

![]()
Merhabalar, bugünkü yazımda sizlere LSTM Ağları ile nasıl şarkı besteleyip, bunu selenium adlı kütüphane ile canlı olarak çalabileceğimizden bahsedeceğim. Yazının içeriği şu şekilde;
- LSTM Ağları Nedir?
- Selenium Nedir?
- Pythonda Keyboard ve Pynput Kütüphaneleri?
- Next Character Prediction Nedir?
- LSTM ile Şarkı Bestelemek
- Nota Verilerinin Alınması
- Verilerin İşlenmesi
- X ve Y’lerinin Belirlenmesi
- Verinin Model için Hazırlanması
- Modelin Kurulması ve Ayarları
- Modelin İlk Testleri
- Bestelenen Şarkının Selenium Yardımıyla Çalınması
- Sistem Nasıl Çalışıyor?
- Nota-Keyboard Bağlantısı Nedir?
- Nota:Keyboard Dictionarysinin Oluşturulması
- Selenium ile Siteye Bağlanma ve Keyboard ile Notaların Arasında Çalışacak Fonksiyonların Yazılması
- Verisetinden Seed Seçerek ilk Çıktıların Alınması ve Çalınması
- Girdilerin Kullanıcı Tarafından Verilip İlk Çıktıların Alınması
- Çıkan Sonuçlar
- Bütün Kodlar
İşimiz bittiğinde şunlara benzer birşey elde edeceğiz ;
LSTM(Long-Short-Time-Memory) Ağları Nedir?
- Uzun kısa süreli bellek (LSTM), değerleri rastgele aralıklarla hatırlayan bir tekrarlayan sinir ağı (RNN) bir mimarisidir. Öğrenilen ilerleme kaydedildiğinde saklanan değerler değiştirilmez. RNN’ler, nöronlar arasında ileri ve geri bağlantılara izin verir.[1]
- Daha detaylı bilgi için LSTM ile Dolar/TL Kuru Tahmini yazıma göz atabilirsiniz.
- Projede kullanmak için LSTM’i keras üzerinden çağıracağız. Bunları yüklemek için cmd ekranına şu kodları yazmanız gerekiyor ;
pip install keras pip install tensorflow
Selenium Nedir?
- Selenium Web testleri için kullanılan bir python kütüphanesi. Selenium sayesinde yazacağınız bot insan gibi davranabiliyor. Bu sayede bazı siteler tarafından direk sitenin yüklenmesiyle gelmeyip, siz bir şeylere tıkladıkça gelen şeyleri çekebiliyorsunuz. Biz bu projede selenium’u web sitesini açarken kullanıyoruz. Burada kritik birkaç şey var;
- Selenium’u kullanırken chromedriver.exe adlı taşınabilir google chrome üzerinden açılışı yapıyoruz. Bu yüzden bu dosyayı kodlarınızla aynı yerde saklamanız gerekiyor. Bu dosyayı TIKLAYARAK indirebilirsiniz. Onun dışında selenium’u yüklemek için ;
pip install selenium
Pythonda Keyboard ve Pynput Kütüphaneleri
- Bizim için en kritik kütüphaneler bunlar sebebi ise lstm tarafından besteleyeceğimiz şarkıyı bu kütüphaneler yardımıyla çalacağız. Bu kütüphanelerin ikiside klavyede yaptığınız herşeyi yazdığınız kod ile yapabilmemizi sağlıyor. Bu kütüphaneleri indirmek için yapmanız gereken şey cmd ekranına şu kodu yazmak :
pip install keyboard pip install pynput
Next Character Prediction Nedir?
Next Character Prediction, yazılan önceki kelimelere göre yazılacak diğer kelimeyi tahmin etmeye deniyor. Örnek olarak telefonlarınızda mesaj yazarken, mesajın tamamlanması ve klavyenin üzerinde cümleyi devam ettirecek yeni kelimeler önerilmesi next character prediction’a örnektir.
LSTM ile Şarkı Bestelemek
Nota Verilerinin Alınması
Nota verilerini Buradan Tek tek şarkılara girerek aldık. Sadece notaları aldık, burada satır aralarında bekleme kısımlarına sleep, şarkının sonuna da new taglarını koyduk. Bu kısımda verileri elle almada yardımcı olan Feyza Zeynep Salam‘a teşekkürler. Nota verilerine TIKLAYARAK erişebilirsiniz.
