

![]()
Daha önceki üç yazıda kümeleme ve K-ortalamalar algoritmasının temel mantığından ve küme sayısını seçme yönteminden bahsettik. Bu yazımızda Python ile K-Ortalamalar tekniğini kullanarak uygulama yapacağız.
Önce kütüphaneleri ve veri setini yükleyelim:
Veri setini buradan indirebilirsiniz.
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import os
os.chdir('Calisma_Dizniniz')
dataset = pd.read_csv('Mall_Customers.csv')Spyder varialble explorer ekranından veri setimizi görelim.

Veriyi Anlamak
Yukarıda görülen veri seti bir markete ait olsun. Market, müşterilerine dağıttığı üyelik kartları ile müşteri bilgileri ile satın alma bilgilerini kaydetmiş olsun. Niteliklerimiz sırasıyla şöyle: Müşteri Numarası (CustomerID), Cinsiyet (Gender), Yaş (Age), Yıllık Gelir (Annual Income) ve Harcama Skoru (Spending Score). Harcama Skoru müşterilerin geçmiş alış-veriş kayıtlarına dayanarak market tarafından 1 ile 100 arasında belirlenmiş bir puandır. Puan 1’e yaklaşması müşterinin daha az harcama yapan bir müşteri olduğunu gösterir. Market elindeki müşterileri segmentlere (kümelere) ayırmak ister. Kim bilir belki de her segmentteki müşteriyi ayrı ele alacak ve ona göre satış arttırma politikaları üretecektir. Kaç segment oluşacağı belli değildir.
Nitelikleri Seçmek
Yukarıda gördüğümüz niteliklerden bağımsız değişken olarak sadece yıllık geliri ve harcama skorunu kullanacağız.
X = dataset.iloc[:,[3,4]].values
Elimizde set var şimdi bunu K-Ortalamalar ile kümelemeye tabi tutacağız ancak algoritma bizden küme sayısı isteyecek. Bir önceki yazımızda bahsettiğimiz gibi küme sayısını bulmak için dirsek yönteminden (elbow method) yardım alacağız. Bunun için önce WCSS’i hesaplayıp küme sayısıyla brilikte WCSS deki değişimin çizgi grafiğini çizmeliyiz. Çizmeden rakamlara bakarak da bir karar verebiliriz ancak yine de çizelim. Öncelikle scikit-learn kütüphanesinden KMeans sınıfını indirelim
from sklearn.cluster import KMeans
Boş bir liste oluşturalım. Bu listeye for döngüsünde her bir küme sayısı içi WCSS değerlerini ekleyeceğiz. Küme sayısı için range() fonksiyonu ile 1’den 10’a kadar birer artan bir liste oluşturalım.
wcss = []
kume_sayisi_listesi = range(1, 11)
for i in kume_sayisi_listesi :
kmeans = KMeans(n_clusters = i, init = 'k-means++', max_iter = 300, n_init = 10, random_state = 0)
kmeans.fit(X)
wcss.append(kmeans.inertia_)For döngüsü içinde yer alan kodlar neler yapıyor biraz konuşalım. Öncelikle import ettiğimiz Kmeans sınıfından kmeans adında bir nesne oluşturuyoruz. Nesne oluştururken yapıcı fonksiyona (__init__) bazı parametreler gönderiyoruz. Bunlardan ilki küme sayısı olan n_clusters. for döngüsü i değişkeniyle her dönüşünde bir artarak küme sayısını parametre olarak n_clusters’a veriyor. init parametresi ise başlangıç noktalarını seçmek için ideal küme merkezlerini belirliyor. Hatırlarsanız rastgele başlangıç noktası tuzağından (random initialization trap) bahsetmiştik. kmeans++ parametresi bizi bu tuzaktan kurtaracak iyi başlangıç noktaları seçmemizi sağlıyor. Bir sonraki parametre max_iter algoritmanın nihai durumuna erişmesi için en fazla kaç iterasyon yapabileceğini belirler, varsayılan 300’tür. n_init ise küme merkezi başlangıç noktasının kaç farklı noktadan başlayabileceğini belirler. Son parametre random_state, bu işlemleri uygulayan herkesin aynı sonuçları elde etmesini sağlar. Nesne oluştuktan sonra fit() metodu ile nesne ile veri uyumunu gerçekleştiririz. Parametre olarak daha önce oluşturduğumuz X’i veriyoruz. for döngüsünden önce oluşturduğumuz wcss listesine kmeans nesnesinin inerita_ özelliğini ekliyoruz.
