
![]()
Bu yazımda, son zamanlarda araştırmak ve iş yerimde projelerimde kullanmak istediğim bir algoritmayı sizlerle beraber incelemek ve bir uygulama yapmak istedim. Yazımın konusu NGBoost (Natural Gradient Boosting for Probabilistic Prediction), yani Olasılıksal Tahmin için Doğal Gradyan Artırımı.
NGBoost hakkında sizlerle öncelikle bazı bilgiler paylaşmak istiyorum. Bildiğiniz üzere NGBoost algoritmasının, Stanford Makine Öğrenmesi Grubu’ndan (2019 yılının başlarında) 7 araştırmacı tarafından makalesi [Tony Duan, Anand Avati, Daisy Yi Ding, Sanjay Basu, Andrew Y.
Ng, Alejandro Schuler, “NGBoost: Natural Gradient Boosting for Probabilistic Prediction”, 2019] yazıldı ve Github’a açık kaynak kodları yüklenerek hayatımıza girdi.
Birazdan daha detaylı açıklayacağım. Fakat makale incelediğinde NGBoost algoritması, birçok farklı noktada (makalede) olasılıksal tahminleme yöntemleri kullanıldığı için ciddi düzeyde istatistik, olasılık, koşullu olasılık, sabit varyans, dağılımlar, standart ve doğal gradyanlar ve boosting yöntemlerinin olduğunu, siz değerli okuyucularım da rahatlıkla anlayabilirsiniz.
İstatistik özgeçmişimin olmasıyla beraber bu algoritmaya karşı pozitif bir ön yargı hissettiğim doğrudur 🙂 Genç veri bilimci meslektaşlarıma ya da bu alana girmek isteyen dostlarıma, bu algoritma çok güzel bir örnek. Bana sık sık veri biliminde istatistik nerelerde kullanılıyor diye sorular geliyor. İşte bu algoritmada görüyorsunuz, anlatmaya gerek yok 🙂
Bir makine öğrenmesi modelinde öngörülerin belirsizliğini tahmin edebilmek için verinin dağılımını anlamak gerekir. Olasılıksal tahmin modelleri, modellerin tüm sonuçları üzerine olasılık dağılımları çıkarır. Böylece belirsizlik bir nevi ölçülebilir hale getirilebilir. Öngörücü belirsizlik tahmini; sağlık, aktüeryal bilim, hava tahmini veya mühendislik gibi alanlarda önemli bir istatistiksel yöntemdir.
NGBoost algıritması, regresyon problemlerinde olasılık tabanlı bir tahminleme yapmaktadır. Bu olasılıklar üzerine de gradyan inişlerinin kullanılması ve birleştirilmesiyle gerçekten tadından yenmez bir algoritma olduğu bir gerçek. Algoritma kısaca X vektörleri üzerinden Y değerlerinin beklenen değerleri üzerine odaklanarak çalışmakta. Yani f(x) = E(Y/X) fonksiyonunu bulmaya çalışıyor. Bu çalışma, araştırmacıya nokta tahminler üretiyor. Örneğin yarın hava sıcaklığının tahmini üzerine bir model geliştirilmek istendiğinde; beklenen olasılık ve beklenen değerler üzerine çalışacak, istatistiksel karar verme (olasılık dağılımları) süreçleri uygulayarak, boosting yöntemleri ile tahminler üretiliyor. İşte bu noktada NGBoost algoritması, P(Y/X) olasılık dağılımlarını bulma konusunda bizlere yardımcı oluyor.
Tüm bunlara ek olarak algoritma 3 bileşen kullanmakta. Bunlar; Taban Öğreniciler (Base Learners), Dağılım (Distribution) ve Skor Kuralı (Scoring Rule).

Çok kısaca bu terimlerin üzerinden geçelim. Taban Öğreniciler (yani base learners), hepimizin yakından bildiği topluluk öğrenme yöntemlerinin kullanıldığı, farklı model tahminlerinin birleştirildiği bir yöntemdir. Bu sebeple işlem maliyeti artmaktadır. Bu yöntemde en yaygın kullanılan algoritmaların başında Karar Ağaçları gelmektedir. Olasılık tabanlı bir çalışma yapılırken bilindiği üzere değişkenlerin dağılımı önemlidir (özellikle bağımlı – hedef değişkeninin). Makalede belirtildiği gibi Parametrik Olasılık Dağılımları yani Normal Dağılım, Laplace dağılımları algoritmaya belirtilmelidir. Bunun sebebi, dağılımın türü ile çıktının uyuşması gerekmektedir. Skor Kuralı ise kabaca, bilinen gerçek ile tahmin edilen gerçeğin ölçülebilir bir hale gelebilmesi için skor ataması yapılmasıdır. Tahminler başarılı ise iyi bir skor ataması yapılır. Genellikle En Çok Olabilirlik ile Sürekli Sıralanmış Olasılık Fonksiyonları kullanılmaktadır. Literatür incelendiğinde karşınıza sıklıkla En Çok Olabilirlik (MLE) fonksiyonu çıkacaktır.

