

![]()
Merhaba bu ayki yazımda, Kaggle’daki ilaç sınıflandırma (Çoklu Sınıflandırma) yarışması olan Mechanisms of Action (MoA) Prediction üzerine yaptığım 2 farklı model (LGBM ve Deep Learning) çalışmasını paylaşmak ve sizlere aktarmak istedim.
İlk olarak yarışma, hala Kaggle’da devam etmektedir ve önümüzdeki ay yarışmanın süresi dolmaktadır. Bir süredir Kaggle’da tabular yarışma olmamıştı. Bu sebeple bu yarışma konusunun çok zevkli olduğunu söyleyebilirim ve sizlerin de bu veri seti üzerine çalışmanızı öneririm. Yarışmada amacımız, 206 değişkenin tahminlenmesidir. Bu tahminlerimiz 0-1 şeklinde olacaktır. Verimiz yaklaşık 24 bin satır, 876 kolon(nümerik değişkenler). Kolon sayısı gözünüzü korkutmasın 🙂 Bu kolonlar, ilgili gen ve hücre özelliklerini belirtmektedir. Değişkenlerin isimleri g-XX şeklinde olduğu için ve yarışmada değişkenlerin açıklamaları olmadığı için kolonların tek tek açıklamasını yapamıyorum. Kategorik değişkenlerden bazıları; ilacın dozu, kaç saatte bir içileceği gibi özelliklerdir.
Numerik değişkenlerin dağılımını incelediğimizde, neredeyse tüm değişkenlerin normal / yaklaşık normal dağıldığını görüyoruz.
Eğitim verisindeki bağımsız değişkenlerin korelasyon grafiklerini inceleyelim.
Uygulama
train_columns = train.columns.to_list()
g_list = [i for i in train_columns if i.startswith('g-')]
c_list = [i for i in train_columns if i.startswith('c-')
columns = g_list + c_list