Dirsek Metodu Grafiği
Küme sayısını belirlemek için dirsek metodu grafiğimizi çizelim.
plt.plot(kume_sayisi_listesi, wcss)
plt.title('Küme Sayısı Belirlemek için Dirsek Yöntemi')
plt.xlabel('Küme Sayısı')
plt.ylabel('WCSS')
plt.show()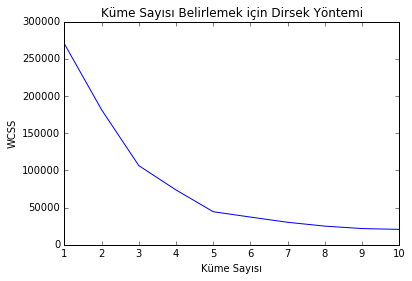
Grafikten ideal küme sayısının 5 olacağını görebiliriz. Şimdi for döngüsündeki küme sayısı 5 için çalışan satırı tekrarlayalım.
Belirlenen küme sayısına göre kümeleme yapmak
kmeans = KMeans(n_clusters = 5, init = 'k-means++', max_iter = 300, n_init = 10, random_state = 0) y_kmeans = kmeans.fit_predict(X)
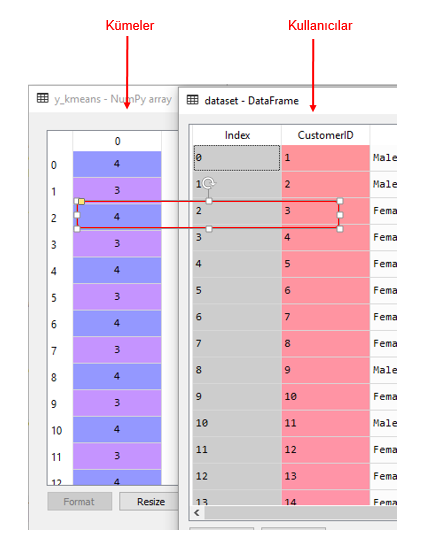
Yukarıdaki kodlarla toplam 200 ayrı kullanıcıyı 5 farklı kümeye yerleştirdik. Aşağıdaki resimde eşleşmenin belli bir kısmını görebiliyoruz.
Kümeleri grafikte göstermek
plt.scatter(X[y_kmeans == 0, 0], X[y_kmeans == 0, 1], s = 100, c = 'red', label = 'Küme 1')
plt.scatter(X[y_kmeans == 1, 0], X[y_kmeans == 1, 1], s = 100, c = 'blue', label = 'Küme 2')
plt.scatter(X[y_kmeans == 2, 0], X[y_kmeans == 2, 1], s = 100, c = 'green', label = 'Küme 3')
plt.scatter(X[y_kmeans == 3, 0], X[y_kmeans == 3, 1], s = 100, c = 'cyan', label = 'Küme 4')
plt.scatter(X[y_kmeans == 4, 0], X[y_kmeans == 4, 1], s = 100, c = 'magenta', label = 'Küme 5')
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], s = 300, c = 'yellow', label = 'Küme Merkezleri')
plt.title('Müşteri Segmentasyonu')
plt.xlabel('Yıllık Gelir')
plt.ylabel('Harcama Skoru (1-100)')
plt.legend()
plt.show()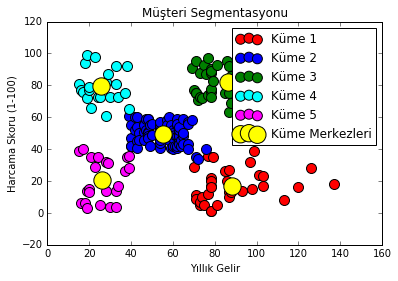
Grafiğimizi oluşturduk. Şimdi daha iyi görebiliyoruz. Kümelerimizi tek tek inceleyelim. Küme 1’de yer alan müşteriler (kırmızı noktalar) Yıllık Geliri yüksek ancak harcama skoru düşük müşteriler. Market sahibi bu müşterilerin daha fazla harcamasını sağlayacak tedbirler düşünebilir. Küme 2’deki müşteriler (mavi noktalar) ortalama gelir ve ortalama harcama skoruna sahipler ve birbirine çok benzeşiyor. Muhtemelen küme içi noktaların merkeze uzaklığının kareler ortalaması (wcss) bu kümede en yüksektir. Küme 3 (yeşil noktalar) yüksek gelirle birlikte yüksek harcama skoruna sahip müşteriler. Her market işletmesinin sahip olmak isteyeceği müşteri segmetidir. Market bu müşterileri elinde tutmak ve bu kümeye müşteri eklemek için