

![]()
Elimizde her zaman iyi bir veri seti olmayacaktır. Özellikle bazı veriler için uzun ve yorucu veri manipülasyonları yapıldıktan sonra analiz, modelleme ve görselleştirme aşamasına geçilecektir. Bu yüzden veri manipülasyonu ve tidy data (düzenli veri) formatının veri bilimci adayları tarafından iyi bir şekilde benimsenmesi gerekiyor.
Dirty Data
İşte mükemmel olmayan bir veri seti karşınızda !
weather <- readRDS("weather.rds")
head(weather)## X year month measure X1 X2 X3 X4 X5 X6 X7 X8 X9 X10 X11 X12
## 1 1 2014 12 Max.TemperatureF 64 42 51 43 42 45 38 29 49 48 39 39
## 2 2 2014 12 Mean.TemperatureF 52 38 44 37 34 42 30 24 39 43 36 35
## 3 3 2014 12 Min.TemperatureF 39 33 37 30 26 38 21 18 29 38 32 31
## 4 4 2014 12 Max.Dew.PointF 46 40 49 24 37 45 36 28 49 45 37 28
## 5 5 2014 12 MeanDew.PointF 40 27 42 21 25 40 20 16 41 39 31 27
## 6 6 2014 12 Min.DewpointF 26 17 24 13 12 36 -3 3 28 37 27 25
## X13 X14 X15 X16 X17 X18 X19 X20 X21 X22 X23 X24 X25 X26 X27 X28 X29 X30
## 1 42 45 42 44 49 44 37 36 36 44 47 46 59 50 52 52 41 30
## 2 37 39 37 40 45 40 33 32 33 39 45 44 52 44 45 46 36 26
## 3 32 33 32 35 41 36 29 27 30 33 42 41 44 37 38 40 30 22
## 4 28 29 33 42 46 34 25 30 30 39 45 46 58 31 34 42 26 10
## 5 26 27 29 36 41 30 22 24 27 34 42 44 43 29 31 35 20 4
## 6 24 25 27 30 32 26 20 20 25 25 37 41 29 28 29 27 10 -6
## X31
## 1 30
## 2 25
## 3 20
## 4 8
## 5 5
## 6 1tail(weather)## X year month measure X1 X2 X3 X4 X5 X6 X7
## 281 281 2015 12 Mean.Wind.SpeedMPH 6 <NA> <NA> <NA> <NA> <NA> <NA>
## 282 282 2015 12 Max.Gust.SpeedMPH 17 <NA> <NA> <NA> <NA> <NA> <NA>
## 283 283 2015 12 PrecipitationIn 0.14 <NA> <NA> <NA> <NA> <NA> <NA>
## 284 284 2015 12 CloudCover 7 <NA> <NA> <NA> <NA> <NA> <NA>
## 285 285 2015 12 Events Rain <NA> <NA> <NA> <NA> <NA> <NA>
## 286 286 2015 12 WindDirDegrees 109 <NA> <NA> <NA> <NA> <NA> <NA>
## X8 X9 X10 X11 X12 X13 X14 X15 X16 X17 X18 X19 X20 X21
## 281 <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
## 282 <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
## 283 <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
## 284 <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
## 285 <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
## 286 <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
## X22 X23 X24 X25 X26 X27 X28 X29 X30 X31
## 281 <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
## 282 <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
## 283 <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
## 284 <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
## 285 <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
## 286 <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>Öncelikle bilmemiz gereken şey, her bir satır bir gözlemi ve her bir sütun ise değişkeni temsil etmeli!
- weather veri setinde 1. değişkenimiz “X” açıkça görülüyor ki bir anlam ifade etmiyor, sadece satır numaraları.
- “measure” değişkeninde ise her bir gözlemin muhtemelen bir değişkeni temsil ettiğini anlayabiliriz.
- Peki Veri Temizleme / Manipülasyon işlemi neden önemli ?
Gerçek dünya ve gerçek veri setleri ile karşılaştığınızda bunların hepsi dirty data olarak karşınıza çıkacaktır. Özellikle “Big Data” ile veri manipülasyonun önemi daha da ön plana çıkmıştır. Çünkü hangi sektör olursa olsun verinin boyutu ve çeşitliliği arttıkça içerisindeki kirli veri de bir o kadar artar.