Verilerin İşlenmesi
Bu kısımda elimizdeki veri şuna benziyordu;
Em G Em G Em G Em G Em G Em G Em G Em G Em G Em G
Burada yapmamız gereken birkaç işlem var, öncelikle boşlukları atmalıyız. Ardından bütün notaları bir listenin elemanı haline getirmeliyiz. Onu da şu aşağıdaki kod ile yapacağız.
Öncelikle kütüphanelerimizi ve verisetimizi tanıtalım.
# Ana Kütüphaneler
import numpy
import sys
# Keras and LSTM
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
from keras.layers import LSTM
from keras.callbacks import ModelCheckpoint
from keras.utils import np_utils
# Txt Dosyasının Açılması
myfile = open("nirvananota.txt","r")
#Burada satır satır olan verinin her satırını listenin bir elemanı yapıyoruz.
data = myfile.read().split("\n")Şimdi ise verimizi listenin elemanları haline getirip boş aralıkları atalım.
# Boşlukların temizlenmesi bütün notaların tek tek eleman olarak alınması
clean = []
for i in range(0,len(data)):
#Bu kısımda boşluk olan elemanları tek tek düşürüyoruz.
clean = clean + [x for x in data[i].split(" ") if str(x) != '']
clean[:10]Bütün notaları sayı haline getirmemiz gerekiyor bunun için her notaya bir sayı atanan bir dictionary oluşturacağız.
# Karakterler için Dictionary Oluşturulması chars = sorted(list(set(clean))) char_to_int = dict((c, i) for i, c in enumerate(chars)) char_to_int
Çıktımız :
{'A': 0,
'A#': 1,
'A#7': 2,
'A7': 3,
'Ab': 4,
'Am': 5,
'B': 6,
'B7': 7,
'Bm7': 8,
'C': 9,
'C#': 10,
'C#7': 11,
'C#m': 12,
'C7': 13,
'D': 14,
'D#7': 15,
'D7': 16,
'Dm': 17,
'Dm#': 18,
'E': 19,
'E7': 20,
'Em': 21,
'EmC': 22,
'F': 23,
'F#': 24,
'F#7': 25,
'F#m': 26,
'F7': 27,
'G': 28,
'G#': 29,
'G#7': 30,
'G#m': 31,
'G#m,': 32,
'G7': 33,
'new': 34,
'sleep': 35}X ve Y’lerinin Belirlenmesi
Şimdi ise en önemli kısıma geldik, notaları X ve Y şeklinde belirlemeye. Örneğin, 10 Notalık bir şarkı düşünelim. Buradaki mantık şu şekilde oluyor;
E G C C7 B7 Am Em G C ise ;
E G C C7 B7 Am Em G –> C şeklinde seçiliyor. Burada “E G C C7 B7 Am Em G” bizim X’imiz C bizim Y’miz oluyor.
Evet şimdi bunu verimize uygulayalım;
# Notaların birbirlerine bağlanması örneğin ;
# E7 G E C --> E7 G E TARGET/C
# Burada 10 notada bir yapılacağını söylüyoruz. Yani X-9 Y-1 Olacak şekilde isterseniz 50-100 veya kafanıza göre bir sayı atayabilirsiniz ama bu örnek sayınızın değişimini etkiler.
seq_length = 10
dataX = []
dataY = []
for i in range(0, n_chars - seq_length, 1):
seq_in = clean[i:i + seq_length]
seq_out = clean[i + seq_length]
dataX.append([char_to_int[char] for char in seq_in])
dataY.append(char_to_int[seq_out])
# Bu kısımda toplamda kaç adet örneğimiz olduğunu yazdırıyoruz.
n_patterns = len(dataX)
print("Total Patterns: ", n_patterns)Bu projede totalde 2559 Örnek ile çalışıyoruz.
Verinin Model için Hazırlanması
Bildiğiniz gibi derin öğrenme çalışmalarında algoritmamızdan daha iyi sonuç almak için veriyi normalize etmeliyiz.
X = np.reshape(dataX, (n_patterns, seq_length, 1)) # Normalize Etmek. X = X / float(n_vocab) # Y değişkeni için One Hot Encoding Yapıyoruz. y = np_utils.to_categorical(dataY)
Evet şimdi modelimizi kurabiliriz.