gerekli politikaları üretip uygulamaya koyabilir. Küme 4’teki müşteriler (turkuaz mavi) düşük gelire sahip olmasına rağmen yüksek harcama skoruna sahip. Bu müşteriler muhtemelen kredi kartı batağında olan dikkatsiz müşterilerdir 🙂 Küme 5 (pembe) düşük gelire sahip ve harcama skoru düşük müşteriler. Bu müşterilere dikkatli ve tutumlu müşteriler olarak adlandırabiliriz. Kümeleme ile uygulamamız burada son buldu. Bir hatırlatma yapalım: grafikle ilgili kodları sadece iki boyutlu kümelemede kullanabiliriz. Esen kalın…
Kapak: Nareeta Martin on Unsplash
Güzel anlatım olmuş. Teşekkürler.
Çok teşekkür ederim.
Merhabalar ben endüstri mühendisliği öğrencisiyim. Matlab ta k-means kullanarak dizi film seçen bir program yazmamı istediler ama nasil yapacağımı bilmiyorum yardımcı olursanız çok sevinirim
Selam. Matlab kullanmadım. Ancak teoriye hakim olduktan sonra sadece matlab üzerinde uygulamak kalır. Çok zor olacağını sanmıyorum. Kolay gelsin.
merhaba algoritmada kullanmış olduğunuz “s” değeri ne anlama geliyor (s=100 ve s=300 vb). Makale için teşekkürler gayet açıklayıcı bir anlatım olmuş.
Merhaba. s, noktaların büyüklüğünü belirliyor. Dikkat ettiyseniz küme merkezleriiçin s=300 noktalar daha büyük. İyi çalışmalar…
çok teşekkürler size de iyi çalışmalar. Siteniz veri bilimi alanı için gerçekten çok faydalı..
teşekkürler sade ve net bir anlatım olmuş elinize sağlık
Merhabalar. Bulanık c ortalama tekniğinden farkı nedir acaba?
Selam. Tam bilemiyorum. Bilen bir arkadaş yorumda kısaca bizi aydınlatırsa seviniriz.
Merhaba,
Türkiye deki illerin aldığı göç verilerine göre K-means algoritması ile kümeleme yapmak istiyorum.
Fakat veri seti içine il isimlerini yazmadan kümeleme yapıldığında küme sayısı ve bu kümelere kaç adet veri girdiğini gösteriyor
LAKİN illerin adını yazamadığımızdan hangi ilin hangi kümeye ait olduğunu belli edemiyorum.
Acaba bunu nasıl yapabilirim?
Merhaba kümeleme sonunda hangi satırın hangi kümeye dahil olduğunu söyler. Siz il adını girdi olarak kullanmasanız bile her ilin girdiği küme gerçekte o il olmayabilir. Ancak verinin altında yatan gerçeklik illere göre ayrışımı iyi yapacak mahiyette ise illerin çoğunun yine kendisinin olduğu kümede toplanması beklenir. tabiki küme sayısı il sayısı kadar olmak koşuluyla.