Örümcek Adam’ın rahmetli Ben Amcasının da dediği gibi; “Büyük güç, büyük sorumluluk getirir”. Bu sözün veri bilimciler için meali şudur; “Büyük veri, büyük sorumluluk getirir”. Tüm Marvel severlerin başı sağolsun diyerek veri bilimi maceramıza devam edelim.
Veri manipülasyonu, veri bilimi sürecinin olmazsa olmaz aşamalarından biridir. Bu aşamayı dört maddede söylemek gerekirse,
- Veri Toplama
- Veri Manipülasyonu
- Veri Analizi / Modelleme
- Çalışmanın Raporlanması şeklindedir.
Veri manipülasyonu, veri bilimi süreçlerinden biri olduğu gibi ayrıca üzerinde en fazla vakit harcanması gereken aşamadır. Veri Bilimci büyüklerimizin de dediği gibi işin %80’lik kısmı burasıdır.
Veri manipülasyonu ne yazık ki diğer süreçler gibi belirli adımları uygulayarak sonuçlandıracağımız bir işlem değildir. Veriler ile sürekli haşır neşir olmamız ve uzun zaman harcamamız gerekmektedir. Bu noktada endişelenmemeliyiz. Veri manipülasyonunda diğer süreçler gibi beliri adımlarımız yok, fakat belirli prensiplerimiz var. Eğer bu prensiplere göre hareket edildiği taktirde başarılı bir veri manipülasyonu yapılmış demektir.
Veri manipülasyonu için üç aşamayı takip edebiliriz.
- Ham verileri keşfetmek
- Düzenli veri formatı – Tidy data
- Veriyi analizler için hazırlamak
Bu üç prensip, veri manipülasyonunun değişmez maddeleridir.
1. Ham Verileri Keşfetmek
Veri manipülasyonunun ilk aşaması ham verileri keşfetmeyi de üç alt başlığa ayırabiliriz.
- Veri setini ve yapısını anlamak
- Veriye göz atmak
- Veriyi görselleştirmek
1.1. Veri setini ve yapısını anlamak
İlk aşamamız veri setini kullandığımız programa aktarmak olacaktır. Olmayan verinin nesini analiz edelim kardeşim!
weather <- readRDS("weather.rds")Diğer aşamalarımız ise verinin türünü, boyutu, değişken türleri, değişken isimleri, değişkenlerin neleri temsil ettiklerini vs. bilmemiz gerekiyor. Teker teker bu dediğimiz aşamalara bakalım.
Aktardığımız weather verisinin ne olduğuna bakmak için class() fonksiyonunu kullanabiliriz.
class(weather)## [1] "data.frame"weather bir data frame yani bir veri seti.
weather veri setinin boyutunu öğrenmek istersek dim() fonksiyonu ile verinin kaç gözlem ve kaç değişkenden oluştuğunu görebiliriz.
dim(weather)## [1] 286 35weather veri seti 286 gözlem ve 35 değişkenden oluşmaktadır.
Bu değişkenlerin isimlerine de names() fonksiyonu ile bakalım.
names(weather)## [1] "X" "year" "month" "measure" "X1" "X2" "X3"
## [8] "X4" "X5" "X6" "X7" "X8" "X9" "X10"
## [15] "X11" "X12" "X13" "X14" "X15" "X16" "X17"
## [22] "X18" "X19" "X20" "X21" "X22" "X23" "X24"
## [29] "X25" "X26" "X27" "X28" "X29" "X30" "X31"Elimizde yıl, ay ve ölçü haricinde X’lerden oluşan ve ne anlama geldiğini bilmediğimiz değişkenler mevcut.
Yukarıda yaptıklarımız elimizdeki veriyi anlamak için temel komutlardır. Bu komutlar yerine str() fonksiyonu ile verinin yapısını görebiliriz. Ayrıca dplyr kütüphanesinin glimpse fonksiyonu da aynı işlevde kullanılır.
