

![]()
Önceki yazımız, Bölüm 1/6’da metin yapılarının ve düzenli metin formatının ne olduğundan bahsettik. Temel amacımız, tidytext kütüphanesi ile metinleri parçalamak ve kelime frekanslarını elde etmek. Bu yazı serisinde, tidytext kütüphanesi ile birlikte bolca dplyr ve ggplot2 kütüphaneleri kullanılacaktır.
Bölüm 2/6’da ise bir metni anlamlandırmanın en kolay ve uygun yolu olan “Duygu Analizini” (sentiments analysis) öğreneceğiz.
2. Bölüm – Düzenli Metin ile Duygu Analizi
Duygu Analizi (Sentiment Analysis) veya Görüş Madenciliği (Opinion Mining) elimizdeki metnin hangi anlamları içerdiğini anlatır. Metnin bir bölümünün veya tamamının pozitif mi, negatif mi, yoksa kızgınlık, süpriz gibi duyguları içerip içermediğini yani kelimelerin duygusal niyetlerini anlamada kullanırız.
2.1. sentiments Veri Seti
Tidytext paketi içerisinde sentiments veri kümesi birkaç duygu (duyarlılık) sözlüğü (lexicon) içerir .
library(tidytext)
sentiments## # A tibble: 27,314 x 4
## word sentiment lexicon score
## <chr> <chr> <chr> <int>
## 1 abacus trust nrc NA
## 2 abandon fear nrc NA
## 3 abandon negative nrc NA
## 4 abandon sadness nrc NA
## 5 abandoned anger nrc NA
## 6 abandoned fear nrc NA
## 7 abandoned negative nrc NA
## 8 abandoned sadness nrc NA
## 9 abandonment anger nrc NA
## 10 abandonment fear nrc NA
## # ... with 27,304 more rowsGenel amaçlı üç sözcük vardır
- AFINN (Finn Arup Nielsen) ,
- bing (Bing Liu ve ortakları),
- nrc (Saif Mohammad ve Peter Turney) .
Bu sözlüklerin üçü de unigramlara, yani tek kelimelere dayanmaktadır.
Afinn sözlüğü olumlu / olumsuz şeklinde her bir kelimenin -5 ile +5 arasında sayısal skoru bulunmaktadır. Bing sözlüğünde olumlu / olumsuz şeklinde iki kategoride bulunur. Nrc sözlüğünde ise pozitif, negatif, öfke, beklenti, tiksinti, korku, sevinç, üzüntü, şaşkınlık ve güven (positive, negative, anger, anticipation, disgust, fear, joy, sadness, surprise ve trust) gibi kategoriler bulunur.
get_sentiments("afinn")## # A tibble: 2,476 x 2
## word score
## <chr> <int>
## 1 abandon -2
## 2 abandoned -2
## 3 abandons -2
## 4 abducted -2
## 5 abduction -2
## 6 abductions -2
## 7 abhor -3
## 8 abhorred -3
## 9 abhorrent -3
## 10 abhors -3
## # ... with 2,466 more rowsget_sentiments("bing")## # A tibble: 6,788 x 2
## word sentiment
## <chr> <chr>
## 1 2-faced negative
## 2 2-faces negative
## 3 a+ positive
## 4 abnormal negative
## 5 abolish negative
## 6 abominable negative
## 7 abominably negative
## 8 abominate negative
## 9 abomination negative
## 10 abort negative
## # ... with 6,778 more rowsget_sentiments("nrc")## # A tibble: 13,901 x 2
## word sentiment
## <chr> <chr>
## 1 abacus trust
## 2 abandon fear
## 3 abandon negative
## 4 abandon sadness
## 5 abandoned anger
## 6 abandoned fear
## 7 abandoned negative
## 8 abandoned sadness
## 9 abandonment anger
## 10 abandonment fear
## # ... with 13,891 more rowsSözlük tabanlı yöntemler, metindeki her bir kelime için bireysel duygu puanlarını toplayarak bir metin parçasının toplam duyarlılığını buluyor.
Birçok İngilizce kelime oldukça nötr olduğundan, her İngilizce kelime sözlükte bulunmmaktadır.
Duygu analizinde veri büyüklüğü önemlidir. Veri ne kadar büyükse, metin içerisindeki anlamı o kadar ortaya çıkarır.
2.2. inner_join() ile Duygu Analizi
Veriler düzenli bir formatta, içsel birleşim ile duygu analizi yapılabilir. Duraklama kelimelerini kaldırma bir anti_join işlemi idi, duygu analizi yapmak bir içsel birleştirme inner_join işlemidir.