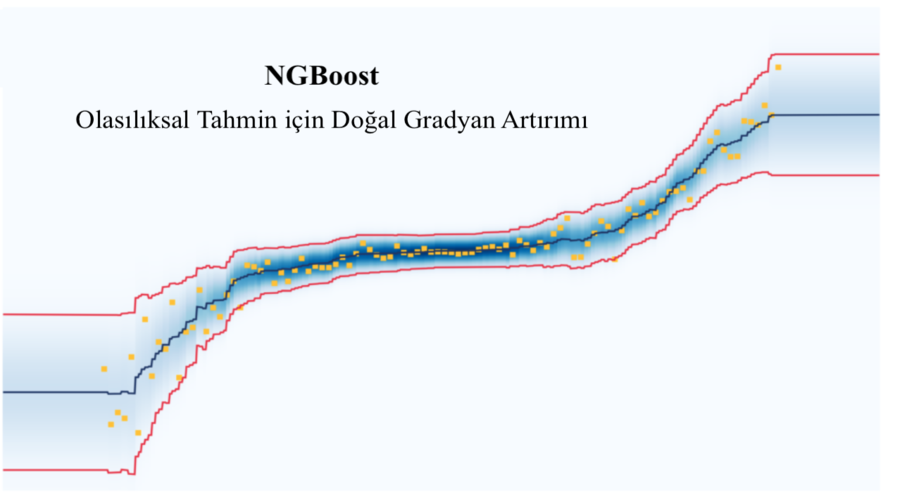
Makalede de yazıldığı gibi, standart gradyanların kullanımı, uç kenardaki değerin underfitting (az öğrenme) durumunda kaldığını ve doğal gradyan ile daha iyi bir genelleme yapılabildiği belirtilmiştir. Görselde; standart gradyan kullanıldığında, ortalama değerler varyansı etkilediği (diğer gözlemlere göre daha fazla) için daha iyi fit ettiği ancak uç değerlerin öğrenilemediği belirtilmiştir. Bu örnekte de aslında makine öğrenmesinde kullandığımız optimizasyon algoritmalarının önemi bir kez daha vurgulanmaktadır. NGBoost algoritmasında, standart gradyan algoritmalarının yerine doğal gradyan kullanılmaktadır.
Uygulamaya geçmeden önce NGBoost algoritması özetlenecek olursa, koşullu olasılık dağılımlarının parametrelerini kullanır ve boosting yaklaşımlarla tahmin eder. Olasılık tahminleri üzerinden nokta tahminleri verir. NGBoost, gerçek değerli çıktılar da dahil olmak üzere olasılıklı tahminler yoluyla gradyan artırımı ile öngörücü belirsizlik tahmini sağlar. Regresyonda, her olası sonuç için sürekli olasılık vektörü elde ederiz (olasılık yoğunluk fonksiyonu). Genel olarak konuşursak, X=x verildiğinde Y’nin dağılımı incelenir. Olasılıksal denetimli öğrenmede, x değerleri alınır ve Y üzerinde farklı değerlere karşılık gelen, Y’nin olasılığını gösteren bir dağılım döndürür NGBoost algoritması.
Hadi biraz kodlayalım…
UYGULAMA
NGBoost algoritmasının tanıtıldığı makalede de yazıldığı gibi olasılıksal tahminlemenin yaygın olarak kullanılabileceği bir veri seti üzerinde bu çalışmanın uygulamasını yapmak istedim. Nasıl bir veri seti üzerine çalışsam diye düşündüğümde aklıma Enerji Piyasalarının Tahminlenmesi geldi. Bu yazımda sizlerle beraber günlük hayatta kullandığımız enerjinin fiyatlandırma çalışmasını yapacağız. Verileri EPİAŞ – Günlük Rapor sayfasından sizler de alabilirsiniz.
Zaman serisi içeren veri setimizde hedef değişken olarak, siz kıymetli okuyucularımla SMF yani Sistem Marjinal Fiyatını tahminleyeceğiz. Uygulamada kısaca verileri manipüle ettikten sonra uç değerleri IQR (yani Interquartile Range) yöntemi ile sileceğiz. Ardından çeşitli değişkenler üreterek verimizi modelleyeceğiz. Bu süreçte; NGBoost, LGBM, Random Forest, Bagging, Extra Trees , AdaBoost ve Gradient Boost algoritmalarının performansını kıyaslayacağız.
Çalışmada kullanılan Python kütüphaneleri;
from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor, ExtraTreesReg ressor, AdaBoostRegressor, BaggingRegressor from sklearn.metrics import mean_squared_error, mean_absolute_error from ngboost.learners import default_tree_learner from sklearn.preprocessing import LabelEncoder from sklearn.tree import DecisionTreeRegressor from ngboost.distns import Normal, LogNormal from sklearn.linear_model import Ridge from ngboost.scores import CRPS, MLE from ngboost.ngboost import NGBoost from ngboost import NGBRegressor import matplotlib.pyplot as plt from collections import Counter from sklearn import metrics from pylab import rcParams import lightgbm as lgb import seaborn as sns import pandas as pd import numpy as np import warnings import os warnings.simplefilter(action='ignore', category=FutureWarning)
Kullanacağımız kütüphaneleri import ettikten sonra verimizi EPİAŞ üzerinden alalım ve üzerinde çalışalım. Öncelikle Zaman Serisi modellerini, geleneksel yöntemlerle yani ARMA – ARIMA – Holt Winters – Düzleştirme Yöntemleri – ARCH – GARCH gibi yöntemlerle analiz etmeyeceğiz. Bunun yerine Bagging ve Boosting yöntemlerini kullanacağız. Bu sebeple Zaman Serisi problemimizi programa anlatabilmek için tarih değişkenimizi çeşitli kırılımlara bölmemiz gerekmektedir (Ayın günü, Yılın günü, Haftanın günü, Günün saati, Yılın ayı vs.). Saatlik kırılımda olan veri setimiz, son 1 yıllın verisini içermekte.
def date_features(df, label=None):
df['hour'] = df['Saat'].dt.hour
df['dayofweek'] = df['Saat'].dt.dayofweek
df['month'] = df['Saat'].dt.month
df['dayofmonth'] = df['Saat'].dt.day
df['weekofyear'] = df['Saat'].dt.weekofyearVeri setimizi yükleyelim ve veri manipülasyonlarımızı yapalım. Verimiz 2 sütundan oluşmaktadır. Bunlar; Tarih ve hedef değişkenimiz (SMF (TL/MWh)).