X değişkenleri çok azla ve karakter formatında olduğu için 1’den 6’ya kadar olan değişkenleri alalım.
str(weather[1:6])## 'data.frame': 286 obs. of 6 variables:
## $ X : int 1 2 3 4 5 6 7 8 9 10 ...
## $ year : int 2014 2014 2014 2014 2014 2014 2014 2014 2014 2014 ...
## $ month : int 12 12 12 12 12 12 12 12 12 12 ...
## $ measure: chr "Max.TemperatureF" "Mean.TemperatureF" "Min.TemperatureF" "Max.Dew.PointF" ...
## $ X1 : chr "64" "52" "39" "46" ...
## $ X2 : chr "42" "38" "33" "40" ...library(dplyr)glimpse(weather[1:6])## Observations: 286
## Variables: 6
## $ X <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,...
## $ year <int> 2014, 2014, 2014, 2014, 2014, 2014, 2014, 2014, 2014, ...
## $ month <int> 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12...
## $ measure <chr> "Max.TemperatureF", "Mean.TemperatureF", "Min.Temperat...
## $ X1 <chr> "64", "52", "39", "46", "40", "26", "74", "63", "52", ...
## $ X2 <chr> "42", "38", "33", "40", "27", "17", "92", "72", "51", ...Bu çıktıları anlatmaya gerek yok, işte görüyorsunuz! Yukarıda yaptıklarımızı iki fonksiyon detaylı bir şekilde veriyor.
Elimizdeki veriyi daha iyi anlamak için summary() fonksiyonundan da bahsedelim tam olsun.
summary(weather)## X year month measure
## Min. : 1.00 Min. :2014 Min. : 1.000 Length:286
## 1st Qu.: 72.25 1st Qu.:2015 1st Qu.: 4.000 Class :character
## Median :143.50 Median :2015 Median : 7.000 Mode :character
## Mean :143.50 Mean :2015 Mean : 6.923
## 3rd Qu.:214.75 3rd Qu.:2015 3rd Qu.:10.000
## Max. :286.00 Max. :2015 Max. :12.000
## X1 X2 X3
## Length:286 Length:286 Length:286
## Class :character Class :character Class :character
## Mode :character Mode :character Mode :character
##
## X4 X5 X6
## Length:286 Length:286 Length:286
## Class :character Class :character Class :character
## Mode :character Mode :character Mode :character
##
## X7 X8 X9
## Length:286 Length:286 Length:286
## Class :character Class :character Class :character
## Mode :character Mode :character Mode :character
##
## X10 X11 X12
## Length:286 Length:286 Length:286
## Class :character Class :character Class :character
## Mode :character Mode :character Mode :character
##
## X13 X14 X15
## Length:286 Length:286 Length:286
## Class :character Class :character Class :character
## Mode :character Mode :character Mode :character
##
## X16 X17 X18
## Length:286 Length:286 Length:286
## Class :character Class :character Class :character
## Mode :character Mode :character Mode :character
##
## X19 X20 X21
## Length:286 Length:286 Length:286
## Class :character Class :character Class :character
## Mode :character Mode :character Mode :character
##
## X22 X23 X24
## Length:286 Length:286 Length:286
## Class :character Class :character Class :character
## Mode :character Mode :character Mode :character
##
## X25 X26 X27
## Length:286 Length:286 Length:286
## Class :character Class :character Class :character
## Mode :character Mode :character Mode :character
##
## X28 X29 X30
## Length:286 Length:286 Length:286
## Class :character Class :character Class :character
## Mode :character Mode :character Mode :character
##
## X31
## Length:286
## Class :character
## Mode :character
summary verinin özetini veren bir fonksiyondur. summary(), weather veri setimizde şık durmadığı için iris veri seti ile bakalım.summary(iris)## Sepal.Length Sepal.Width Petal.Length Petal.Width
## Min. :4.300 Min. :2.000 Min. :1.000 Min. :0.100
## 1st Qu.:5.100 1st Qu.:2.800 1st Qu.:1.600 1st Qu.:0.300
## Median :5.800 Median :3.000 Median :4.350 Median :1.300
## Mean :5.843 Mean :3.057 Mean :3.758 Mean :1.199
## 3rd Qu.:6.400 3rd Qu.:3.300 3rd Qu.:5.100 3rd Qu.:1.800
## Max. :7.900 Max. :4.400 Max. :6.900 Max. :2.500
## Species
## setosa :50
## versicolor:50
## virginica :50
summary fonksiyonu kategorik ve nümerik değişkenler için farklı özet verir. Nümerik değişkenler için, değişkenin minimum, maksimum, kartiller, medyan ve ortalama değerlerini verirken, kategorik değişkenler için gözlemlerin frekanslarını verir.Bu bölümü özetlemek gerekirse,
- class() fonksiyonu veri nesnelerinin sınıfını,
- dim() fonksiyonu verinin boyutunu,
- names() fonksiyonu sütunların (değişkenlerin) isimlerini,
- str() ve glimpse() fonksiyonları da verilerin yapılarını,
- summary() fonksiyonu ise özet istatistikleri verir.