NRC sözlüğünü kullanarak bir sevinç (joy) kelimelere bakalım. Jane Austen’ın Emma kitabındaki en yaygın sevinç kelimeleri nelerdir?
Önceki bölümde yaptığımız gibi veriyi düzenli metin haline dönüştürmemiz gerekiyor. Ayrıca her bir kelimenin nereden geldiğini ve kitabın hangi bölümünden olduğunu takip etmek için başka değişkenler (sütunlar) hazırlayalım. group_by() ve mutate() bize bu değişkenleri eklememizde yardmcı olacaktır.
library(janeaustenr)
library(dplyr)
library(stringr)
tidy_books <- austen_books() %>%
group_by(book) %>%
mutate(linenumber = row_number(),
chapter = cumsum(str_detect(text, regex("^chapter [\\divxlc]",
ignore_case = TRUE)))) %>%
ungroup() %>%
unnest_tokens(word, text)Artık metin düzenli bir formatta olduğu için, duygu analizini yapmaya hazırız. Öncelikle NRC sözlüğünü ve filter() ile “sevinç” (“joy”) kelimelerini kullanalım .
nrc_joy <- get_sentiments("nrc") %>%
filter(sentiment == "joy")
tidy_books %>%
filter(book == "Emma") %>%
inner_join(nrc_joy) %>%
count(word, sort = TRUE)## Joining, by = "word"## # A tibble: 303 x 2
## word n
## <chr> <int>
## 1 good 359
## 2 young 192
## 3 friend 166
## 4 hope 143
## 5 happy 125
## 6 love 117
## 7 deal 92
## 8 found 92
## 9 present 89
## 10 kind 82
## # ... with 293 more rowsUmut, dostluk ve aşk (“hope”, “friendship” ve “love”) hakkında çoğunlukla olumlu, mutlu sözler görüyoruz.
Her bir romanda duyguların nasıl değiştiğini de inceleyebiliriz. Bunu da dplyr fonksiyonları ile rahatlıkla yapabiliriz. İlk olarak Bing sözlüğü ile her kelime için duyarlılık puanı bulalım.
Sonra, her kitabın tanımlı bölümlerinde kaç tane olumlu ve olumsuz kelimelerin bulunduğuna bakalım. 80 satırlık metin bölümlerini alarak kitap içeriside nerede olduğumuzun izini sürmek için bir index tanımlayalım.
- %/% Operatörü tamsayı bölme işlemi yapar.
Metinlerin küçük bölümleri, kitapların gerçek anlatı yapısını anlatamayabilir. Çünkü iyi bir duygu analizi için yeteri kadar kelimeye sahip olmayacaktır. Buradaki kitaplar için 80 satırın alınması kullanışlı olacaktır. Ancak elinizdeki farklı metinlerin dizelerine (line) göre sizlerin karar vermesi gerekir. Daha sonra da spread() fonksiyonu ile gözlem (satır) biçiminde olan negatif ve pozitif duyguları değişken (sütun) olarak biçimine dönüştürür ve sonrasında gerekli hesaplamalar yapılır.
library(tidyr)
jane_austen_sentiment <- tidy_books %>%
inner_join(get_sentiments("bing")) %>%
count(book, index = linenumber %/% 80, sentiment) %>%
spread(sentiment, n, fill = 0) %>%
mutate(sentiment = positive - negative)## Joining, by = "word"Şimdi bu duygu puanlarını her bir roman için grafiksel olarak gösterebiliriz. x-ekseninde indexe karşı bir görselleştirme yaptık.
Jane Austen’in romanlarının Bing sözlüğüne göre Duygu Analizi
library(ggplot2)
ggplot(jane_austen_sentiment, aes(index, sentiment, fill = book)) +
geom_col(show.legend = FALSE) +
facet_wrap(~book, ncol = 2, scales = "free_x") 
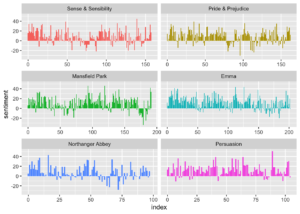
Her romanın kendi içerisinde nasıl ilerlediği, olumlu veya olumsuz duygulara nasıl dönüştüğünü görebiliriz.
