
![]()
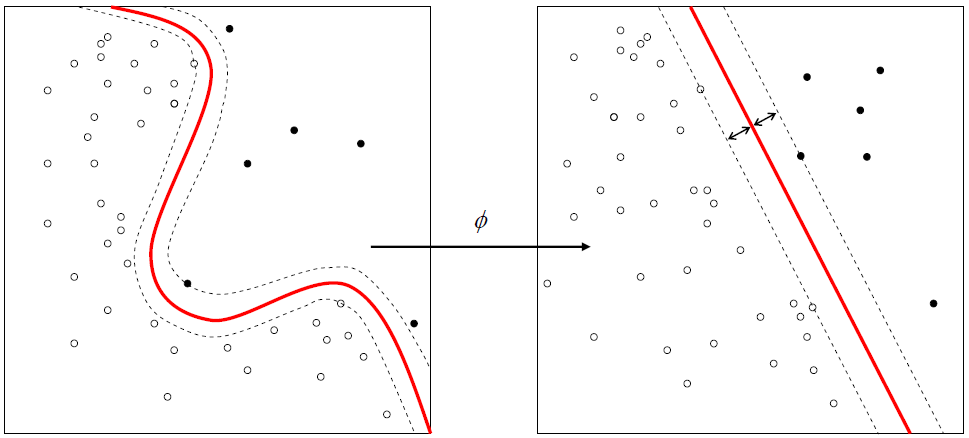
Sınıflandırma notlarına devam ediyoruz. Bazı sınıflandırıcılar doğrusaldır (örn Lojistik regresyon) bazı sınıflandırıcılar ise doğrusal değildir (örneğin KNN). SVM de doğrusal bir doğru ile sınıfları ayırmaya çalışır. Ancak doğrusal ayraçlar doğrusal olmayanlar kadar her zaman başarılı olamaz. Doğrusal olarak birbirinden ayrılamayan sınıflar için kernel trick diye adlandırılan bir yöntem uygulanır. Bu yöntemde kernel fonksiyon uygulanarak normalde doğrusal olarak ayrılamayan sınıflar doğrusal olarak ayrılabilir hale getirilir ve daha başarılı sonuçlar elde edilir.
Kütüphaneleri İndirme, Çalışma Dizinini Ayarlama, Veri Setini İndirme
Veri setini buradan indirebilirsiniz.
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import os
os.chdir('Calisma_Dizniniz')
dataset = pd.read_csv('SosyalMedyaReklamKampanyası.csv')Spyder’ın variable explorer penceresinden veri setimizi görelim:

Veriyi Anlamak
Yukarıda gördüğümüz veri seti beş nitelikten oluşuyor. Veri seti bir sosyal medya kayıtlarından derlenmiş durumda. KullaniciID müşteriyi belirleyen eşsiz rakam, Cinsiyet, Yaş, Tahmini Gelir yıllık tahmin edilen gelir, SatinAldiMi ise belirli bir ürünü satın almış olup olmadığı, hadi lüks araba diyelim. Bu veri setinde kolayca anlaşılabileceği gibi hedef değişkenimiz SatinAldiMi’dir. Diğer dört nitelik ise bağımsız niteliklerdir. Bu bağımsız niteliklerle bağımlı nitelik (satın alma davranışının gerçekleşip gerçekleşmeyeceği) tahmin edilecek.
Veri Setini Bağımlı ve Bağımsız Niteliklere Ayırmak
Yukarıda gördüğümüz niteliklerden bağımsız değişken olarak sadece yaş ve tahmini maaşı kullanacağız.
X = dataset.iloc[:, [2,3]].values y = dataset.iloc[:, 4].values