1.2. Veriye göz atmak
Yukarıdaki komutlar ile veri setimiz hakkında bazı fikirler edindik. Şimdi veriye göz atma zamanı!
İlk bilmemiz gereken nokta tüm veriyi göz ile teker teker inceleyemeyeceğimizdir. Özellikle verinin boyutu büyüdükçe bu iş zorlaşır. Bu yüzden verinin baştaki ve sondaki verileri görmemizi sağlayan head() ve tail() fonksiyonları veriyi görmemizde yardımcı olurlar. Default – Varsayılan hali ile ilk 6 ve son 6 gözlemleri gösterirler. Eğer gözlem sayısını belirlemek istiyorsak kendimiz bir değer girebiliriz. Örneğin ilk 15 ve son 20 gözlemi görmek istiyorsanız, head(veri_ismi, 15) ve tail(veri_ismi, 20) şeklinde yazabilirsiniz.
head(weather)## X year month measure X1 X2 X3 X4 X5 X6 X7 X8 X9 X10 X11 X12
## 1 1 2014 12 Max.TemperatureF 64 42 51 43 42 45 38 29 49 48 39 39
## 2 2 2014 12 Mean.TemperatureF 52 38 44 37 34 42 30 24 39 43 36 35
## 3 3 2014 12 Min.TemperatureF 39 33 37 30 26 38 21 18 29 38 32 31
## 4 4 2014 12 Max.Dew.PointF 46 40 49 24 37 45 36 28 49 45 37 28
## 5 5 2014 12 MeanDew.PointF 40 27 42 21 25 40 20 16 41 39 31 27
## 6 6 2014 12 Min.DewpointF 26 17 24 13 12 36 -3 3 28 37 27 25
## X13 X14 X15 X16 X17 X18 X19 X20 X21 X22 X23 X24 X25 X26 X27 X28 X29 X30
## 1 42 45 42 44 49 44 37 36 36 44 47 46 59 50 52 52 41 30
## 2 37 39 37 40 45 40 33 32 33 39 45 44 52 44 45 46 36 26
## 3 32 33 32 35 41 36 29 27 30 33 42 41 44 37 38 40 30 22
## 4 28 29 33 42 46 34 25 30 30 39 45 46 58 31 34 42 26 10
## 5 26 27 29 36 41 30 22 24 27 34 42 44 43 29 31 35 20 4
## 6 24 25 27 30 32 26 20 20 25 25 37 41 29 28 29 27 10 -6
## X31
## 1 30
## 2 25
## 3 20
## 4 8
## 5 5
## 6 1tail(weather)## X year month measure X1 X2 X3 X4 X5 X6 X7
## 281 281 2015 12 Mean.Wind.SpeedMPH 6 <NA> <NA> <NA> <NA> <NA> <NA>
## 282 282 2015 12 Max.Gust.SpeedMPH 17 <NA> <NA> <NA> <NA> <NA> <NA>
## 283 283 2015 12 PrecipitationIn 0.14 <NA> <NA> <NA> <NA> <NA> <NA>
## 284 284 2015 12 CloudCover 7 <NA> <NA> <NA> <NA> <NA> <NA>
## 285 285 2015 12 Events Rain <NA> <NA> <NA> <NA> <NA> <NA>
## 286 286 2015 12 WindDirDegrees 109 <NA> <NA> <NA> <NA> <NA> <NA>
## X8 X9 X10 X11 X12 X13 X14 X15 X16 X17 X18 X19 X20 X21
## 281 <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
## 282 <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
## 283 <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
## 284 <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
## 285 <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
## 286 <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
## X22 X23 X24 X25 X26 X27 X28 X29 X30 X31
## 281 <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
## 282 <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
## 283 <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
## 284 <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
## 285 <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
## 286 <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>Bu bölümün özetlemek gerekirse,
- head(), varsayılan hali ile ilk 6 gözlemi
- tail(), varsayılan hali ile son 6 gözlemi verir.