cols = ["Saat","SMF (TL/MWh)"]
df = pd.read_csv("vbo_ngboost_enerji.csv", encoding = "iso-8859-9", usecols = cols)
df["Saat"] = pd.to_datetime(df["Saat"], format = "%d.%m.%Y %H:%M")
df["SMF (TL/MWh)"] = pd.to_numeric(df["SMF (TL/MWh)"].str.split(',', expand=True)[0])
date_features(df)Veri setimizi yükleyip çeşitli değişkenler oluşturduk. Bunlarla beraber bazı değişkenleri vurgulamak için bazı kategorik birleştirmeler yaptık. Buradaki amacımız modele bazı değişkenleri vurgulamak. Örneğin, ay ile saati birleştirdiğimde ayın 4. Günü saat öğlen 2 gibi.
df["hour_month"] = df.hour.astype(str) + "<em>" + df.dayofmonth.astype(str) df["dayofmonth_dayofweek"] = df.dayofmonth.astype(str) + "</em>" + df.dayofweek.astype(str)<br>df["hour_dayofweek"] = df.hour.astype(str) + "<em>" + df.dayofweek.astype(str) df["dayofmonth_weekofyear"] = df.dayofmonth.astype(str) + "</em>" + df.weekofyear.astype(str)<br>df["hour_weekofyear"] = df.hour.astype(str) + "_" + df.weekofyear.astype(str) df.head() df.info()

Şeklinde veri setimiz son halini almış oluyor. Değişkenlerimizin tiplerine bakalım.
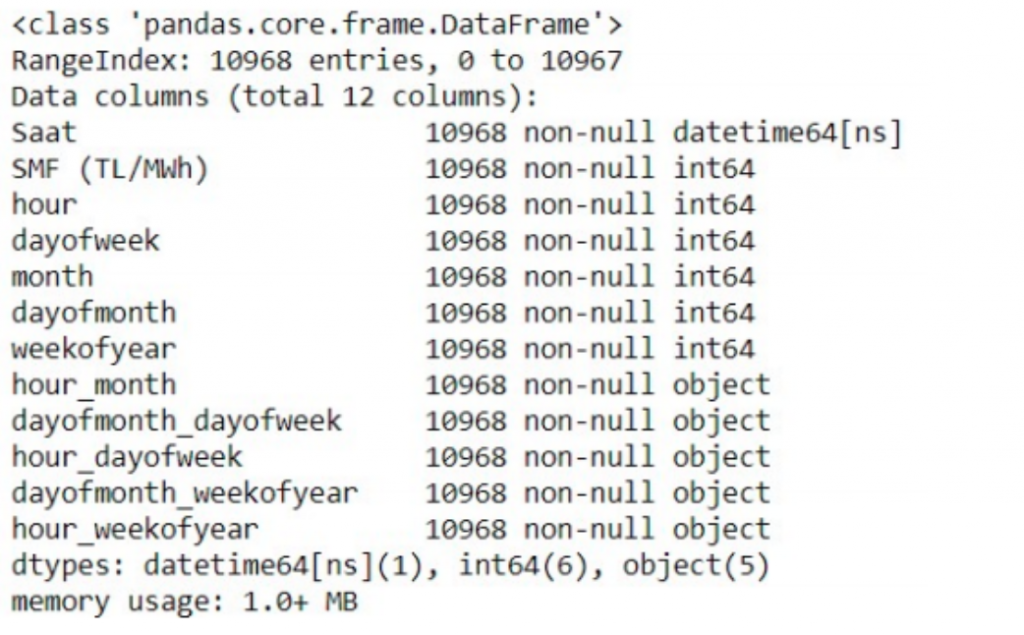
df.info() ile değişkenlerimizin türünü görmüş olduk. Son aşamada “object” olan değişkenlerimizi integer formatına çevirebilmek için “LabelEncder” yapıyorum.
for f in df.columns:
if df[f].dtype=='object':
df[f] = df[f].astype(str)
le = LabelEncoder()
le.fit(list(df[f]))
df[f] = le.transform(df[f])
df[f] = df[f].astype('int')
df.tail()
df.set_index('Saat')["SMF (TL/MWh)"].plot(figsize=(20,8))
Bağımlı (hedef) değişkenimizin dağılımını inceleyelim.