Veriyi Eğitim ve Test Olarak Ayırmak
Veri setinde 400 kayıt var bunun 300’ünü eğitim, 100’ünü test için ayıralım.
from sklearn.cross_validation import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0)
Normalizasyon – Feature Scaling
Bağımsız değişkenlerden yaş ile tahmini gelir aynı birimde olmadığı için feature scaling uygulayacağız.
from sklearn.preprocessing import StandardScaler sc_X = StandardScaler() X_train = sc_X.fit_transform(X_train) X_test = sc_X.transform(X_test)
SVM Modeli Oluşturmak ve Eğitmek
Şimdi scikit-learn kütüphanesi svm modülü SVC sınıfından oluşturacağımız classifier nesnesi ile modelimiz oluşturalım.
from sklearn.svm import SVC classifier = SVC(kernel='rbf', random_state = 0) classifier.fit(X_train, y_train)
Sınıf parametrelerinden biraz bahsedelim. kernel rbf, her seferinde aynı sonuçları almak için de random_state 0 diyoruz.
Test Seti ile Tahmin Yapmak
Ayırdığımız test setimizi (X_test) kullanarak oluşturduğumuz model ile tahmin yapalım ve elde ettiğimiz set (y_pred) ile hedef değişken (y_test) test setimizi karşılaştıralım.
y_pred = classifier.predict(X_test)
Tahmin ile gerçek sonuçların karşılaştırılmasını tablo olarak görelim:

Solda gerçek, sağda ise tahmin değerleri görüyoruz. 9 indeksli kayıt satın almamış iken satın aldı diye sınıflandırılmış. Yani yanlışa doğru demiş, false positive (FP). Burada görünmeyen kayıtlarda da yanlış sınıflandırma olacaktır.
Hata Matrisini Oluşturma
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
cm
array([[64, 4],
[ 3, 29]])Matriste gördüğümüz gibi 7 adet hatalı sınıflandırma var.
Eğitim Seti İçin Grafik
from matplotlib.colors import ListedColormap
X_set, y_set = X_train, y_train
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1, stop = X_set[:, 0].max() + 1, step = 0.01),
np.arange(start = X_set[:, 1].min() - 1, stop = X_set[:, 1].max() + 1, step = 0.01))
plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap(('red', 'green')))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1],
c = ListedColormap(('red', 'green'))(i), label = j)
plt.title('Kernel SVM (Eğitim Seti)')
plt.xlabel('Yaş')
plt.ylabel('Tahmini Maaş')
plt.legend()
plt.show()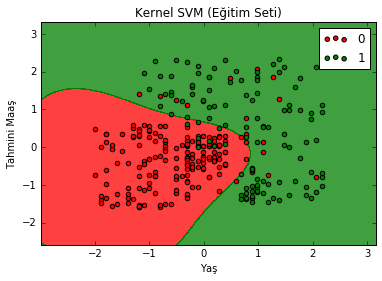
Test Seti İçin Grafik
from matplotlib.colors import ListedColormap
X_set, y_set = X_test, y_test
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1, stop = X_set[:, 0].max() + 1, step = 0.01),
np.arange(start = X_set[:, 1].min() - 1, stop = X_set[:, 1].max() + 1, step = 0.01))
plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap(('red', 'green')))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1],
c = ListedColormap(('red', 'green'))(i), label = j)
plt.title('Kernel SVM (Test Seti)')
plt.xlabel('Yaş')
plt.ylabel('Tahmini Maaş')
plt.legend()
plt.show()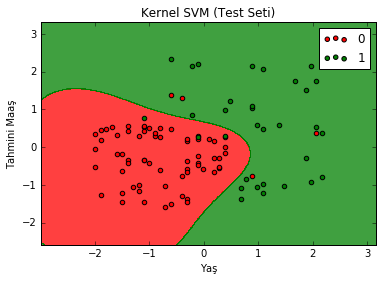
7 tane hatalı sınıflandırma yapmış demiştik. Sayalım: Yeşil bölgede 4 tane kırmızı, kırmızı bölgede 3 tane yeşil var.
SVM ile KernelSVM konularında kodlar 1e1 aynı çıktılar farklı. Bir hata olduğunu düşünüyorum
Merhaba ikazınız için çok teşekkürler. Sonuçlar farklı ancak blog yazısına dönüştürürken kernel SVM için kernel=’linear’ olarak kalmış, kernel=’rbf’ olarak düzeltildi.