for_correlation = list(set([columns[np.random.randint(0, len(columns)-1)] for i in range(200)]))[:40]
data = df[for_correlation]
f = plt.figure(figsize=(18, 18))
plt.matshow(data.corr(), fignum=f.number)
plt.xticks(range(data.shape[1]), data.columns, fontsize=14, rotation=50)
plt.yticks(range(data.shape[1]), data.columns, fontsize=14)
cb = plt.colorbar()
cb.ax.tick_params(labelsize=13)Yüksek korelasyonlu değişkenlerimizi filtreleyelim ve bunlar nelermiş, bakalım.
Grafik:1 – Korelasyon Grafiği
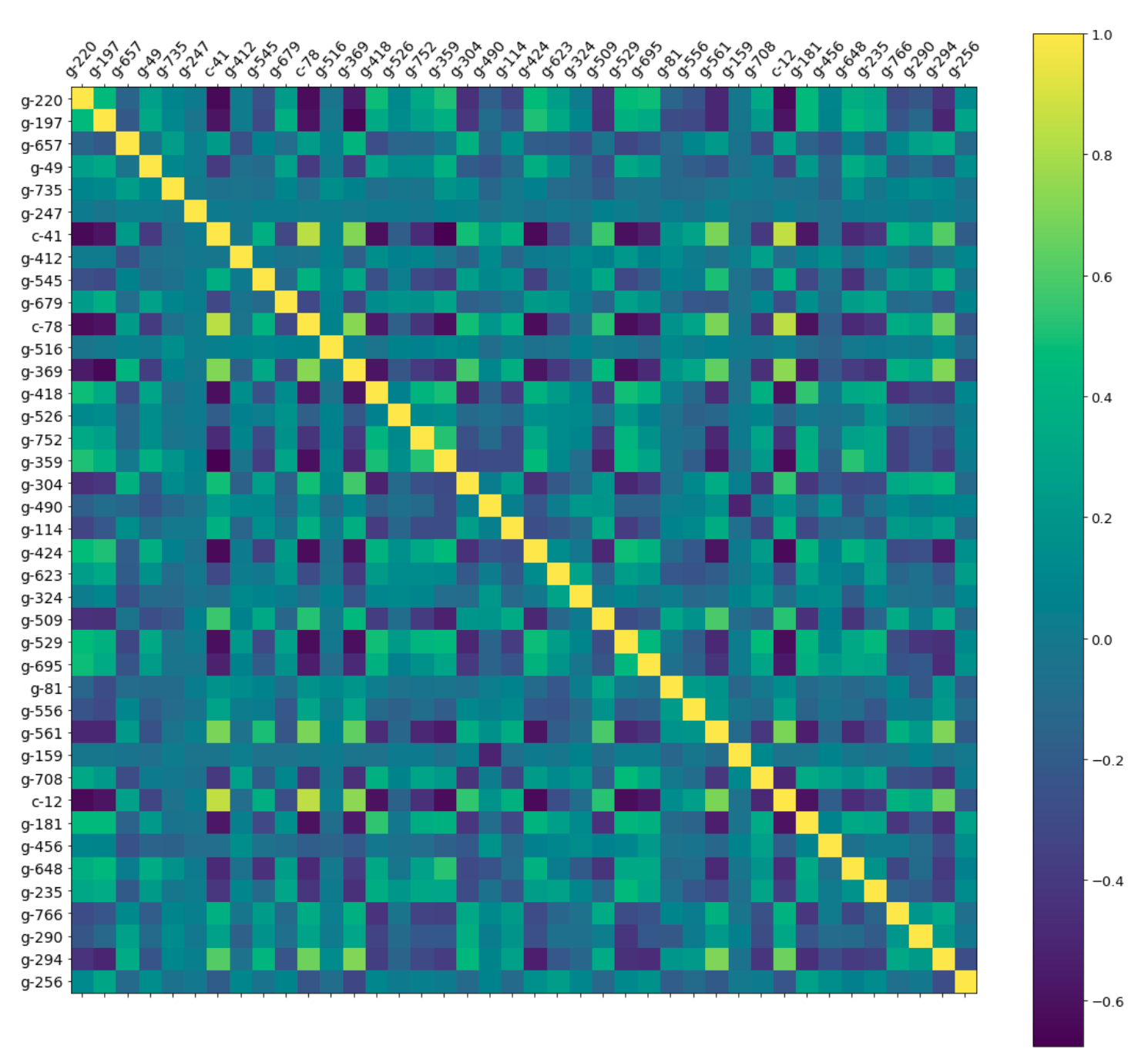
cols = ['cp_time'] + columns
all_columns = []
for i in range(0, len(cols)):
for j in range(i+1, len(cols)):
if abs(train[cols[i]].corr(train[cols[j]])) > 0.9:
all_columns = all_columns + [cols[i], cols[j]]
all_columns = list(set(all_columns))
data = df[all_columns]
f = plt.figure(figsize=(18, 18))
plt.matshow(data.corr(), fignum=f.number)
plt.xticks(range(data.shape[1]), data.columns, fontsize=14, rotation=50)
plt.yticks(range(data.shape[1]), data.columns, fontsize=14)
cb = plt.colorbar()
cb.ax.tick_params(labelsize=14)Grafik:2 – Yüksek Korelasyonlu Değişlenler

Bu yarışmada ilk başta Boosting yöntemlerinden olan LGBM modeli kurulmuştur. Bildiğiniz üzere, Boosting yöntemlerinde parametre mühendisliği yapmak gerekir. Modele girmeden önce çeşitli değişkenler üretilerek, modelin hedef değişkenlerini daha iyi anlayabilmesi / tahminleyebilmesi istenir.
