999999999999... ## $ X__9 <chr> NA, NA, "Rape\n(legacy definition)5", NA, "91261", "... ## $ X__10 <chr> NA, NA, NA, "Rate per \n100,000", "28.39999999999999... ## $ X__11 <chr> NA, NA, "Robbery", NA, "328109", "332198", "1.2", "5... ## $ X__12 <chr> NA, NA, NA, "Rate per \n100,000", "102.2", "102.8", ... ## $ X__13 <chr> NA, NA, "Aggravated assault", NA, "764057", "803007"... ## $ X__14 <chr> NA, NA, NA, "Rate per \n100,000", "238.0999999999999... ## $ X__15 <chr> NA, NA, "Property crime", NA, "8024115", "7919035", ... ## $ X__16 <chr> NA, NA, NA, "Rate per \n100,000", "2500.5", "2450.69... ## $ X__17 <chr> NA, NA, "Burglary", NA, "1587564", "1515096", "-4.59... ## $ X__18 <chr> NA, NA, NA, "Rate per \n100,000", "494.6999999999999... ## $ X__19 <chr> NA, NA, "Larceny-theft", NA, "5723488", "5638455", "... ## $ X__20 <chr> NA, NA, NA, "Rate per \n100,000", "1783.599999999999... ## $ X__21 <chr> NA, NA, "Motor vehicle theft", NA, "713063", "765484... ## $ X__22 <chr> NA, NA, NA, "Rate per \n100,000", "222.1999999999999...
- FBI verimiz ham halde 213 gözleme ve 23 değişkene sahip yani 213×23 boyutunda.
- Değişken türlerimizin hepsi karakter formatında.
- Değişken isimlerinin ne olduğu belli değil.
- Tüm değişkenlerde eksik gözlemler olduğu görülüyor.
Hızlı bir göz atmak için verinin ilk ve son altı gözlemlerine bakalım.
head(fbi_ham)
## # A tibble: 6 x 23 ## `Table 2` X__1 X__2 X__3 X__4 X__5 X__6 X__7 X__8 X__9 X__10 ## <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> ## 1 Crime in ~ <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> ## 2 by Region~ <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> ## 3 Area Year Popul~ Viole~ <NA> "Mur~ <NA> "Rap~ <NA> "Rap~ <NA> ## 4 <NA> <NA> <NA> <NA> "Rat~ <NA> "Rat~ <NA> "Rat~ <NA> "Rat~ ## 5 United St~ 2015 32089~ 12341~ 384.~ 15883 4.90~ 1261~ 39.2~ 91261 28.3~ ## 6 <NA> 2016 32312~ 12830~ 397.~ 17250 5.29~ 1306~ 40.3~ 95730 29.6~ ## # ... with 12 more variables: X__11 <chr>, X__12 <chr>, X__13 <chr>, ## # X__14 <chr>, X__15 <chr>, X__16 <chr>, X__17 <chr>, X__18 <chr>, ## # X__19 <chr>, X__20 <chr>, X__21 <chr>, X__22 <chr>

tail(fbi_ham)
## # A tibble: 6 x 23 ## `Table 2` X__1 X__2 X__3 X__4 X__5 X__6 X__7 X__8 X__9 X__10 ## <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> ## 1 6 Agencies ~ <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> ## 2 7 Includes ~ <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> ## 3 8 This stat~ <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> ## 4 9 The figur~ <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> ## 5 * Less than~ <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> ## 6 NOTE: Alth~ <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> ## # ... with 12 more variables: X__11 <chr>, X__12 <chr>, X__13 <chr>, ## # X__14 <chr>, X__15 <chr>, X__16 <chr>, X__17 <chr>, X__18 <chr>, ## # X__19 <chr>, X__20 <chr>, X__21 <chr>, X__22 <chr>
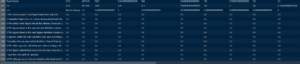
Veriye baktığımızda değişken isimlerinin 3. satırda yani gözlemde olduğunu görüyoruz. Ayrıca Excel üzerine hücre birlştirmeleri yapıldığından 100.000 kişi başına düşen suç oranı değişkenleri de 4. satırda yer almaktadır. Verinin en altına baktığımızda açıklamaların da veriye dahil olduğunu görüyoruz.