Merhaba,
Depo yerleşiminde optimizasyonu sağlamak için satış verilerini kullanarak kümeleme analizi yapmak istiyorum. Ancak bu çalışma kapsamında her ürün ıd’ si için atanan kümeyi görmem gerekiyor. COLAB da yapmış olduğum çalışma da ürün ID’ lerinin sadece bir bölümünün atandığı kümeyi görüntüleyebiliyorum. Tüm liste çıktısını görmem için ne yapmam gerektiği ile ilgili yardımcı olabilir misiniz?
kmeans = KMeans(n_clusters = 5, init = ‘k-means++’, max_iter = 300, n_init = 10, random_state = 0)
y_kmeans = kmeans.fit_predict(X)
Buradaki y_kmeans serisini ana veri setinize yeni bir sütun olarak eklerseniz. Yan yana görebilirsiniz.
Merhaba,
şu aşamada aşağıdaki hatayı aldım bunu nasıl geçerim?
X = dataset.iloc[:,[3,4]].values
IndexError Traceback (most recent call last)
Input In [4], in ()
—-> 1 X = dataset.iloc[:,[3,4]].values
File ~\AppData\Local\Programs\Python\Python310\lib\site-packages\pandas\core\indexing.py:961, in _LocationIndexer.__getitem__(self, key)
959 if self._is_scalar_access(key):
960 return self.obj._get_value(*key, takeable=self._takeable)
–> 961 return self._getitem_tuple(key)
962 else:
963 # we by definition only have the 0th axis
964 axis = self.axis or 0
File ~\AppData\Local\Programs\Python\Python310\lib\site-packages\pandas\core\indexing.py:1458, in _iLocIndexer._getitem_tuple(self, tup)
1456 def _getitem_tuple(self, tup: tuple):
-> 1458 tup = self._validate_tuple_indexer(tup)
1459 with suppress(IndexingError):
1460 return self._getitem_lowerdim(tup)
File ~\AppData\Local\Programs\Python\Python310\lib\site-packages\pandas\core\indexing.py:769, in _LocationIndexer._validate_tuple_indexer(self, key)
767 for i, k in enumerate(key):
768 try:
–> 769 self._validate_key(k, i)
770 except ValueError as err:
771 raise ValueError(
772 “Location based indexing can only have ”
773 f”[{self._valid_types}] types”
774 ) from err
Merhaba
X = dataset.iloc[:,[3,4]].values
komutunu girdiğimde aşağıdaki gibi hata alıyorum hocam bunu nasıl geçerim?
IndexError Traceback (most recent call last)
Input In [13], in ()
—-> 1 X = dataset.iloc[:,[3,4]].values
File ~\AppData\Local\Programs\Python\Python310\lib\site-packages\pandas\core\indexing.py:961, in _LocationIndexer.__getitem__(self, key)
959 if self._is_scalar_access(key):
960 return self.obj._get_value(*key, takeable=self._takeable)
–> 961 return self._getitem_tuple(key)
962 else:
963 # we by definition only have the 0th axis
964 axis = self.axis or 0
File ~\AppData\Local\Programs\Python\Python310\lib\site-packages\pandas\core\indexing.py:1458, in _iLocIndexer._getitem_tuple(self, tup)
1456 def _getitem_tuple(self, tup: tuple):
-> 1458 tup = self._validate_tuple_indexer(tup)
1459 with suppress(IndexingError):
1460 return self._getitem_lowerdim(tup)
File ~\AppData\Local\Programs\Python\Python310\lib\site-packages\pandas\core\indexing.py:769, in _LocationIndexer._validate_tuple_indexer(self, key)
767 for i, k in enumerate(key):
768 try:
–> 769 self._validate_key(k, i)
770 except ValueError as err:
771 raise ValueError(
772 “Location based indexing can only have ”
773 f”[{self._valid_types}] types”
774 ) from err
File ~\AppData\Local\Programs\Python\Python310\lib\site-packages\pandas\core\indexing.py:1376, in _iLocIndexer._validate_key(self, key, axis)
1374 # check that the key does not exceed the maximum size of the index
1375 if len(arr) and (arr.max() >= len_axis or arr.min() 1376 raise IndexError(“positional indexers are out-of-bounds”)
1377 else:
1378 raise ValueError(f”Can only index by location with a [{self._valid_types}]”)
IndexError: positional indexers are out-of-bounds