Bu nedenle çeşitli ve anlamlı değişkenler üretilerek model, parametrelerce ve üretilen yeni kolonlarla beslenir. Derin öğrenmede ise durum pek böyle değildir. Parametre mühendisliği işlemleri, derin öğrenme modellerinde Boosting yöntemlerinde olduğu kadar kritik değildir çünkü derin öğrenme modellerinde yapının ve ilişkilerin model tarafından öğrenilmesi ve modelin kendi featurelarını üretmesi beklenilir.
Bu yarışma özelinde, ilaç sektörü ve analizleri hakkında daha önceden bir bilgim olmadığı için domain bilgim yoktu. Bu sebeple parametre üretme işlemleri epey zorlu geçti. Parametreler ile epey uğraştıktan sonra basit düzeyde değişkenler üretmeye karar verdim ve LGBM modelini geliştirdim.
LGBM model kodlarımı ve çalışmalarımı bu notebook üzerinden görebilirsiniz. LGBM modelini kurduğum notebook’u buradan inceleyebilirsiniz.
Burada akla şöyle bir düşünce gelebilir; “Madem ki parametre mühendisliği süreçleri zorlu ve domain bilgisi gerektiriyor. Öyleyse direkt Derin Öğrenme modelleri geliştireyim”. Fakat makine öğrenmesi dünyasında işler pek böyle ilerlemiyor. “No Free Lunch Teorem”e göre hiçbir modelin, diğer modellere bir üstünlüğü yoktur. En başarılı model, veri setine göre değişmektedir.
Eğer dikkat ettiyseniz, bilimsel makalelerde farklı algoritmalar ile kıyaslama yapılırken, sonuç cümlelerinde “bizim veri setimize göre en başarılı model xx” şeklinde tamamlanır. Buradan da anlaşılacağı üzere, makine öğrenmesi modellerinde basitten, karmaşığa giden bir model sıralaması yapabilmekteyiz. Derin öğrenme, parametre mühendisliği işlemlerini kendisi yapabildiği için daha kolay gözükebilir fakat derin öğrenme modelleri, daha fazla veriye ihtiyaç duyduğunu hatırlatmak isterim.
Bu yarışmada öncelikle bir LGBM modeli kurdum ve yüksek korelasyonlu değişkenleri eledim. Ardından aşağıda belirttiğim hiperparametreleri kullanarak, modelimi geliştirdim.
Boosting Yöntemi (LGBM) Hiperparametreleri
params = {'num_leaves': 490,
'min_child_weight': 0.03,
'feature_fraction': 0.55,
'bagging_fraction': 0.9,
'min_data_in_leaf': 150,
'objective': 'binary',
'max_depth': -1,
'learning_rate': 0.01,
"boosting_type": "gbdt",
"bagging_seed": 11,
"metric": 'binary_logloss',
"verbosity": 0,
'reg_alpha': 0.4,
'reg_lambda': 0.6,
'random_state': 47
}
Amacımız 206 değişkeni tahmin etmek üzerine olduğu için for döngüsü içerisinde 206 farklı hedef değişkeni tahminledim ve overfitten kaçınmak için CV (cross validation) uyguladım. Modelin eğitim süresi yaklaşık 2 saat sürdü ve LGBM modeli, Kaggle Public Dataset üzerinden beni %15’lik dilime soktu. LGBM gibi boosting yöntemlerinde, ciddi bir feature engineering işlemleri olmaktadır.
Temelinde Karar Ağaçları kullanan bu algoritmalarda, modele olabilecek ve ilişki kurabilecek tüm değişkenleri modele göstermek gerekmektedir. Bu sebeple biraz daha fazla domain bilgisi gerekmektedir. Bu yarışmada benim domain bilgimin az olması ve bine yakın değişkenin bulunması sebebiyle derin öğrenme modelleri üzerine odaklandım.
Ardından derin öğrenme modelleri üzerinde çalışmalarıma devam ettim. Bu model mimarisinde 5 katmanlı bir yapı kurguladım.
Derin Öğrenme Modelini ve bu yazının bulunduğu çalışmayı, bu link üzerinden görebilirsiniz.
