
![]()
Merhaba VBO severler, bu yazımda sizlere metin madenciliği ve chatbotlarda sıkça kullanılan benzerlik yöntemlerinden bahsedeceğim. Lafı çok fazla uzatmadan gelin neymiş bu Jaccard Benzerliği ve Kosinüs Benzerliği hep beraber inceleyelim.
Biliyorsunuzki metin madenciliği ve chatbotlarda kullanılan veriler genellikle çok büyük sayıda olurlar ve bunları tek tek incelemek günlerimizi hatta haftalarımızı alır. Ancak benzerlik ölçütleri sayesinde bu verilerin birbirleri arasında ne kadar benzerliğe sahip olduğunu kolayca bulabilmekteyiz. Ben bu yazımda size en çok kullandığım iki yöntemden bahsedeceğim. Birincisi Jaccard Benzerliği, ikincisi ise Kosinüs Benzerliği.
Jaccard Benzerliği Nedir?
Basit bir şekilde anlatmak gerekirse elimizde bulunan iki kümenin kesişiminin elaman sayısının, birleşiminin elaman sayısına bölümü şeklinde ifade edilebilir. Aşağıdaki görselde de matematiksel formülünü görebilirsiniz. Ben bu formülü basit bir python fonksiyonu haline getirip öyle kullanmaktayım.

def jaccard (first, second):
fcount = 0
scount = 0
for f in first:
if f in second:
scount += 1
fcount = len(first)+len(second)
score = float(scount) / float(fcount)
return scoreBurada verilen ilk metin ile ikinci metin arasındaki benzer olan harf ve boşlukları sayıp iki metnin uzunluklarının toplamına bölümüyle benzerliği elde edebiliyoruz. Eğer metinler arasındaki benzerlik “0.5” ise iki metin birbirinin aynısıdır.

Kosinüs Benzerliği Nedir?
Jaccard benzerliğinin aksine kosinüs benzerliği metinler arasındaki benzerliği vektörel olarak ölçmektedir. Metinlerde geçen kelimelerin metinde kaç kez geçtiğini hesaplanır. Daha sonra her metin içerdiği kelimelerle 1 ve 0 şeklinde vektörel olarak ifade edilir. Her metin üç boyutlu uzayda vektörel olarak yerleştirildiğinde aralarındaki kosinüs açısı ne kadar küçük ise metinler birbirlerine o kadar yakındır. Aşağıdaki fonksiyon ile kosinüs benzerliğinin nasıl çalıştığına birlikte bakalım.
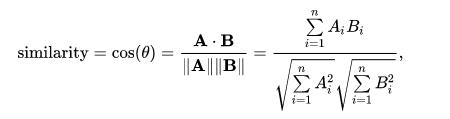
from sklearn.metrics.pairwise import cosine_similarity
from sklearn.feature_extraction.text import CountVectorizer
import pandas as pd
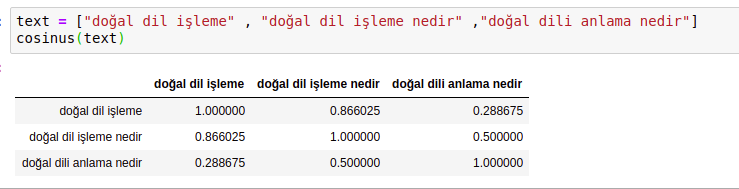
def cosinus(value):
count_vectorizer = CountVectorizer()
sparse_matrix = count_vectorizer.fit_transform(value)
doc_term_matrix = sparse_matrix.todense()
df = pd.DataFrame(doc_term_matrix,
columns=count_vectorizer.get_feature_names(),
index= [value])
#print(df.head())
cos = cosine_similarity(df, df)
cosDf = pd.DataFrame(cos , columns = [value] , index= [value])
#print(cosDf.head())
return cosDfBurada CountVectorizer sınıfının fit_transform fonksiyonu ile metinlerde geçen kelimelerin frekansları hesaplanır. Daha sonra her bir metnin içerdiği kelimeler 1 ve 0 olarak atanır.

Daha sonra cosine_smilarity fonksiyonu ile metinler arasındaki kosinüs açısı ölçülerek metinler arasındaki benzerlikler hesaplanır.
Bu yazımda sizlere metin benzerlikleri hakkında bilgi vermeye çalıştım. Bir sonraki yazımda sizlere IBM Watson ile baştan sona nasıl chatbot yapılır onu anlatmaya çalışacağım. Diğer bir yazıda görüşmek dileğiyle , veriyle kalın.
Kaynakça
https://tr.qwe.wiki/wiki/Cosine_similarity
https://en.wikipedia.org/wiki/Jaccard_index
https://medium.com/@sddkal/python-k%C3%BCmeler-i%C3%A7in-jaccard-benzerli%C4%9Fi-5e894df42fdb
http://bilgisayarkavramlari.sadievrenseker.com/2012/11/08/kosinus-benzerligi-cosine-similarity-2/