- print(), veri setinin hepsini görmek istersek print() fonksiyonu kullanılabilir. Ama büyük veri setleri için önerilmez.
1.3. Görselleştirmek
Eğer veriye daha detaylı göz atmak istiyorsak neden görselleştirme yapmayalım ki ? Şuan weather veri seti görselleştirme için uygun olmadığından yine iris veri seti üzerinden görselleştirelim. İlerideki kısımlarda weather veri setini manipüle edeceğiz.
iris veri seti iris türündeki çiçeklerin santimetre cinsinden uzunluğunu ve genişliği veren ölçülerde “sepal” ve “petal” değişkenlerini bize sunar. Petal(Taç yaprağı) uzunluğunun dağılımına bakmak istersek histogramı aşağıdaki gibidir.
hist(iris$Petal.Length)

Eğer iki değişken arasındaki ilişkiye bakmak istersek plot() fonksiyonu ile bir scatterplot – dağılım grafiği elde edebiliriz.
plot(iris$Petal.Length, iris$Sepal.Length)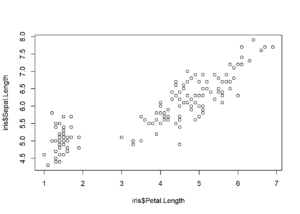
Boxplot – Kutu grafiği ile bir değişkenin dağılımını ve değişkendeki aykırı gözlemleri görebiliriz.
boxplot(iris$Petal.Length)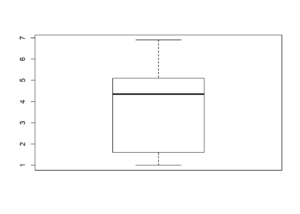
Bu bölümü özetlemek gerekirse,
- hist() ile tek bir değişkenin dağılımını görmek için histogram elde ederiz.
- plot() ile iki değişken arasındaki ilişkiyi görmek için scatterplot elde ederiz.
- boxplot() ile tek bir değişkenin dağılımını ve aykırı gözlem tespiti için boxplot elde ederiz.
2. Düzenli Veri Formatı – Tidy Data
2014’te Hadley Wickham, Journal of Statistical Software’de “Tidy Data” adında bir makalesi ile bize bazı prensipler üzerinde veri manipülasyonu yapmanın kolay ve pratik yollarını sundu. Bu bölümde bu prensipleri uygulamaya çalışacağız. Yayınlanan makele: http://www.jstatsoft.org/v59/i10/paper.
Düzenli bir veri seti örneği olarak bir veri seti oluşturalım.
kisi <- data.frame(
kisi = c("Ayşe","Fatma","Hayriye","Ali","Veli"),
cinsiyet = c("K","K","K","E","E"),
goz = c("Ela", "Mavi", "Yeşil","Ela","Mavi"),
boy = c(1.67, 1.73, 1.60, 1.80, 1.75),
yas = c(20, 32, 45, 18, 28)
)
kisi## kisi cinsiyet goz boy yas
## 1 Ayşe K Ela 1.67 20
## 2 Fatma K Mavi 1.73 32
## 3 Hayriye K Yeþil 1.60 45
## 4 Ali E Ela 1.80 18
## 5 Veli E Mavi 1.75 28Burada 5 kişinin isim, cinsiyet, boy ve yaşını gösteren bir veri seti.
İlk satıra bakacak olursak, Ayşe adındaki kişinin bir hanımefendi olduğu, gözünün ela renginde, boyunun 1.67 ve yaşının da 20 olduğu bilgisine ulaşırız. İlk satır tek bir kişiye ait özellikleri barındırır, yani birinci satır aslında bir gözlemi (observation) ifade eder.