Modelin Kurulması ve Ayarları
Burada model yapısı olarak 3 Hidden Layerlı bir model kullanacağız. Burada hidden_size olarak 512, 100 epoch ve batch_size olarak 5 belirledik. Bu parametrelerin ne olduğunu hiç duymadıysanız bilgilenmek için BURAYA bakabilirsiniz.
Modelimizin Yapısı ;
model = Sequential()
model.add(LSTM(512, return_sequences=True,
input_shape=(X.shape[1], X.shape[2])))
model.add(Dropout(0.5))
model.add(LSTM(512, return_sequences=True))
model.add(Dropout(0.5))
model.add(LSTM(512))
model.add(Dropout(0.5))
model.add(Dense(y.shape[1], activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam')Modeli fit etmeden önce bu kısımda modelin ağırlıklarını kaydetmek için şu şekilde bir metod uyguluyoruz ;
- Eğer yeni epochta(period) şu ana kadarki en düşük loss(hata oranı) varsa onun ağırlıklarını kaydet yoksa devam et.
filepath="stacked-weights-improvement-{epoch:02d}-{loss:.4f}.hdf5"
checkpoint = ModelCheckpoint(filepath, monitor='loss', verbose=1, save_best_only=True, mode='min')
callbacks_list = [checkpoint]Evet şimdi modelimizi fit edelim.
model.fit(X, y, epochs=100, batch_size=5, callbacks=callbacks_list)
Çıktılarımız da şu şekilde;
Epoch 1/100 2559/2559 [==============================] - 84s 33ms/step - loss: 3.2784 Epoch 00001: loss improved from inf to 3.27843, saving model to stacked-weights-improvement-01-3.2784.hdf5 Epoch 2/100 2559/2559 [==============================] - 79s 31ms/step - loss: 3.2096 Epoch 00002: loss improved from 3.27843 to 3.20958, saving model to stacked-weights-improvement-02-3.2096.hdf5 Epoch 3/100 2559/2559 [==============================] - 78s 30ms/step - loss: 3.2259 Epoch 00003: loss did not improve from 3.20958 Epoch 4/100 2559/2559 [==============================] - 79s 31ms/step - loss: 3.1036 Epoch 00004: loss improved from 3.20958 to 3.10363, saving model to stacked-weights-improvement-04-3.1036.hdf5 Epoch 5/100 2559/2559 [==============================] - 78s 30ms/step - loss: 2.9297 Epoch 00090: loss improved from 0.24666 to 0.23598, saving model to stacked-weights-improvement-90-0.2360.hdf5 Epoch 91/100 2559/2559 [==============================] - 80s 31ms/step - loss: 0.2485 Epoch 00091: loss did not improve from 0.23598 Epoch 92/100 2559/2559 [==============================] - 79s 31ms/step - loss: 0.2492 Epoch 00092: loss did not improve from 0.23598 Epoch 93/100 2559/2559 [==============================] - 80s 31ms/step - loss: 0.2560 Epoch 00093: loss did not improve from 0.23598 Epoch 94/100 2559/2559 [==============================] - 79s 31ms/step - loss: 0.2528
Ve bunun gibi devam ediyor. En son olarak 0.2360 loss’a sahip modelimizin ağırlıklarını birkez daha çağırıp, ilk çıktılarımızı alacağız.
Modelin İlk Testleri
Öncelikle en düşük loss’lu ağırlıkları çağıralım.
filename = "stacked-weights-improvement-90-0.2360.hdf5" model.load_weights(filename) model.compile(loss='categorical_crossentropy', optimizer='adam')
Şimdi çıktılar numerik olacağı için onları notaya çevirmek için yukarıdaki oluşturduğumuz nota:numara dictionarysinin tam tersini oluşturmalıyız numara:nota şeklinde;
int_to_char = dict((i, c) for i, c in enumerate(chars))
Şimdi olay başlıyor. Gerçekleşen olay şu, öncelikle başlangıç değerleri veriliyor bunlara göre predictionlar yapılarak sürekli yeni nota tahminleniyor. Ardından sürekli başlangıç değerleri silinerek devam ediliyor.
Örnek
- D B7 D B7 A G F# sleep A F için bir nota tahmin edildi. Mesela buna **B7** diyelim. Ardından
- B7 D B7 A G F# sleep A F B7 şeklinde verilip yeni tahmin alınıyor.