2.3. Üç Duygu Sözlüğünün Karşılaştrılması (Afinn – Bing – Nrc)
Hangi duygu sözlüğünün bizim için en uygun olduğuna bakmamız gerekebilir. Jane Austen’ın “Pride and Prejudice” kitabında anlatı biçiminin nasıl değiştiğini görelim. Öncelikle, filter() fonksiyonu ile ilgilendiğimiz kitabı seçelim.
pride_prejudice <- tidy_books %>%
filter(book == "Pride & Prejudice")
pride_prejudice## # A tibble: 122,204 x 4
## book linenumber chapter word
## <fct> <int> <int> <chr>
## 1 Pride & Prejudice 1 0 pride
## 2 Pride & Prejudice 1 0 and
## 3 Pride & Prejudice 1 0 prejudice
## 4 Pride & Prejudice 3 0 by
## 5 Pride & Prejudice 3 0 jane
## 6 Pride & Prejudice 3 0 austen
## 7 Pride & Prejudice 7 1 chapter
## 8 Pride & Prejudice 7 1 1
## 9 Pride & Prejudice 10 1 it
## 10 Pride & Prejudice 10 1 is
## # ... with 122,194 more rowsŞimdi, inner_join() ile duygu sözlüklerini verimiz ile birleştirelim.
Yukarıda Afinn sözlüğü -5 ile +5 arasında sayısal skorlama ile duygu analizini gerçeleştirmişti. Bing ve Nrc sözlüü ise kelimeleri olumlu ve olumsuz kelimeler şeklinde sınıflandırır. Afinn sözlüğünden farklı işlemler yapmamız gerekiyor.
Tekrar tamsayı bölme %/% işlemini 80 satır için yaptıktan sonra count(), spread() ve mutate() fonksiyonlarını kullanmamız gerekir.
afinn <- pride_prejudice %>%
inner_join(get_sentiments("afinn")) %>%
group_by(index = linenumber %/% 80) %>%
summarise(sentiment = sum(score)) %>%
mutate(method = "AFINN")## Joining, by = "word"bing_and_nrc <- bind_rows(pride_prejudice %>%
inner_join(get_sentiments("bing")) %>%
mutate(method = "Bing et al."),
pride_prejudice %>%
inner_join(get_sentiments("nrc") %>%
filter(sentiment %in% c("positive",
"negative"))) %>%
mutate(method = "NRC")) %>%
count(method, index = linenumber %/% 80, sentiment) %>%
spread(sentiment, n, fill = 0) %>%
mutate(sentiment = positive - negative)## Joining, by = "word"
## Joining, by = "word"Her bir duygu sözlüğü için pozitif ve negatif duygu analizimiz mevcut. Onları bir araya getirerek görselleştirelim.
“Pride and Prejudice” ile üç duygu sözlüğünü karşılaştırma,
bind_rows(afinn,
bing_and_nrc) %>%
ggplot(aes(index, sentiment, fill = method)) +
geom_col(show.legend = FALSE) +
facet_wrap(~method, ncol = 1, scales = "free_y")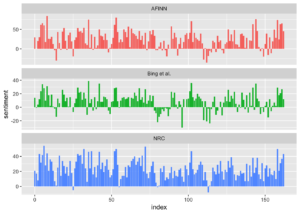
Duyguları hesaplamak için kullanılan üç farklı sözlük mutlak anlamda farklı sonuçlar verecektir ama Jane Austen romanında üç duygu sözlüğü arasında benzerlikler görülmektedir. Romanda aynı yerlere benzer düşmeler ve zirveler görüyoruz, ama mutlak değerler çok farklıdır.
Bu sözlüklerde kaç olumlu ve olumsuz kelimeye kısaca bakalım.
get_sentiments("nrc") %>%
filter(sentiment %in% c("positive",
"negative")) %>%
count(sentiment)## # A tibble: 2 x 2
## sentiment n
## <chr> <int>
## 1 negative 3324
## 2 positive 2312get_sentiments("bing") %>%
count(sentiment)## # A tibble: 2 x 2
## sentiment n
## <chr> <int>
## 1 negative 4782
## 2 positive 2006Her iki sözlükte de olumlu (pozitif) kelimelerin olumsuz kelimelerden daha az olduğunu görüyoruz. Ancak negatif kelimelerin pozitif kelimelere oranı Bing sözlüğünde Nrc sözlüğünden daha fazla olduğu görüyoruz. Yukarıdaki grafikte görüldüğü gibi, kelime eşleşmelerinde bir farklılık olacağı gibi, Nrc sözlüğündeki negatif kelimeler Jane Austen’ın çok iyi kullandığı kelimelerle uyuşmadığı sürece katkıda bulunacaktır. Duygu sözlüklerinde farklılıkların kaynağı ne olursa olsun anlatımda benzerlikler görüyoruz
2.4. En Yaygın Olumlu ve Olumsuz Kelimeler
count() fonksiyonu ile hem duyguya katkıda bulunan kelime sayılarını görebiliriz.