Dördüncü sütuna bakacak olursak, her bir gözlemin yaşlarının dağılımını verir. Sütun da bir değişken (variable) ya da bir davranışı (attribute) temsil eder.
Bu veri setinde her bir gözlem her bir kişinin karakteristik özelliklerini verir.
2.1. Düzenli Veri Prensipleri
Yukarıdan çıkartılacak prensipler şunlardır:
- Gözlemler satır olmalıdır,
- Değişkenler satır olmalıdır ve
- Tablo başına gözlem birimi bir tür olmalıdır.
Veri seti değerlerin bir toplamıdır. Her bir değer hem bir değişkene ve hem de bir gözleme aittir. Bir değişken farklı birimler için aynı ölçüleri / davranışları gösteren değerleri içerir. Bir gözlem ise tek bir birim için farklı ölçüleri / davranışları gösteren değerleri içerir.
Şimdi bu prensipleri dağınık bir veri seti (dirty data) üzerinde görelim.
2.2. Dağınık Veri Teşhisi
kisi_dirty <- data.frame(
kisi = c("Ayşe","Fatma","Hayriye","Ali","Veli"),
cinsiyet = c("K","K","K","E","E"),
ela = c(1,0,0,1,0),
mavi = c(0,1,0,0,1),
yesil = c(0,0,1,0,0),
boy = c(1.67, 1.73, 1.60, 1.80, 1.75),
yas = c(20, 32, 45, 18, 28)
)
kisi_dirty## kisi cinsiyet ela mavi yesil boy yas
## 1 Ayşe K 1 0 0 1.67 20
## 2 Fatma K 0 1 0 1.73 32
## 3 Hayriye K 0 0 1 1.60 45
## 4 Ali E 1 0 0 1.80 18
## 5 Veli E 0 1 0 1.75 28Buradaki sorunumuz nedir ? Bu veri setinde hala gözlemlerimiz satır ve gözlem birimimiz de insan. Ayrıca her bir sütun da bir değişkeni temsil ediyor. Ancak, burada fark etmemiz gereken “ela”, “mavi” ve “yesil” değişkenleri önceki tablomuzda göz renklerini temsil eden birer değerlerdi. Buradaki sorunun benzeri de başka veri setlerinde karşınıza çıkacaktır, yaygın olarak dağınık veri tipi şeklidir. Burada değişken başlıkları birer değerdir, bir değişken ismi değildir.
2.3. Geniş veya Uzun Veri Setleri
Başımıza gelecek bir başka dert de geniş veya uzun veri setleridir. Bu satırların değişkenlerden (uzun olma problemi) veya değişkenlerin satırlardan (geniş olma problemi) çok fazla olma durumudur. Yukarıda yaptığımız kişi özellikleri veri setleri gibi düşünebilirsiniz.
Veri setlerinin geniş veya uzun olma problemini de Hadley Wickham’ın yazdığı “tidyr” paketi ile çözebiliriz. tidyr paketi düzenli veri prensiplerini uygulamamızda büyük kolaylık sağlar.
2.3.1. Geniş Veri Seti – gather() Fonksiyonu
wide <- data.frame(
bilinmeyen = c("X","Y"),
A = c(1, 4),
B = c(2, 5),
C = c(3, 6),
D = c(4, 7)
)
wide## bilinmeyen A B C D
## 1 X 1 2 3 4
## 2 Y 4 5 6 7Elimizde X ve Y iki bilinmeyenimiz var. Ayrıca A,B,C ve D şeklinde 4 kategori ve bu kategorilerin aldığı bir değer var.
- Yukarıda düzenli veri formatı için şu ifadeyi kullanmıştık:
“Veri seti değerlerin bir toplamıdır. Her bir değer hem bir değişkene ve hem de bir gözleme aittir. Bir değişken farklı birimler için aynı ölçüleri / davranışları gösteren değerleri içerir. Bir gözlem ise tek bir birim için farklı ölçüleri / davranışları gösteren değerleri içerir.”