İlk iki satırın ve sondaki açıklamaları içeren satırların silinmesi.
fbi <- fbi_ham[ c(-1,-2,-203:-213) , ]
1. satırdaki değişken isimlerini değişken olarak tanımlayalım ve 1. satırı daha sonrasında silelim.
names(fbi) <- fbi[1,] fbi <- fbi[-1,]
4. satır da Rate Per 100.000 olarak ismi boş gözüken değişkenleri nitelendiriyor. Bu değişkenler 100.000 kişi başına düşen suç oranlarını gösteriyordu. Yani elimizdeki değişkenlerin “Population” değişkenlerin bölümüne ve 100.000 ile çarpımına eşit.
Bu yüzden ben bu uygulamada bu değişkenleri sileceğim. Eğer hesaplama yapmak isterseniz ya değişkenleri silmeyin ve isimlendirme yaptıktan sonra 4. satırı silin ya da sildikten sonra eğer ihtiyacınız varsa hesaplayıp analizler de kullanın. Bizim amacımız düzenli veri formatı elde etmek olduğundan bu şekilde bir silme işlemi yapmayı tercih edeceğim.
yuz_bin_kisi_basina_dusen_suc <- which(!is.na(fbi[1,])) fbi <- fbi[-1, -yuz_bin_kisi_basina_dusen_suc]
Şimdi de gözümüze “Area” değişkeni ve her 3 satırda bir tekrar eden “Percent Change” takılmıyor mu?
Area değişkeni içerisinde ABD toplam suç oranları, Bölgeler toplam suç oranları ve Eyaletler suç oranları var. Burada bölgeleri içeren gözlemleri çıkartalım ve bölgeleri temsil eden “Region” değişkenini oluşturalım.
Öncelikle Excelde hücre birleştirmesi yapılmış olduğundan Area değişkenindeki her bir dolu satır altında gelen iki satırı da temsil etmektedir. Bu yüzden aşağıdaki işlemi yapabiliriz.
fbi$Area[ c( which(!is.na(fbi$Area)) + 1, which(!is.na(fbi$Area)) + 2 ) ] <- fbi$Area[which(!is.na(fbi$Area))]
Şimdi FBI verisi 4 bölgelere ayrılmış. Bu bölgeler ve eyaletleri aşağıdaki gibidir.
Northeast
New England6, Connecticut, Maine, Massachusetts, New Hampshire, Rhode Island6, Vermont, Middle Atlantic6, New Jersey, New York6, Pennsylvania
Midwest
East North Central6, Illinois, Indiana6, Michigan, Ohio6, Wisconsin6, West North Central6, Iowa, Kansas, Minnesota, Missouri, Nebreska6, North Dakota, South Dakota6,
South
South Atlantic6, 7, 8, Delaware, District of Columbia7, Florida, Georgia8, Maryland, North Carolina6, South Carolina, Virginia, West Virginia, East South Central6, Alabama, Kentucky, Mississippi6, Tennessee, West South Central6, Arkansas, Louisiana, Oklahoma6, Texas
West
Mountain6, Arizona, Colorado, Idaho, Montana, Nevada, New Mexico6, Utah, Wyoming, Pacific6, Alaska, California, Hawaii, Oregon6, Washington6, Puerto Rico9
# Boş Region değişkeni oluşturalım.
fbi$Region <- NA
# Region değişkenini ilk değişken olarak aldık.
fbi <- fbi[c(14, 1:13)]
# 4 Bölge:
## Northeast,
fbi$Region[which(fbi$Area %in% c("New England6", "Connecticut", "Maine", "Massachusetts", "New Hampshire", "Rhode Island6", "Vermont", "Middle Atlantic6", "New Jersey", "New York6", "Pennsylvania"))] <- "Northeast"
## Midwest,
fbi$Region[which(fbi$Area %in% c("East North Central6", "Illinois", "Indiana6", "Michigan", "Ohio6", "Wisconsin6", "West North Central6", "Iowa", "Kansas", "Minnesota", "Missouri", "Nebreska6", "North Dakota", "South Dakota6"))] <- "Midwest"
## South,
fbi$Region[which(fbi$Area %in% c("South Atlantic6, 7, 8", "Delaware", "District of Columbia7", "Florida", "Georgia8", "Maryland", "North Carolina6", "South Carolina", "Virginia", "West Virginia", "East South Central6", "Alabama", "Kentucky", "Mississippi6", "Tennessee", "West South Central6", "Arkansas", "Louisiana", "Oklahoma6", "Texas"))] <- "South"
## West,
fbi$Region[which(fbi$Area %in% c("Mountain6", "Arizona", "Colorado", "Idaho", "Montana", "Nevada", "New Mexico6", "Utah", "Wyoming", "Pacific6", "Alaska", "California", "Hawaii", "Oregon6", "Washington6", "Puerto Rico9"))] <- "West"