bing_word_counts <- tidy_books %>%
inner_join(get_sentiments("bing")) %>%
count(word, sentiment, sort = TRUE) %>%
ungroup()## Joining, by = "word"bing_word_counts## # A tibble: 2,585 x 3
## word sentiment n
## <chr> <chr> <int>
## 1 miss negative 1855
## 2 well positive 1523
## 3 good positive 1380
## 4 great positive 981
## 5 like positive 725
## 6 better positive 639
## 7 enough positive 613
## 8 happy positive 534
## 9 love positive 495
## 10 pleasure positive 462
## # ... with 2,575 more rowsGörselleştirmek istersek, Jane Austen’in romanlarında olumlu ve olumsuz duygulara katkıda bulunan kelimeler.
bing_word_counts %>%
group_by(sentiment) %>%
top_n(10) %>%
ungroup() %>%
mutate(word = reorder(word, n)) %>%
ggplot(aes(word, n, fill = sentiment)) +
geom_col(show.legend = FALSE) +
facet_wrap(~sentiment, scales = "free_y") +
labs(y = "Contribution to sentiment",
x = NULL) +
coord_flip()## Selecting by n
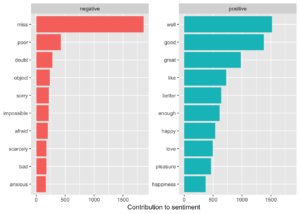
Şekile baktığımızda duygu analizinde bir anomali tespit ediyoruz, “miss” kelimesi negatif olarak kodlanmıştır, ancak Jane Austen’in eserlerinde genç, evlenmemiş kadınlar için bir sıfat olarak kullanılmıştır.
Eğer “miss” kelimesini bir duraklama kelimesi olarak belirleseydik bind_rows() ile bunu gerçekleştirebilirdik.
custom_stop_words <- bind_rows(data_frame(word = c("miss"),
lexicon = c("custom")),
stop_words)
custom_stop_words## # A tibble: 1,150 x 2
## word lexicon
## <chr> <chr>
## 1 miss custom
## 2 a SMART
## 3 a's SMART
## 4 able SMART
## 5 about SMART
## 6 above SMART
## 7 according SMART
## 8 accordingly SMART
## 9 across SMART
## 10 actually SMART
## # ... with 1,140 more rows2.5. Wordcloud – Kelime Bulutu
- wordcloud kütüphanesi
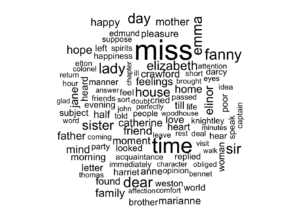
Jane Austen’in romanlarındaki en yaygın kelimelerin kelime bulutu ile görselleştirilmesi.
library(wordcloud)
tidy_books %>%
anti_join(stop_words) %>%
count(word) %>%
with(wordcloud(word, n, max.words = 100))## Joining, by = "word"
- reshape2 kütüphanesi
Jane Austen’in romanlarındaki en yaygın olumlu ve olumsuz kelimelerin kelime bulutu ile gösterilmesi.
library(reshape2)
tidy_books %>%
inner_join(get_sentiments("bing")) %>%
count(word, sentiment, sort = TRUE) %>%
acast(word ~ sentiment, value.var = "n", fill = 0) %>%
comparison.cloud(colors = c("gray20", "gray80"),
max.words = 100)## Joining, by = "word"

Kelimelerin büyüklüğü metin içerisindeki frekansı ile ilgilidir. Ancak kelimelerin büyüklükleri kelimelerin duyguları ile karşılaştırılabilir değildir.
- wordcloud2 kütüphanesi
wordcloud2 ile resimler üzerine kelime bulutu işlemini uygulayabilirsiniz.
2.6 Özet
Duygu analizi, metinlerde ifade edilen tutum ve görüşleri anlamanın bir yolunu sunar. Duygu sözlüklerini kullanarak karşılaştırmalar yapılabilir. Afinn sözlüğü kelimelerin duygu skorlarını, Bing sözlüğü olumlu/olumsuz kelimeleri, Nrc sözlüğü ise birden fazla duygu içeren kelimeleri bize verir.