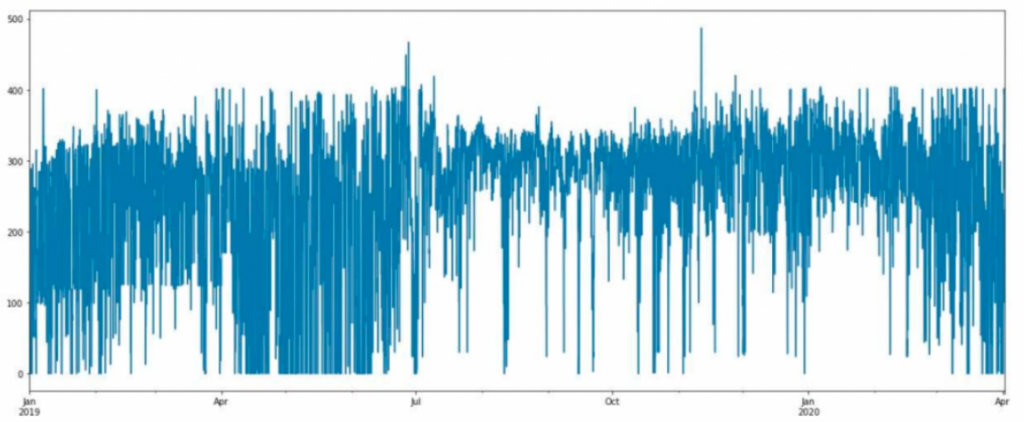
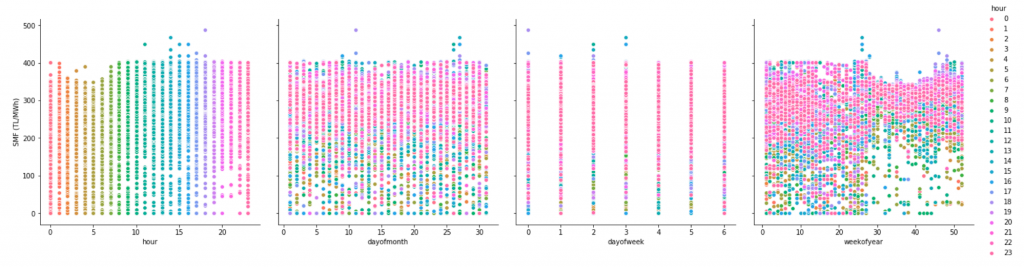
Standart sapması yüksek bir veri seti olduğu gözle görülüyor. Veri setimizde uç değerlerin varlığı da dikkatimizi çekmeli. Veri görselleştirmeye devam edelim.
sns.pairplot(data = df,
hue = 'hour',
x_vars=['hour','dayofmonth',
'dayofweek','weekofyear'],
y_vars='SMF (TL/MWh)',
height=5
)
Uç değerler için IQR yöntemini kullanmayı tercih ettim bu çalışmada. Ayrıca zaman serileri üzerine çeşitli uç değer belirleme algoritmaları mevcut. Onlar da kullanılabilir.
# Kaynak https://www.kaggle.com/frtgnn/visualization-techniques-using-yellowbricks
def detect_outliers(df,n,features):
"""
Takes a dataframe df of features and returns a list of the indices
corresponding to the observations containing more than n outliers according
to the Tukey method.
"""
outlier_indices = []
# iterate over features(columns)
for col in features:
# 1st quartile (25%)
Q1 = np.percentile(df[col], 25)
# 3rd quartile (75%)
Q3 = np.percentile(df[col],75)
# Interquartile range (IQR)
IQR = Q3 - Q1
# outlier step
outlier_step = 1.5 * IQR
# Determine a list of indices of outliers for feature col
outlier_list_col = df[(df[col] < Q1 - outlier_step) | (df[col] > Q3 + outlier_step )].index
# append the found outlier indices for col to the list of outlier indices
outlier_indices.extend(outlier_list_col)
# select observations containing more than 2 outliers
outlier_indices = Counter(outlier_indices)
multiple_outliers = list( k for k, v in outlier_indices.items() if v > n )
return multiple_outliers
uc_degerler = detect_outliers(df,0,["SMF (TL/MWh)"])
df.iloc[0:10] # İnceleyelim [0, 3, 4, 5, 6, 7, 8, 9, 10] numaralı gözlemler uç değerlermiş 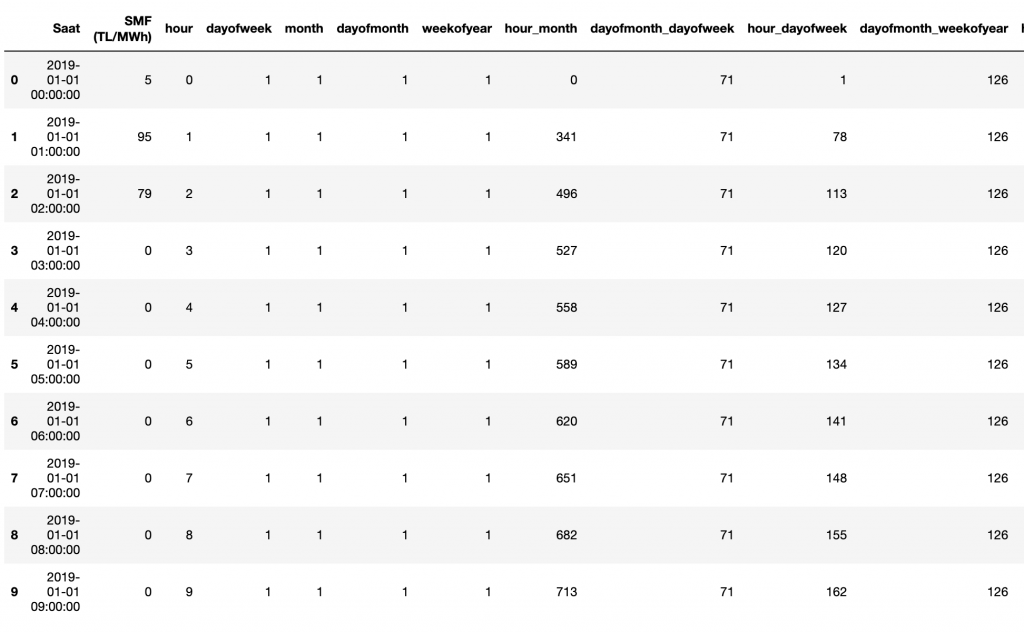
Ardından uç değerleri veri setinden çıkartalım.
df = df.drop(uc_degerler, axis = 0).reset_index(drop=True)
Bildiğiniz üzere zaman serileri çalışmalarında veriyi daha iyi modelleyebilmek için sıklıkla değişkenlerin gecikmeli değerleri kullanılmaktadır. Bu işlemlerle verinin barındığı yapı, model tarafından daha net anlaşılabilmektedir.