# ve Amerika toplamını da Total olarak gösterelim.
fbi$Region[which(fbi$Area == "United States Total6, 7, 8, 9")] <- "Total"
Veriyi toplam, bölgeler ve eyalet olarak üçe bölelim.
fbi_total <- fbi %>% filter(Region == "Total")
fbi_region <- fbi %>% filter(Area %in% c("Northeast6", "Midwest6", "South6, 7 ,8", "West6"))
fbi_state <- fbi %>%
filter(Region != "Total", !is.na(Region))
Yüzdelik değişim de yıllar arasındaki değişim oranı olduğundan Percent change gözlemlerini de fbi_state verisinden çıkaralım.
# Yüzdelik Değişim fbi_percent_change <- fbi_state %>% filter(Year %in% "Percent change")
# Eyaletler verisi Bölgelere göre fbi_state <- fbi_state %>% filter(Year != "Percent change")
Tüm veriler karakter formatında ve açıklamalardan kaynaklı değişkenlerde ve gözlemlerde 1’den 9’a kadar numaralandırma işlemi yapılmıştı. Bu yüzden Area değişkenindeki bu numaralandırmaları kaldıralım. Bunu da stringr kütüphanesi ile kolaylıkla yapabiliriz.
library(stringr) fbi_state$Area <- str_remove_all(fbi_state$Area, ",") fbi_state$Area <- str_remove_all(fbi_state$Area, "6") fbi_state$Area <- str_remove_all(fbi_state$Area, "7") fbi_state$Area <- str_remove_all(fbi_state$Area, "8") fbi_state$Area <- str_remove_all(fbi_state$Area, "9")
Tüm değişkenlerimiz karakter formatındaydı. Ama verimizde birden fazla sayısal değişken bulunmakta. Bu değişkenleri nümerik hale getirelim.
fbi_state <- fbi_state %>% mutate_at(vars(Population2:`Motor vehicle theft` ),funs(as.numeric)) glimpse(fbi_state)
## Observations: 120 ## Variables: 14 ## $ Region <chr> "Northeast", "North... ## $ Area <chr> "New England", "New... ## $ Year <chr> "2015", "2016", "20... ## $ Population2 <dbl> 14710229, 14735525,... ## $ `Violent crime3` <dbl> 42121, 41598, 7938,... ## $ `Murder and \nnonnegligent \nmanslaughter` <dbl> 326, 292, 116, 78, ... ## $ `Rape\n(revised definition)4` <dbl> 4602, 4505, 798, 76... ## $ `Rape\n(legacy definition)5` <dbl> 3374, 3328, 585, 56... ## $ Robbery <dbl> 9629, 9407, 2925, 2... ## $ `Aggravated assault` <dbl> 27564, 27394, 4099,... ## $ `Property crime` <dbl> 257073, 243769, 656... ## $ Burglary <dbl> 46260, 42095, 10286... ## $ `Larceny-theft` <dbl> 193051, 182985, 488... ## $ `Motor vehicle theft` <dbl> 17762, 18689, 6426,...