Deep Learning Model Uygulaması
Derin Öğrenme Modeli çalışmamda kullandığım kütüphaneler,
from tensorflow.keras.callbacks import ReduceLROnPlateau, EarlyStopping from sklearn.model_selection import KFold, StratifiedKFold from sklearn.preprocessing import LabelEncoder from sklearn.metrics import log_loss import tensorflow.keras.backend as K import tensorflow.keras.layers as L import tensorflow.keras.models as M import tensorflow_addons as tfa from tqdm.notebook import tqdm import tensorflow as tf import pandas as pd import numpy as np import random import time
Verilerimizi yükleyelim ve id kolonunu silelim. Model kurarken id değişkenine ihtiyacımız olmayacak. Bu değerleri, model tahminlerimizi submit ederken kullanacağız.
test_features = pd.read_csv('/kaggle/input/lish-moa/test_features.csv')
train_targets = pd.read_csv('/kaggle/input/lish-moa/train_targets_scored.csv')
train_features = pd.read_csv("/kaggle/input/lish-moa/train_features.csv")
submission = pd.read_csv('/kaggle/input/lish-moa/sample_submission.csv')
del test_features['sig_id'], train_features["sig_id"], train_targets['sig_id']Veri setini incelerken farkettiğim kategorik değişkenleri, label encoder ile kategorik dönüşümü yaptım.
for feature in ['cp_type', 'cp_dose']:
trans = LabelEncoder()
trans.fit(list(train_features[feature].astype(str).values) + list(test_features[feature].astype(str).values))
train_features[feature] = trans.transform(list(train_features[feature].astype(str).values))
test_features[feature] = trans.transform(list(test_features[feature].astype(str).values))
train = train_features.copy()Ardından keras ile sıralı bir model mimarisi kurguladım. Aşağıda sizlerle paylaştığım mimari öncesinde, deneme-yanılma ile çeşitli mimarilerle çalışmalar yapmıştım. Yazıda paylaştığım en iyi skora sahip hiperparametrelerdir.
Derin katmanlarda öğrenmenin gerçekleştirilebilmesi için öncelikle parametre sayısı kadar input alacağını modele belirtip, batch normalizasyonu yaptım. Batch Normalizasyonu (Toplu normalleştirme), yapay sinir ağlarını yeniden ortalayarak ve ölçeklendirerek, giriş katmanını normalleştirerek daha hızlı ve kararlı hale getirmek için kullanılan bir yöntemdir.
Ağırlık normalizasyonu ve iletim sönümleme (dropout) katmanlarıyla, model iyileştirme çalışmaları yaptım. Ağırlık normalizasyonu literatürde şöyle açıklanmaktadır, ağırlıkları bu şekilde yeniden parametrelendirerek, optimizasyon probleminin koşullandırmasını iyileştiririz ve stokastik gradyan inişinin yakınsamasını hızlandırırız. Yeniden parametrelendirmemiz toplu normalizasyondan esinlenmiştir, ancak bir mini partideki örnekler arasında herhangi bir bağımlılık oluşturmaz. Ek olarak, yöntemimizin hesaplama yükü daha düşüktür ve aynı sürede daha fazla optimizasyon adımının atılmasına izin verir. Çalışmada aşırı öğrenmeyi engelleme adına çeşitli iletim sönümleme (dropout) oranlarıyla beraber, farklı aktivasyon fonksiyonları – mimarileri – hiperparametreleri denenmiştir.
2. katmanda sigmoid aktivasyonu kullanırken diğerlerinde relu aktivasyon fonksiyonunu kullandım, bunun sebebi ise deneme yanılma yaparken en başarılı CV sonucunu bu mimari ile almış olmamdır.