window_1 = [1,2,3,4,5,6,7,8,9,10,11,12,13,22,23,24,25,26,27,36,48]
for i in window_1:
df["lag_" + str(i) + "_SMF"] = df["SMF (TL/MWh)"].shift(i)Şimdi gecikmeli değişkenleri kullanarak basitçe farklı değişkenler oluşturalım.
lag_columns = ['lag_1_SMF','lag_2_SMF','lag_3_SMF','lag_4_SMF','lag_5_SMF', 'lag_6_SMF', 'lag_7_SMF','lag_8_SMF', 'lag_9_SMF', 'lag_10_SMF', 'lag_11_SMF', 'lag_12_SMF','lag_13_SMF',
'lag_22_SMF', 'lag_23_SMF', 'lag_24_SMF', 'lag_25_SMF','lag_26_SMF','lag_27_SMF','lag_36_SMF','lag_48_SMF']
kategorik = ['hour_month', 'dayofmonth_dayofweek', 'hour_dayofweek', 'dayofmonth_weekofyear',"hour_weekofyear",
'hour', 'dayofweek',"month","dayofmonth","weekofyear"]
for col in lag_columns:
for feat in kategorik:
df[f'{col}_mean_group_{feat}']=df[col]/df.groupby(feat)[col].transform('mean').astype("int")
df[f'{col}_max_group_{feat}']=df[col]/df.groupby(feat)[col].transform('max').astype("int")
df[f'{col}_min_group_{feat}']=df[col]/df.groupby(feat)[col].transform('min').astype("int")
# Yeni değişkenler ürettikten sonra veri setimizi Train-Test ve Validasyon olarak 3 farklı parçaya bölelim.
df = df.fillna(0)
test = df[df['Saat'] > "2020-03-10 23:00:00"]
test_ngb = df[df['Saat'] > "2020-03-10 23:00:00"]
y_test = test["SMF (TL/MWh)"]
X_test = test.drop(['SMF (TL/MWh)','Saat'], axis = 1)
train = df[df['Saat'] < "2020-02-10 23:00:00"]
train_nbg = df[df['Saat'] < "2020-02-10 23:00:00"]
y_train = train["SMF (TL/MWh)"]
X_train = train.drop(['SMF (TL/MWh)','Saat'], axis = 1)
valid = df[(df['Saat'] >= "2020-02-10 23:00:00") & (df['Saat'] <= "2020-03-10 23:00:00")]
valid_ngb = df[(df['Saat'] >= "2020-02-10 23:00:00") & (df['Saat'] <= "2020-03-10 23:00:00")]
y_valid = valid["SMF (TL/MWh)"]
X_valid = valid.drop(['SMF (TL/MWh)','Saat'], axis = 1)LGBM Modeli
trainLGB = lgb.Dataset(X_train, label = y_train)
validLGB = lgb.Dataset(X_valid, label = y_valid)
lgb_param = {
'objective':'rmse',
'num_leaves' : 31,
'learning_rate': 0.005,
'max_bin': 155,
'max_depth': 10,
'min_child_weight' : 250,
'feature_fraction': 0.8,
'bagging_fraction': 0.9,
'nthread': -1,
'bagging_freq': 24,
'n_jobs':-1,
'reg_lambda' : 10,
'reg_alpha' : 20
}
num_round = 100000
evals_result = {}
clf = lgb.train(lgb_param, trainLGB, num_boost_round = 100000, valid_sets=[trainLGB, validLGB], verbose_eval=200,
categorical_feature = kategorik, early_stopping_rounds = 10, evals_result=evals_result)
rcParams["figure.figsize"] = 17,12
lgb.plot_metric(evals_result)
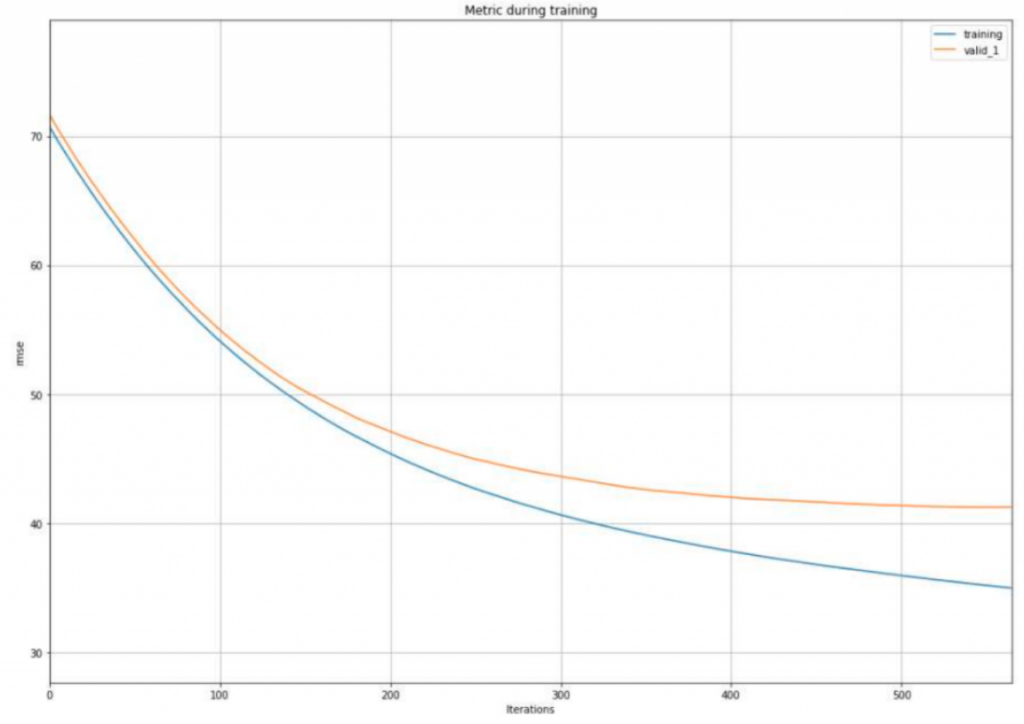
Verimizde Overfit olduğu görülmektedir. Sizler hiper parametreler ile oynayarak ve değişkenler üreterek daha başarılı çalışmalar yapabilirsiniz.