Örneğimizde A,B,C ve D değişkenleri bilinmeyenlerimizin kategorileridir, yani bu kategoriler farklı birimler için aynı ölçüleri / davranışları gösterir. Kategorilerin aldığı değerler ise tek bir birim için farklı ölçüleri / davranışları gösterir.
tidyr paketinden gather() fonksiyonu ile geniş veri seti problemini çözebiliriz.
- gather() ile sütunları key-value eşleri haline getirme işlemi aşağıdaki gibidir.
gather(data, key, value, …)
Veri setimizi wide olarak belirttik, key-value eşlerini belirlemek içinde biinmeyen isimli değişkenimizi dışarıda bıraktık ve böylelikle düzenli veri formatını elde etmiş olduk.
library(tidyr)
gather(wide, key = "kategori", value = "deger" , -bilinmeyen)## bilinmeyen kategori deger
## 1 X A 1
## 2 Y A 4
## 3 X B 2
## 4 Y B 5
## 5 X C 3
## 6 Y C 6
## 7 X D 4
## 8 Y D 72.3.2. Uzun Veri Seti – spread() Fonksiyonu
Burada “Geniş Veri Seti” kısmında yaptıklarımızın tam tersini yapıyor olacağız. Başka veri seti oluşturmaya gerek olmadığından gather işlemini long isminde kaydedelim ve uzunbir veri seti elde etmiş olalım.
long <- gather(wide, key = "kategori", value = "deger" , -bilinmeyen)
long## bilinmeyen kategori deger
## 1 X A 1
## 2 Y A 4
## 3 X B 2
## 4 Y B 5
## 5 X C 3
## 6 Y C 6
## 7 X D 4
## 8 Y D 7- gather() fonksiyonun tam tersini yapan spread() fonksiyonu ile uzun veri setini geniş bir veri setine dönüştürebiliriz.
spread(data, key, value)
spread(long, kategori, deger)## bilinmeyen A B C D
## 1 X 1 2 3 4
## 2 Y 4 5 6 7Çıktıda gördüğümüz gibi orjinal “wide” veri setini elde etmiş olduk.
2.4. Değişken Birleştirme ve Ayırma
Veri setimizde bazı değişkenlerin birleştirilmesi ve ayrıştırılmasına ihtiyaç duyabiliriz. Bu yüzden tidyr paketi bize iki kullanışlı fonksiyon daha sunuyor, separate() ve unite() fonksiyonları.
Bu fonksiyonları kullanmak için “kisi” adlı veri setimize her bir kişinin doğum tarihlerini yazalım.
kisi$dogum_tarihi <- c("1998-02-11", "1986-01-30", "1973-05-12", "2000-02-09", "1990-03-13")- separate() fonksiyonu ile “yil”, “ay” ve “gun” şeklinde üç değişkene ayıralım.
kisi_ayri <- separate(kisi, dogum_tarihi, c("yil", "ay", "gun"), sep = "-")- unite() fonksiyonu ile de tarih değişkenlerini birleştirelim.
unite(kisi_ayri, dogum_tarihi, yil, ay, gun, sep = "-")## kisi cinsiyet goz boy yas dogum_tarihi
## 1 Ayşe K Ela 1.67 20 1998-02-11
## 2 Fatma K Mavi 1.73 32 1986-01-30
## 3 Hayriye K Yeþil 1.60 45 1973-05-12
## 4 Ali E Ela 1.80 18 2000-02-09
## 5 Veli E Mavi 1.75 28 1990-03-13tidyr paketini özetlemek gerekirse,
- gather() fonksiyonu, sütunları key-value eşleri olarak bir araya toplar.
- spread() fonksiyonu, key-value eşlerini sütunlara yayar.
- separate() fonksiyonu, bir değişkeni birden fazla değişkene ayırır.
- unite() fonksiyonu, birden fazla değişkeni tek bir değişken olarak birleştirir.
Bölüm Sonu
Bu bölümde veri manipülasyonun öneminden, Dirty Data Vs. Tidy Data kavramlarının neler olduğundan, önümüze veri geldiğinde ilk yapmamız gereken aşamalardan, tidyr kütüphanesinden bahsettik. Bir sonraki bölümde dağınık verileri göreceğimiz ve değişken tipleri üzerinde konuşacağımız bir bölüm olacaktır.