Şimdi koduna geçelim.
deneme = []
start = numpy.random.randint(0, len(dataX)-1)
pattern = dataX[start]
print("Seed:")
print("\"", ''.join([int_to_char[value] for value in pattern]), "\"")
# generate characters
for i in range(150):
x = numpy.reshape(pattern, (1, len(pattern), 1))
x = x / float(n_vocab)
prediction = model.predict(x, verbose=0)
index = numpy.argmax(prediction)
result = int_to_char[index]
seq_in = [int_to_char[value] for value in pattern]
sys.stdout.write(result+str(" "))
pattern.append(index)
deneme.append(index)
pattern = pattern[1:len(pattern)]
deneme = deneme[len(pattern):]
print("\nDone.")Çıktılarımız da şu şekilde;
Seed: " E7E7EF#GEAGBB " F# E7 sleep E7 A G B B F# E7 E7 A G B B F# E7 new E E A G B7 G E sleep E E A G B7 G E sleep E E A G B7 G E sleep E E A G B7 G E sleep E E A G B7 G E sleep E E A G B7 G E sleep E E A G B7 G E sleep E E A G B7 G E sleep E E A G B7 G E sleep E E A G B7 G E sleep E E A G B7 G E sleep E E A G B7 G E sleep E E A G B7 G E sleep E E A G B7 G E sleep E E A G B7 G E sleep E E A G B7 G E sleep E E A G Done.
Evet şimdi Selenium ile Bu notaları çaldırmaya bakalım.
Bestelenen Şarkının Selenium Yardımıyla Çalınması
Sistem Nasıl Çalışıyor?
Sistemin çalışma mantığı çok basit. Apronus.com adlı sitedeki Canlı Gitar sayfasını kullanıyoruz. Bu sayfada hem mouse ile hem de klavyedeki tuşlar ile notalara basabiliyorsunuz. Bizde öncelikle siteyi açtırıyoruz. Ardından notalar ile klavyedeki tuşları eşliyoruz. Biz notayı verdiğimizde eşlendiği klavye tuşuna basıp notayı çalıyor.
Nota-Keyboard Bağlantısı Nedir?
Apronus.com üzerinde Her nota için klavyede bir tuş var. Örnek vermek gerekirse “G” notası için a tuşuna basmak yeterli. Bizde burada bütün tuşların notalar ile bağlantısına bakarak bunları bir dictionary’e kaydedeceğiz.
Nota:Keyboard Dictionarysinin Oluşturulması
# Notalarımızın Dictionarysi (Apronus'taki klavyedeki tuşlara göre)
notalar = {"Dm#":"d","Bm7":"6","F7":'"',"Ab":"w","G7":"1","C7":"2","D7":"3","E7":"4","A7":"5","B7":"6","C#7":"7","F#7":"8","G#7":"9","A#7":"0","D#7":"-",
"Dm":"tab","Em":"q","Am":"w","Bm":"e","C#m":"r","F#m":"t","G#m":"y","A#m":"u","D#m":"ı","Fm":"o","Gm":"p","Cm":"ğ",
"F":"capslock","G":"a","C":"s","D":"d","E":"f","A":"g","B":"h","C#":"j","F#":"k","G#":"l","A#":"ş","D#":"i"}
Evet şimdi ise selenium fonksiyonlarını oluşturalım
Selenium ile Siteye Bağlanma ve Keyboard ile Notaların Arasında Çalışacak Fonksiyonların Yazılması
Öncelikle Tuşa basma fonksiyonunu yazalım.
# Online Gitar için Klavyede Tuşa Basma Fonksiyonu
def Press(nota):
keyboard = Controller()
# Eğer gitarda Dm notası gelirse, TAB tuşuna basıyor.
if nota == "Dm":
keyboard.press(Key.tab)
# Eğer gitarda F notası gelirse, TAB tuşuna basıyor.
elif nota == "F":
keyboard.press(Key.caps_lock)
# Eğer bu özel notalar dışında bir nota gelirse notalar dictionarysinde eşlenen tuşa basıyor.
else:
keyboard.press(notalar[nota])
# Bu kısımda tuşu basmayla bırakma arasında 0.7 saniye var.
time.sleep(0.7)
keyboard.release(notalar[nota])Şimdi ise Direkt nota listesini verince yukarıdaki Press Fonksiyonunu kullanan ve siteyi açan ana fonksiyonumuzu yazalım.
