

![]()
Sıkı durun uzun bir yazı olacak! Böyle bir macera ilk defa başıma geldiğinde çok zordur bu iş diyordum ancak öyle çok korkulacak bir şey olmadığını işi yaptıktan sonra fark ettim. Şimdi nereden çıktı bu konu? Ben veri temizliği için Pandas’ı çok seviyorum. Büyük veri setlerinin temizlemek istediğim yerlerini koparıp Pandas ile temizleyip tekrar yerine koyuyorum.
Peki aşağıdaki serüveni nasıl bir ortamda gerçekleştirdim? Ben 4 sunuculu Hadoop cluster kullanıyorum. Hadoop dağıtımım Cloudera (CDH 5.8.4), Spark 1.6.0, Python 2.6.6, kod geliştirme ortamı olarak Jupyter, dil olarak PySpark, ana bilgisayar Windows 10. Şimdi yapacağımız iş şu: imdb_ratings veri setimizi (Pandas Dataframe(DF)) alıp önce Spark DF’e çevireceğiz, sonra bu Spark DF’i Hive tablosu olarak HDFS’e yazdıracağız ve en son olarak Jupyter’de Hive tablosuna kaydettiğimiz bu tabloyu çağırıp SparkDF’e aktaracağız.
IMDB Ratings Veri Setini İndirme
import pandas as pd
filmListesiPandasDF = pd.read_csv("https://raw.githubusercontent.com/erkansirin78/datasets/master/imdb_1000.csv")
filmListesiPandasDF.head()| star_rating | title | content_rating | genre | duration | actors_list | |
|---|---|---|---|---|---|---|
| 0 | 9.3 | The Shawshank Redemption | R | Crime | 142 | [u’Tim Robbins’, u’Morgan Freeman’, u’Bob Gunt… |
| 1 | 9.2 | The Godfather | R | Crime | 175 | [u’Marlon Brando’, u’Al Pacino’, u’James Caan’] |
| 2 | 9.1 | The Godfather: Part II | R | Crime | 200 | [u’Al Pacino’, u’Robert De Niro’, u’Robert Duv… |
| 3 | 9.0 | The Dark Knight | PG-13 | Action | 152 | [u’Christian Bale’, u’Heath Ledger’, u’Aaron E… |
| 4 | 8.9 | Pulp Fiction | R | Crime | 154 | [u’John Travolta’, u’Uma Thurman’, u’Samuel L…. |
Pandas DF Veri Türlerini Kontrol Etme
Pandas DF’i Spark DF’e çevirmeden önce info() metoduyla Pandas DF veri tiplerine göz atalım. Buradan bir şey anlamamız gerekmiyor. Sadece Spark ile Pandas veri tipleri farklı olduğu için Pandas-Spark dönüşümünden önce Pandas DF veri tiplerinin hepsini astype(str) metoduyla stringe dönüştürmekte fayda var. Aksi halde hata alabiliriz.
filmListesiPandasDF.info()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 979 entries, 0 to 978 Data columns (total 6 columns): star_rating 979 non-null float64 title 979 non-null object content_rating 976 non-null object genre 979 non-null object duration 979 non-null int64 actors_list 979 non-null object dtypes: float64(1), int64(1), object(4) memory usage: 46.0+ KB
Pandas DF Veri Türlerini Dönüştürme
filmListesiPandasDF[['star_rating','title','content_rating','genre','duration','actors_list']] = filmListesiPandasDF[['star_rating','title','content_rating','genre','duration','actors_list']].astype(str) filmListesiPandasDF.info()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 979 entries, 0 to 978 Data columns (total 6 columns): star_rating 979 non-null object title 979 non-null object content_rating 979 non-null object genre 979 non-null object duration 979 non-null object actors_list 979 non-null object dtypes: object(6) memory usage: 46.0+ KB
Gördüğümüz gibi float ve integer gitti hepsi object oldu. Şimdi SparkDF oluşturalım.
filmListesiSparkDF = sqlContext.createDataFrame(filmListesiPandasDF) type(filmListesiSparkDF) pyspark.sql.dataframe.DataFrame
Yeni SparkDF’in şemasını yazdıralım:
filmListesiSparkDF.printSchema()
root |-- star_rating: string (nullable = true) |-- title: string (nullable = true) |-- content_rating: string (nullable = true) |-- genre: string (nullable = true) |-- duration: string (nullable = true) |-- actors_list: string (nullable = true)
Yukarıda gördüğümüz gibi her şey string. Bu şekilde Hive tablosuna kaydedeceğiz. Daha sonra hive tablosunda tekrar integer ve float türlerini ALTER TABLE komutuyla eski haline getireceğiz.
Spark DF’i Geçici Tablo Olarak Kaydetme
Hive tablosu olarak kaydetmeden önce SparkDF’i geçici tablo olarak kaydetmeliyiz.
filmListesiSparkDF.registerTempTable('imdbratings')
sqlContext.sql("create table imdbratings_hive_table as select * from imdbratings")Hive’e Girip Kaydettiğimiz Tabloyu Kontrol Etme ve Biraz Veri Mıncıklama