import warnings
warnings.simplefilter(action='ignore', category=FutureWarning)
def plotImp(model, X , num = 20):
feature_imp = pd.DataFrame({'Value':model.feature_importance(),'Feature':X.columns})
plt.figure(figsize=(13, 7))
sns.set(font_scale = 1.2)
sns.barplot(x="Value", y="Feature", data=feature_imp.sort_values(by="Value", ascending=False)[0:num])
plt.title('LightGBM Features (avg over folds)')
plt.tight_layout()
plt.show()
plotImp(clf, X_train)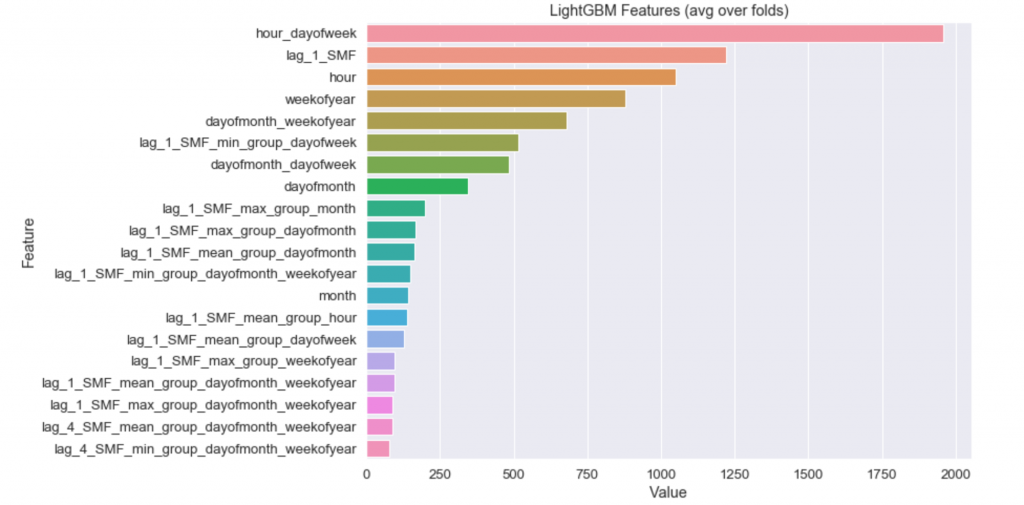
Geliştirdiğiniz herhangi bir modeli kurduktan sonra “parametre önemi grafiği” üzerine düşünmek gerekmektedir. Bu grafik bizlere ciddi şekilde verinin içerdiği yapıyı ve problemi anlatmaktadır. En önemli değişkenimiz ise haftanın gününün saati. Yani Cuma akşam saat 8 ile Salı günü öğlen 2 arasında bir fark olduğu anlaşılmaktadır. Model, bu kategorik bilginin hedef değişkeninin açıklanmasında ve tahmininde önemli olduğu görmüştür. 2. önemli değişkenimizin ise 1 gecikmeli hedef değişkenimiz olduğu görülmekte. Buradan, verimizde otokorelasyon olduğu anlaşılabilmektedir. Tahmin başarılarımıza bakalım.
def percentage_error(actual, predicted):
res = np.empty(actual.shape)
for j in range(actual.shape[0]):
if actual[j] != 0:
res[j] = (actual[j] - predicted[j]) / actual[j]
else:
res[j] = predicted[j] / np.mean(actual)
return res
def mean_absolute_percentage_error(y_true, y_pred):
return np.mean(np.abs(percentage_error(np.asarray(y_true), np.asarray(y_pred)))) * 100
y = clf.predict(X_valid)
y_ = clf.predict(X_test)
print(' RMSE Valid Data {}\n'.format(np.sqrt(mean_squared_error(y_valid, y))))
print(' RMSE Test Data {}\n'.format(np.sqrt(mean_squared_error(y_test, y_))))RMSE Valid Data 41.25
RMSE Test Data 59.3
LGBM algoritması ile validasyon veri setimizden 41 RMSE değerini alıyorken, test verimizden 59 RMSE hata ile tahmin ürettiğimizi görüyoruz.