# Selenium'un Ana Fonksiyonu
def Play(notalist):
#Online Gitar Sitesinin Açılması
driver = webdriver.Chrome('chromedriver.exe')
driver.get("https://www.apronus.com/music/onlineguitar.htm");
#Bu kısımda sitenin yüklenmesi için 10 saniye bekliyor.
driver.implicitly_wait(10)
time.sleep(5)
# Eğer Notamız Sleep ise 0.5 Saniye bekliyoruz.
for i in notalist:
if i == "sleep":
time.sleep(0.5)
# Eğer Notamız New ise şarkı bitiyor.
elif i == "new":
break
else:
Press(i)Evet şimdide öncelikle modelimizi çağıralım. Ardından verisetinden rastgele bir kısım alıp başlangıcı orası yapıp nota ürettirelim. Yeni notaları üretmemizi sağlayacak random kısmı kendi verisetimizden seçebilir veya kendimiz belirleyebiliriz. Ben burada verisetinden seçmek istediğim için verisetini tanımlıyorum.
# Txt Dosyasının Açılması
myfile = open("nirvananota.txt","r")
data = myfile.read().split("\n")
# Boşlukların temizlenmesi bütün notaların tek tek eleman olarak alınması
clean = []
for i in range(0,len(data)):
clean = clean + [x for x in data[i].split(" ") if str(x) != '']
# Karakterler için Dictionary Oluşturulması
chars = sorted(list(set(clean)))
char_to_int = dict((c, i) for i, c in enumerate(chars))
n_chars = len(clean)
n_vocab = len(chars)
# Notaların birbirlerine bağlanması örneğin ;
# E7 G E C --> E7 G E TARGET/C
seq_length = 10
dataX = []
dataY = []
for i in range(0, n_chars - seq_length, 1):
seq_in = clean[i:i + seq_length]
seq_out = clean[i + seq_length]
dataX.append([char_to_int[char] for char in seq_in])
dataY.append(char_to_int[seq_out])
n_patterns = len(dataX)
int_to_char = dict((i, c) for i, c in enumerate(chars))
X = np.reshape(dataX, (n_patterns, seq_length, 1))
# Normalize Etmek.
X = X / float(n_vocab)
# Y değişkeni için One Hot Encoding Yapıyoruz.
y = np_utils.to_categorical(dataY)Bu kısımda daha önceden Eğitilmiş modeli çağırıyorum. Sadece mimarisini tanıtıp, ağırlıkları tanımlıyor ve kullanıma hazır hale getiriyorum.
# Öncelikle Model Mimarisini Tanımlıyoruz.
model = Sequential()
model.add(LSTM(512, return_sequences=True,
input_shape=(X.shape[1], X.shape[2])))
model.add(Dropout(0.5))
model.add(LSTM(512, return_sequences=True))
model.add(Dropout(0.5))
model.add(LSTM(512))
model.add(Dropout(0.5))
model.add(Dense(y.shape[1], activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam')
# Şimdi ise Ağırlıkları veriyoruz.
filename = "stacked-weights-improvement-80-0.2467.hdf5"
model.load_weights(filename)
model.compile(loss='categorical_crossentropy', optimizer='adam')Evet şimdi rastgele bir kısım alıp tahminleme yaptıracağım.
yeninota = []
start = np.random.randint(0, len(dataX)-1)
pattern = dataX[start]
print("Başlangıç Değerleri:")
print(''.join([int_to_char[value] for value in pattern]))
print("Çıktılarımız:")
# generate characters
for i in range(50):
x = np.reshape(pattern, (1, len(pattern), 1))
x = x / float(n_vocab)
prediction = model.predict(x, verbose=0)
index = np.argmax(prediction)
result = int_to_char[index]
seq_in4 = [int_to_char[value] for value in pattern]
sys.stdout.write(result+str(" "))
pattern.append(index)
yeninota.append(index)
pattern = pattern[1:len(pattern)]
yeninota = yeninota[len(pattern):]Çıktılarım ise şu şekilde;
Başlangıç Değerleri: AFB7AFB7AFB7sleep Çıktılarımız: E D B7 D B7 D B7 D B7 A G F# sleep A C F B7 sleep A C F B7 sleep A C F B7 sleep A C F B7 sleep A C F B7 sleep A C F B7 sleep A C F B7 sleep A C
Şimdi bu çıktıları selenium yardımıyla çaldırmak istiyorum. Burada bana numaraların olduğu bir pattern dizisi döndürüyor. Ben bu dizideki numaraları az önce kurduğum numara:nota dictionarysi ile notalara çevireceğim. Ve bu notaların listesini de Selenium içinde yazdığım Play Fonksiyonuna vereceğim ve kod çalışacak.