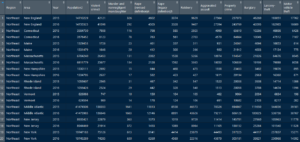
İstediğimiz formata getirdiğimize göre şimdi de özet istatistiklere göz atalım.
summary(fbi_state)
## Region Area Year ## Length:120 Length:120 Length:120 ## Class :character Class :character Class :character ## Mode :character Mode :character Mode :character ## ## ## Population2 Violent crime3 ## Min. : 585501 Min. : 747 ## 1st Qu.: 2683072 1st Qu.: 7864 ## Median : 5501194 Median : 20312 ## Mean :10759432 Mean : 41992 ## 3rd Qu.:11906836 3rd Qu.: 41627 ## Max. :63923309 Max. :258672 ## ## ## Murder and \nnonnegligent \nmanslaughter Rape\n(revised definition)4 ## Min. : 10.0 Min. : 150.0 ## 1st Qu.: 84.0 1st Qu.: 874.5 ## Median : 276.0 Median : 2038.0 ## Mean : 561.8 Mean : 4266.1 ## 3rd Qu.: 636.0 3rd Qu.: 4678.5 ## Max. :4077.0 Max. :22333.0 ## ## ## Rape\n(legacy definition)5 Robbery Aggravated assault ## Min. : 104.0 Min. : 59 Min. : 482 ## 1st Qu.: 632.2 1st Qu.: 1638 1st Qu.: 4240 ## Median : 1483.5 Median : 4754 Median : 11974 ## Mean : 3107.1 Mean :11050 Mean : 26115 ## 3rd Qu.: 3431.0 3rd Qu.:12375 3rd Qu.: 27437 ## Max. :16199.0 Max. :66792 Max. :165860 ## ## ## Property crime Burglary Larceny-theft Motor vehicle theft ## Min. : 9064 Min. : 1762 Min. : 6834 Min. : 196 ## 1st Qu.: 59845 1st Qu.: 9900 1st Qu.: 40855 1st Qu.: 4368 ## Median : 140350 Median : 24880 Median : 100051 Median : 11537 ## Mean : 265612 Mean : 51749 Mean : 189228 Mean : 24635 ## 3rd Qu.: 265708 3rd Qu.: 48287 3rd Qu.: 192581 3rd Qu.: 19001 ## Max. :1721061 Max. :352328 Max. :1246078 Max. :230946
fbi_state verisinden Bölgeleri ve Amerika toplamı olan Total’ı çıkarmasaydık özet istatistikleri yukarıdaki çıktımızdan daha büyük çıkacaktı ve yanlış bir sonuç elde etmiş olacaktık. Örneğin, popülasyon ortalamamız 5.501.194 olarak çıkmış. Eğer toplamı ve bölgeleri çıkarmasaydık elde ettiğimiz değerden daha büyük bir değer elde etmiş olacaktık.
Aykırı Gözlem – Outlier tespitimizi nümerik değişkenler için boxplot ile yapabiliriz.
boxplot(fbi_state[4:14])

Elde ettiğimiz görselde sayısal her bir değişken için boxplot’ları çıkardık ve her bir değişkendeki aykırı gözlemleri görme fırsatı bulduk. Eğer bu veriyi analiz etmek istiyorsak, analiz etmeden önce aykırı gözlemler araştırılmalı ve anlamlandıramadığımız gözlemler veriden çıkartılmalıdır.
Eksik Gözlem tespiti için,
sum(is.na(fbi_state)) ## [1] 0
Düzenlediğimiz veride eksik gözlem bulunmamaktadır. Yukarıda elde ettiğimiz veri 2015 ve 2016 yıllarını içeriyor. Özet istatistiklere, görselleştirmelere bakmadan önce ve analizlere başlamadan önce amaca göre veriyi kullanmamız gerekir. Yukarıda çıkartmış olduğum özet istatistikler ve boxplot bu bağlamda yanlış olur. Çünkü aynı gözlemlerin farklı yıllardaki değerleri mevcuttur.
Sonuç
Hızlıca veriyi manipüle ettik ve cesur bir NYPD memuru olarak lanet olası federallerin bir kez daha canına okuduk! Ayrıntılara girip yazıyı uzatmak istemedim. Amacım, “Düzenli Veri” mantığı çerçevesinde veriyi manipüle etmekti. Veri, büyük ölçüde analize ve görselleştirmeye hazır durumda. Daha iyisini yapmayı ve yapmadığımız veya üzerinde çok durmadığımız prensipleri sizlere bırakıyorum. Eğer detaylara girmemi ve düzenlemiş olduğumuz veri ile bir şeyler yapmamı isterseniz yorumlara yazabilirsiniz.
Veri Bilimi yolunda herkese iyi çalışmalar. Bir sonraki yazıda görüşmek üzere.