Model Mimarisi
def create_model(num_columns):
model = tf.keras.Sequential([
tf.keras.layers.Input(num_columns),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Dropout(0.2),
tfa.layers.WeightNormalization(tf.keras.layers.Dense(1400, activation="relu")),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Dropout(0.4),
tfa.layers.WeightNormalization(tf.keras.layers.Dense(840, activation="sigmoid")),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Dropout(0.3),
tfa.layers.WeightNormalization(tf.keras.layers.Dense(588, activation="relu")),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Dropout(0.2),
tfa.layers.WeightNormalization(tf.keras.layers.Dense(470, activation="relu")),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Dropout(0.1),
tfa.layers.WeightNormalization(tf.keras.layers.Dense(206, activation="sigmoid"))
])
model.compile(optimizer=tfa.optimizers.Lookahead(tf.optimizers.Adam(), sync_period=5),
loss='binary_crossentropy', metrics=["accuracy"]
)
return model
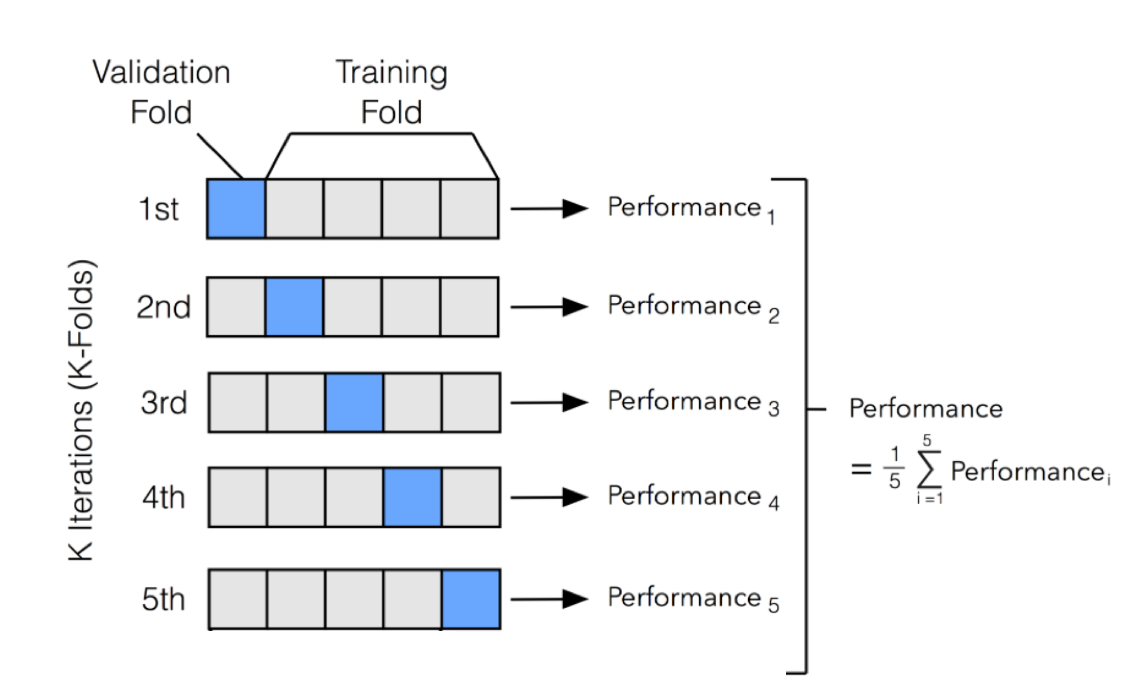
Model mimarisini oluşturduktan sonra model tahminlerini alacağımız ve CV yapacağımız döngüyü kurabiliriz. Burada, KFold yöntemini kullanmayı tercih ettim ve verimi 3 fold’a böldüm.