NGBoost Modeli
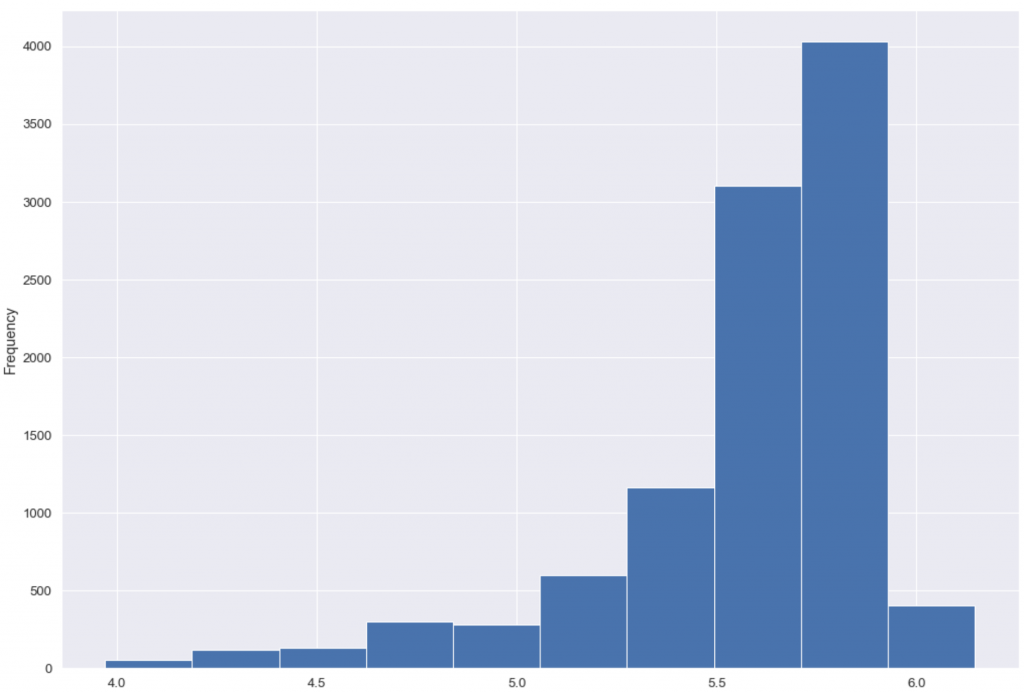
Daha önce belirtildiği gibi NGBoost modelleri için hedef değişkenin dağılımı önemlidir. Hedef değişkenin logaritması alındığında yaklaşık normal dağıldığı görülmektedir.
np.log(df["SMF (TL/MWh)"]).plot(kind = "hist")
default_tree_learner_1 = DecisionTreeRegressor(
criterion="friedman_mse",
min_samples_split=2,
min_samples_leaf=1,
min_weight_fraction_leaf=0.0,
splitter="best",
random_state=None,
max_depth=5
)
default_linear_learner_1 = Ridge(alpha=0.0, random_state=None)
ngb = NGBRegressor(
Dist=LogNormal,
Score=MLE,
Base=default_tree_learner_1,
n_estimators=500,
learning_rate=0.01,
minibatch_frac=1,
verbose=True,
verbose_eval=50)Buradan da görüldüğü üzere “DecisionTreeRegressor” üzerinden hiper parametreler düzenlenerek NGBoost modelinizi iyileştirebilirsiniz.
%%time
X = np.array(train_nbg.iloc[:,2:train_nbg.shape[1]])
y = np.array(train_nbg["SMF (TL/MWh)"])
ngb.fit(X,y,
X_val = np.array(valid_ngb.iloc[:,2:valid_ngb.shape[1]]),
Y_val = np.array(valid_ngb["SMF (TL/MWh)"]), early_stopping_rounds= 30)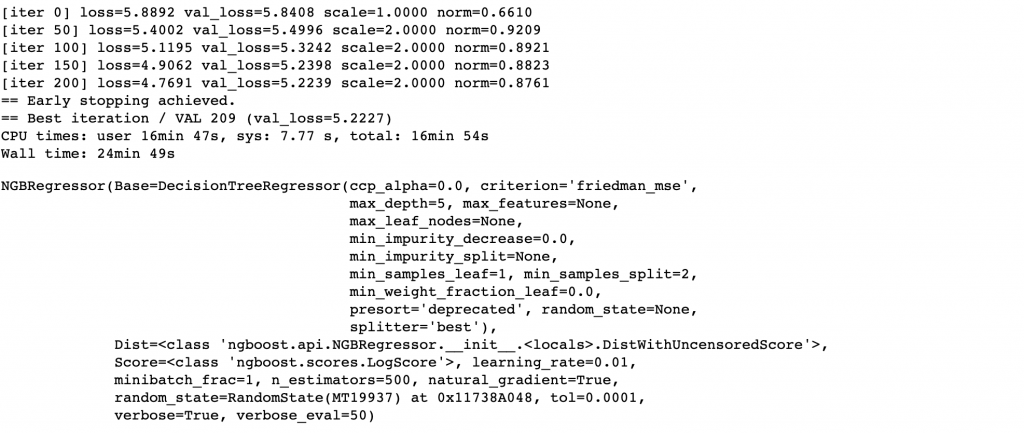
Modelimizi kurduk. Şimdi validasyon ve test verimizin tahmin hatalarına bakalım.
Y_valid_preds = ngb.predict(X_valid)
y_pred_dist = ngb.pred_dist(X_valid)
Y_test_preds = ngb.predict(X_test)
Y_test_dists = ngb.pred_dist(X_test)
y_valid_lgbm = clf.predict(X_valid)
y_test_lgbm = clf.predict(X_test)
print('LGBM - RMSE Valid Data {}\n'.format(np.sqrt(mean_squared_error(y_valid, y_valid_lgbm))))
print('LGBM - RMSE Test Data {}\n'.format(np.sqrt(mean_squared_error(y_test, y_test_lgbm))))
print('NGBOOST - RMSE Valid Data {}\n'.format(np.sqrt(mean_squared_error(y_valid, Y_valid_preds))))
print('NGBOOST - RMSE Test Data {}\n'.format(np.sqrt(mean_squared_error(y_test, Y_test_preds))))LGBM – RMSE Valid Data 41.25
LGBM – RMSE Test Data 59.30
NGBOOST – RMSE Valid Data 42.32
NGBOOST – RMSE Test Data 58.58
Görüldüğü üzere LGBM modelinden daha başarılı bir sonuç verdiği görülmektedir. Şimdi koşullu olasılık dağılımını çizdirelim ve 2 sigma değeri ile çarparak tahminlerimizi olasılık dağılımına göre alabileceği aralıklara bakalım.
