

![]()
Herkese merhabalar! Veri bilimi okulunun bir parçası olmaktan ve siz değerli okurlarla bildiğim ve öğrenmekte olduğum konuları paylaşma fırsatı yakalamaktan dolayı çok mutluyum. Umarım sizin için yararlı bir okuma olur.
Yazılarımda MS SQL Server, MS SSRS, diğer iş zekası uygulamalarından ve endüstriyel dijital dönüşüm konularından bahsetmeye çalışacağım.
Bu yazımda ise MS SQL Server sorgularının söz diziminden ve performans ölçümünden bahsedeceğim.
MS SQL Server Nedir?
MS SQL Server’dan çok kısa bahsedecek olursak bir ilişkisel veri tabanı yönetim sistemidir.
Bir veritabanı sunucusu olarak ana görevi, verileri depolamak ve diğer yazılım uygulamaları tarafından talep edildiğinde bu verileri dönmektir. Depolanan veriler yazılan sorgular sayesinde istenildiğinde çekilebilir.
![]()
Şekil-1: MS SQL Server
Sorgu Söz Dizimi Nedir?
MS SQL’in belli bir kod dizimi vardır ve sorgu yazarken bu dizime uymamız gerekir. Eğer bu dizimde bir yanlış yaparsak sorgu çalışmaz, hata alırız ve herhangi bir veri dönmez. Fakat yazılması gereken sorgu söz dizimi ile veritabanındaki işleyiş birbirinden farklıdır. Dolayısıyla MS SQL, komutları bizim yazdığımız sırayla işlemez.
Bunu SQL sorguları üzerinden inceleyelim.

Başlangıç sorgumuz Depremler tablosundan 9’dan büyük şiddetteki depremleri büyükten küçüğe Ulke, Sehir ve Şiddet alanlarını gösterecek şekilde olsun.
SELECT Ulke, Sehir, Siddet FROM Depremler WHERE Siddet >= 9 ORDER BY Siddet DESC;
Yukarıdaki sorguda da görüldüğü gibi sorgu söz dizimi;
- SELECT
- FROM
- WHERE
- ORDER BY
MS SQL’in işleme sırası;
- FROM
- WHERE
- SELECT
- ORDER BY
Öncelikle FROM işlemi çalışır veri kaynağından belirtilen tablo veya view çekilir.
İkinci olarak filtreleme koşullarının yazıldığı WHERE işlenir.
Veriler çekilip filtrelendikten sonra veritabanına hangi alanların döndürüleceği SELECT ile işlenir.
Son olarak da gerekli tüm satır ve sütunlar oluştuktan sonra ORDER BY ile sıralama işlevi gerçekleştirilir.
MS SQL’in mantıksal sorgu işleme dizimi genel olarak aşağıdaki gibidir:
- From
- On
- Join
- Where
- Group By
- Having
- Select
- Distinct
- Order By
- Top
Sorgu yazımında en üstte olan SELECT, görüldüğü gibi MS SQL tarafından okunma sırasında pek de üst taraflarda değil.
SELECT’den önce işlenenleri gözden geçirdiğimizde verinin bulunması, birleştirilmesi, filtrelenmesi ve gruplanması gibi bir çok aksiyon yapılıyor. Bunların hepsi MS SQL için temel işlemlerdir.
SELECT’den sonraki işlemler, daha çok çıkarılan verilerin üzerinde yapılan işlemlerdir. Bu işlemler veri tabanı işleme kaynakları açısından daha maliyetlidir.
Sonuç olarak MS SQL’in sorguları işleme sırasını anlamak, bir sorgunun neden yürütülemediğini belirlemeye ve sorguyu performans için optimize etmenin yollarına aramaya yardımcı olacaktır. Şimdi gelelim sorgu performansının ölçülmesi ve optimize edilmesine.
MS SQL Server’da Sorgu Performansının Ölçülmesi
SQL Server’da sorgu performansını ölçmek için kullanılabilecek birçok araç ve komut vardır.
Sorgu süresini ölçmenin bir yolu, sorguyu pars etmek, derlemek ve yürütmek için gereken milisaniyeleri bildiren STATISTICS TIME komutudur. Sorguları çalıştırdıktan sonra ‘STATISTICSS TIME’ ı ‘Messages’ larda görebilmemiz için SSMS’de Query/Query Options/Execution/Advanced ‘e girerek ‘SET STATISTICS TIME’ ‘ı tiklememiz gerekir. Bu işlem sonrasında her sorgu çalıştırdığınızda ‘Messages’ altında aşağıda Şekil-2’de gibi bir çıktı ile karşılaşacaksınız.
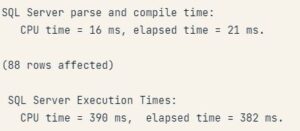
Şekil-2: SQL Statistics Time
STATISTICS TIME‘ın çıktısında birkaç tane zaman istatistiği vardır fakat biz SQL Server Execution Times altındaki ‘CPU Time’ ve ‘elaspsed time’ a odaklanacağız.
“CPU Time” veritabanı sunucusunun işlemcileri tarafından sorguyu işlemek için geçen gerçek süredir,
“elapsed time” ise sorgunun yürütülmesinden tüm sonuçların bize geri döndürülmesine kadar geçen toplam süredir.
Şimdi 2 örnek sorgu üzerinde Statistics Time‘ı deneyelim ve küçük iyileştirmelerle nasıl optimize edilebileceğini inceleyelim.
İnceleyeceğimiz iki sorgu da Ulkeler ve Sehirler olmak üzere 2 adet tablo kullanır. 2 sorgunun amacı da başkentinin 2017 nüfusu 1000000’dan fazla olan ülkeleri, bölge ve başkent alanları ile birlikte döndürmektir.
- Sorgu
SELECT Bolge,
Ulke,
Baskent
FROM Ulkeler
WHERE Baskent IN
(SELECT Sehir
FROM Sehirler) -- 1. Alt sorgu
AND Baskent IN
(SELECT Sehir -- 2. Alt sorgu
FROM Sehirler
WHERE Nufus2017 > 1000000);
- Sorgu Statistics Time:

Şekil-3: 1. Sorgunun Statistics Time
2. Sorgu
SELECT Bolge,
Ulke,
Baskent
FROM Ulkeler U
WHERE EXISTS
(SELECT 1
FROM Sehirler S
WHERE U.Baskent = S.Sehir
AND Nufus2017 > 1000000);
2. Sorgu Statistics Time

Şekil-4: 2. Sorgunun Statistics Time
Sorguların Statistics Time çıktılarını karşılaştırırsak 2. sorgunun çok daha hızlı bir şekilde çalıştığını görülebiliyoruz. Veritabanı işlemcilerinde 1 milisaniyeden daha az zaman harcanmış ve toplam yürütülme zamanı sadece 2 milisaniye. 1. sorgunun çok daha yavaş çalışmasının sebebi WHERE içerisindeki 2 adet alt sorgudur. İlk sorguda, her bir alt sorgu, daha fazla işlem yapmadan önce tüm sonuçları toplamalıdır, ikinci sorgu ise, bir eşleşme olduğunda alt sorguyu aramayı durduran EXISTS kullanır bu sebeple çok daha verimlidir.
Bir sorgu için Statistics Time kullanırken bakılan Elapsed Time ile CPU Time’ın karşılaştırması ise aşağıdaki tablodaki gibidir.

Şekil-5: Elapsed Time vs CPU Time
Çoğu durumda istenen sonuç, sorgunun çıktılarını bize olabildiğince hızlı döndürebilmektir. Bu durumlarda Elapsed Time kullanılacak en iyi ölçüdür.
Bir sonraki yazımda görüşmek üzere!
Kaynakça:
https://app.datacamp.com/learn/courses/improving-query-performance-in-sql-server