CV Yöntemi
Grafik-3: K-Folds Nasıl Çalışır
Kaynak: http://ethen8181.github.io/machine-learning/model_selection/model_selection.html
Model ve Tahminler
N_STARTS = 3
tf.random.set_seed(43)
res = train_targets.copy()
submission.loc[:, train_targets.columns] = 0
res.loc[:, train_targets.columns] = 0
for seed in range(N_STARTS):
for n, (tr, te) in enumerate(KFold(n_splits=3, random_state=seed, shuffle=True).split(train_targets)):
print(f'Fold {n}')
model = create_model(len(train.columns))
reduce_lr_loss = ReduceLROnPlateau(monitor='val_loss', factor=0.15, patience=3, verbose=1, epsilon=1e-4, mode='min')
early_stop = EarlyStopping(monitor='val_loss', min_delta=0, patience=5, mode= 'min')
model.fit(train.values[tr],
train_targets.values[tr],
validation_data=(train.values[te], train_targets.values[te]),
epochs=45, batch_size=128,
callbacks=[reduce_lr_loss, early_stop], verbose=2
)
test_predict = model.predict(test_features.values)
val_predict = model.predict(train.values[te])
submission.loc[:, train_targets.columns] += test_predict
res.loc[te, train_targets.columns] += val_predict
print('')
submission.loc[:, train_targets.columns] /= ((n+1) * N_STARTS)
res.loc[:, train_targets.columns] /= N_STARTSYukarıda kodları gördüğünüz gibi modeli kurarken, veri setimi üç parçaya böldüm ve model, bu iki bölümü görerek, üçüncü kısmı tahminlemeye çalıştı. Her seferinde validasyon setini değişerek, model en başarılı ağırlık oranlarını öğrenmiş oldu.
Fakat bu çalışmada ek olarak, validasyon kısmı üç farklı kez seçilmiştir (kodda gördüğünüz ilk for döngüsü). Yani CV işlemi üç farklı kez yapılmıştır. Başka bir ifade ile validasyon ve eğitim seti üçer kez yeniden kurulmuştur. Daha sonra final tahmini olarak, tüm tahminlerin ortalaması alınmıştır.
Modelin diğer hiperparametresi olarak 45 tekrarlı ve 128 batch size’lı train edilmiştir. Öğrenme oranının güncellenmesi ve overfitten kaçınmak için derin öğrenme modeline reduce_lr_loss ve early_stop kontrolleri eklenmiştir. Modelde toplamda 6.563.409 parametre bulunmaktadır. Kişisel gelişim alanı ve akademik araştırma alanı olarak, öğrenme oranının güncellenme konusu popülerliğini korumaktadır.
Log Loss Hata Metriği
metrics = []
for _target in train_targets.columns:
metrics.append(log_loss(train_targets.loc[:, _target], res.loc[:, _target]))
print(f'OOF Metric: {np.mean(metrics)}')
# OOF Metric: 0.015101278077080529
Tahminlerimizi aldıktan sonra CV skorumuzun 0.151 olduğu görülmektedir. Yarışmada puanlama sistemi logloss metriği üzerinden hesaplandığından, bu çalışmada da logloss metriği kullanılmıştır. Uygulamada da görüldüğü üzere, bu veri seti için derin öğrenme modelli, LGBM modelinden daha başarılı sonuç üretmiştir ve eğitim daha kısa sürede tamamlanmıştır.
Veri bilimi çalışmalarında Kaggle’ın faydalı bir platform olduğunu düşünüyorum. Özellikle yeni merak salan arkadaşlar için bu işlerin kronolojik sırasının nasıl olduğu ve ne tür işlerin yapıldığını görebildikleri, yararlı bir ortamdır. Ayrıca yarışmalara katılan insanlar, kodlarını ve yöntemlerini paylaştıkları için eğitici bir yanı da vardır. Kaggle’da benim yazdığım diğer notebook’ları da bu link üzerinden erişebilir ve sorularınızı sorabilirsiniz.
Saygılarımla,
Varsayımlarınızın sağlanması dileğiyle,
Veri ile kalın, Hoşça kalın…
UTKU KUBİLAY ÇINAR
Görsel Kaynak : file:///Users/utku.cinar/Desktop/gorsel%202.html