# Koşullu olasılık dağılımını çizdirelim
x_lim = (0, 500)
X_grid = np.linspace(*x_lim, 669).reshape(-1, 1)
y_pred_dist = ngb.pred_dist(X_valid, max_iter=ngb.best_val_loss_itr) # Koşullu olasılık dağılımları (Predict the conditional distribution of Y at the points X=x)
sigmas = y_pred_dist.params['s']
scales = y_pred_dist.params['scale']
mus = np.log(scales)
y_pred_plus = scales + 2*mus
y_pred_minus = scales - 2*mus
fig = plt.figure(figsize=(20, 8))
ax2= fig.add_subplot(111)
ax2.plot(X_grid, Y_valid_preds, color='blue', alpha=0.8, label='pred')
ax2.fill_between(X_grid.reshape(-1), y_pred_plus, y_pred_minus, alpha=0.8, color='grey')
ax2.set_title('Koşullu Olasılık - Valid')
ax2.legend()
plt.show()
Validasyon veri setimizin tahminleri ile 2 sigma değerlerini toplayıp çıkartarak tahminlerimizin koşullu olasılık dağılımını görmüş olduk. NGBoost kütüphanesinden “pred_dist” fonksiyonu ile her tahminin ayrı ayrı koşullu olasılık dağılımlarını görebilirsiniz.
Şimdi farklı modeller kuralım ve modellerimizi kıyaslayalım.
def modeller():
rf = RandomForestRegressor()
bag = BaggingRegressor()
extra = ExtraTreesRegressor()
ada = AdaBoostRegressor()
grad = GradientBoostingRegressor()
Regressor_list = [rf,bag,extra,ada,grad]
Regressor_name_list = ['Random Forests','Bagging','Extra Trees','AdaBoost','Gradient Boost']
return Regressor_list, Regressor_name_list
def print_evaluation_metrics(trained_model,trained_model_name,X_test,y_test):
print ('--------- Model : ', trained_model_name ,' ---------\n')
predicted_values = trained_model.predict(X_test)
print ("Mean Absolute Error : ", metrics.mean_absolute_error(y_test,predicted_values))
print ("Median Absolute Error : ", metrics.median_absolute_error(y_test,predicted_values))
print ("Mean Squared Error : ", metrics.mean_squared_error(y_test,predicted_values))
print ("Root Mean Squared Error : ", np.sqrt(metrics.mean_squared_error(y_test,predicted_values)))
print ("R2 Score : ", metrics.r2_score(y_test,predicted_values))
print ("---------------------------------------\n")
Regressor_list, Regressor_name_list = modeller()
for regressor,regressor_name in zip(Regressor_list,Regressor_name_list):
regressor.fit(X_train,y_train)
print_evaluation_metrics(regressor,regressor_name,X_test,y_test)
Böylelikle uygulamamızı tamamlamış olduk. Gradient Boost modeli, veri setimiz için en başarılı sonucu vermesiyle beraber NGBoost algoritması, LGBM’e göre daha başarılı sonuç verdi.
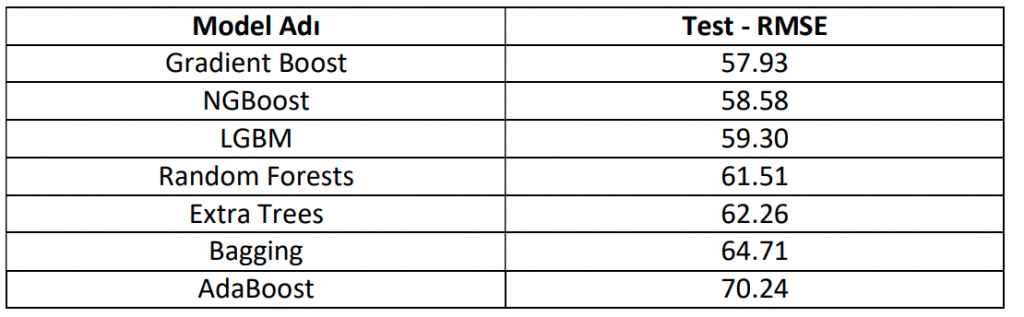
Bu çalışma ile beraber NGBoost algoritmasını incelemiş olduk. Bu algoritma 2019 yılında geliştirilmiş olup, Türkçe literatür konusunda eksikler vardır. Lisansüstü öğrencilerinin araştırmaları için araştırmaya uygun bir alandır.
Saygılarımla
Varsayımlarınızın sağlanması dileğiyle,
Veri ile kalın, Hoşça kalın…
Kaynakça
https://medium.com/kaveai/ngboost-olas%C4%B1l%C4%B1ksal-tahmin-i%C3%A7in-do%C4%9Falgradyan-art%C4%B1r%C4%B1m%C4%B1-db91dc06f37a
https://arxiv.org/pdf/1910.03225.pdf (Tony Duan, Anand Avati, Daisy Yi Ding, Sanjay Basu, Andrew Y.
Ng, Alejandro Schuler, “NGBoost: Natural Gradient Boosting for Probabilistic Prediction”, (2019))
https://stanfordmlgroup.github.io/projects/ngboost/
https://dkopczyk.quantee.co.uk/ngboost-explained/
https://towardsdatascience.com/interpreting-the-probabilistic-predictions-from-ngboost868d6f3770b2
Bir Utku klasiği olmuş 🙂
Çok teşekkürler 🙂
Güzel çalışma, teşekkürler