# Numaralandırılmış olan Notaları Geri Metin Bazlı Nota Haline Getiriyoruz.
yeninotalar =[]
for i in yeninota:
yeninotalar.append(int_to_char[i])
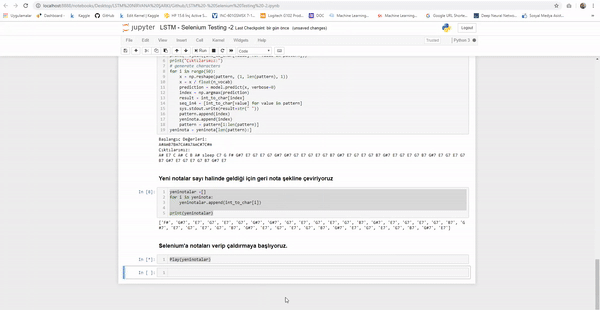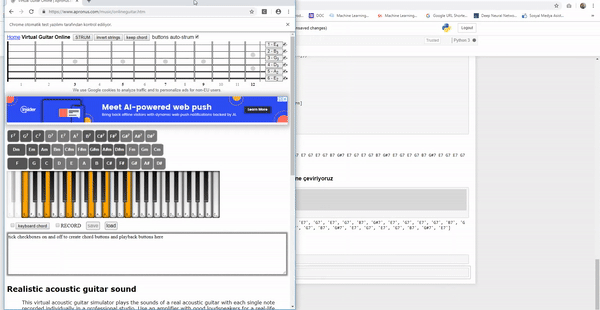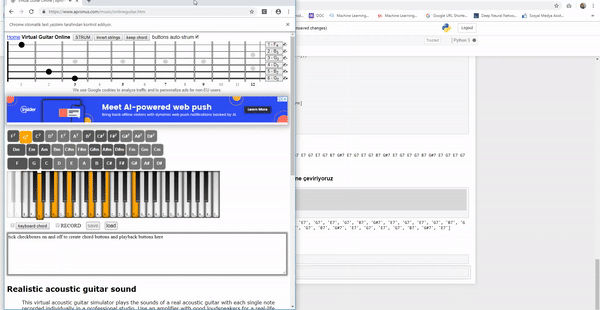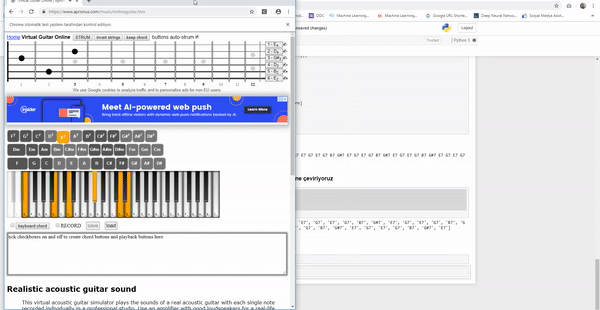
print(yeninotalar)Şimdi ise notaları selenium’a verelim. Ve Çalıştıralım.
Play(yeninotalar)
Ve ortaya çıkacak olay şu şekilde olacak;
Evet şimdi en güzel kısma yani ortaya çıkan sonuçlara gelelim;
Çıkan Sonuçlar
Çıkan sonuçlarımız şu şekilde;
LSTM Guitar v1- Loss ortalama 1-1.5 arasındayken ortaya çıkan parça, biraz kendi kendini tekrarlıyor ama anlamlı gibi 🙂
Şimdi ise Loss’un 0.26 olduğu kısımda ortaya çıkan kısa parçamıza bakalım 🙂 Bu biraz daha anlamlı
Bütün Kodlar
Bütün kodlara BURAYA tıklayarak github hesabımdan erişebilirsiniz. Buraya kadar gelip okuduğunuz için teşekkür ederim. Merak ettiklerinizi yorumlarda yazmayı unutmayın.
Referanslar
[1] https://veribilimcisi.com/2017/09/26/uzun-kisa-sureli-bellek-long-short-term-memory/
[2] https://veribilimiokulu.com/lstm-ile-dolartl-kuru-tahmini/
[3] http://www.akormerkezi.net/nirvana_akorlar-tablar-fnj-1.html
[4] https://apronus.com/music/onlineguitar.htm