beeline -u jdbc:hive2://namenode:10000 komutuyla Hive’e erişiyorum. Yakın zamana kadar belki hala Hive’e hive komutuyla erişilebiliyordu ancak hive komutu artık kullanılmayacak (deprecated). Neyse Hive ile ilgili ayrı bir yazı oluşturacak kadar malzeme çıkar buradan kısa kesiyorum. Hive açıldığında karşımıza şu çıkar:
Buraya show tables; komutunu yazarız ve Hive bize varsayılan veri tabanındaki (default database) tabloları listeler.
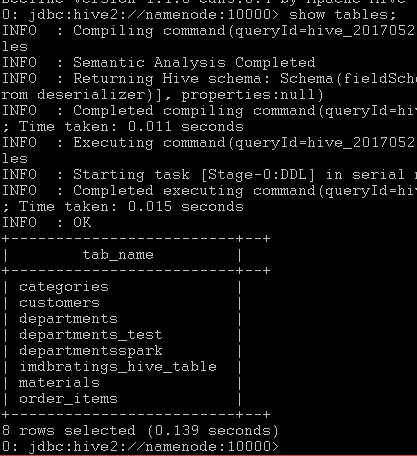
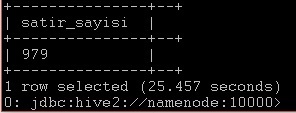
Biz en son tablomuzu imdbratings_hive_table olarak kaydetmiştik, yukarıdaki fotoğrafta gördüğümüz gibi aynı isimle tablo yerini almış. Şimdi basit bir kaç sorguyla tablo içi dolu mu yoksa sadece adı mı burada bakalım. Mesela satır sayısını bulalım. Komut:select count(*) as satir_sayisi from imdbratings_hive_table;
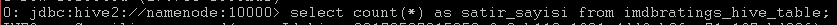
describe imdbratings_hive_table; komutuyla tablo yapısını inceleyelim:
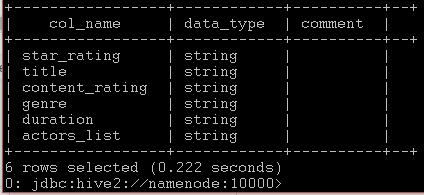
Yukarıda gördüğümüz gibi tüm veri türlerimiz string türünde. Şimdi orjinal verimizde star_rating float, duration ise integer idi. Biz hive üzerinde bunları eski haline döndürelim. Komutlarımız sırasıyla:
alter table imdbratings_hive_table change star_rating star_rating float; alter table imdbratings_hive_table change duration duration int;
Yalnız şunu unutmayalım bu komutlar disk üzerindeki veriyi değil, hive tablosunun metadatasını (şema) değiştirir. Sonucu tekrar describe ile görelim:

Evet star_rating float, duration ise integer olmuş.
Hive Tablosunu Spark’a Dataframe Olarak Alma
Şimdi ana bellekteki Pandas DF’i taa HDFS’e Hive tablosu olarak kaydettik ve verimizi sağlama aldık (amma sağlamcı milletiz ha 🙂 ). Buradan tekrar Spark ortamına veriyi çıkarıp her türlü işlemi yapabiliriz. Tekrar Jupyter Notebook’a geliyoruz.
imdbratingsHiveTabletoSparkDF = sqlContext.sql("select * from imdbratings_hive_table")
+-----------+--------------------+--------------+------+--------+--------------------+
|star_rating| title|content_rating| genre|duration| actors_list|
+-----------+--------------------+--------------+------+--------+--------------------+
| 9.3|The Shawshank Red...| R| Crime| 142|[u'Tim Robbins', ...|
| 9.2| The Godfather| R| Crime| 175|[u'Marlon Brando'...|
| 9.1|The Godfather: Pa...| R| Crime| 200|[u'Al Pacino', u'...|
| 9.0| The Dark Knight| PG-13|Action| 152|[u'Christian Bale...|
| 8.9| Pulp Fiction| R| Crime| 154|[u'John Travolta'...|
+-----------+--------------------+--------------+------+--------+--------------------+
only showing top 5 rowsEveet yolun sonuna geldik. Amma uzun bir yazı oldu, Jules Verne’nin 80 Günde Devri Alem’ini geçti 🙂 Başka bir yazıda buluşmak dileğiyle, veriyle kalın…