

![]()
Python ortamında veri bilimi ile uğraşanların en çok kullanığı kütüphaneler Pandas ve Numpy’dır. Bu yazıda ise bu kütüphanelerde olan, işlerinizi oldukça kolaylaştıracak fonksiyonlardan bahsedeceğim.
Numpy
1 – argpartition()
Bu fonksiyon, bize N en büyük değerlerin indekslerini vermektedir. İhtiyaca göre bu indekslere sahip değerleri sıralayabiliriz.
x = np.array([1,9,5,8,7,13,4]) index_val = np.argpartition(x, -4)[-4:] index_val #--> array([4, 1, 5, 3]) np.sort(x[index_val]) #--> array([ 7, 8, 9, 13])
2 – allclose()
Bu fonksiyon, 2 tane dizinin birbirine eşit ya da benzer olup olmadığını, belirlenen tolerans değeri ile kontrol etmektedir.
array1 = np.array([0.25,0.36,0.45,0.68,0.95]) array2 = np.array([0.26,0.35,0.44,0.70,0.93]) np.allclose(array1, array2, 0.1) #--> True
3 – clip()
Bu fonksiyon, bir dizideki değerleri belirlenen aralık içinde tutar. Aralığın dışındaki değerler, aralığın alt ve üst limitlerine kırpılır.
x = np.array([3,16,15,9,1,4,2,26,12,8]) np.clip(x,3,10) #--> array([ 3, 10, 10, 9, 3, 4, 3, 10, 10, 8])
4 – extract()
Bu fonksiyon, bir diziden belli koşullara uyan değerlere ulaşılmasını sağlar.
# Rastgele sayı üret array = np.random.randint(40, size=20) array #--> array([31,14,24,34,5,2,26,12,36,10,1,22,30,29,13,0,12,31,31,34]) # Sayıların 3'e bölümünden kalanı 1 olanları kontrol et cond = np.mod(array, 3)==1 # Yukarıdaki koşula sahip olan değerleri çıkar np.extract(cond, array) #--> array([31, 34, 10, 1, 22, 13, 31, 31, 34])
5 – where()
Bu fonksiyon, bir diziden belli koşullara uyan değerlerin indeks değerlerini kullanıcıya döndürür.
y = np.array([5,9,7,12,25,16,10,19]) # Eğer koşul değeri True ise "Büyük", False ise "Küçük" yazdır np.where(y>13, "Büyük", "Küçük") #--> array(['Küçük','Küçük','Küçük','Küçük','Büyük','Büyük', 'Küçük','Büyük'], dtype='<U5')
Pandas
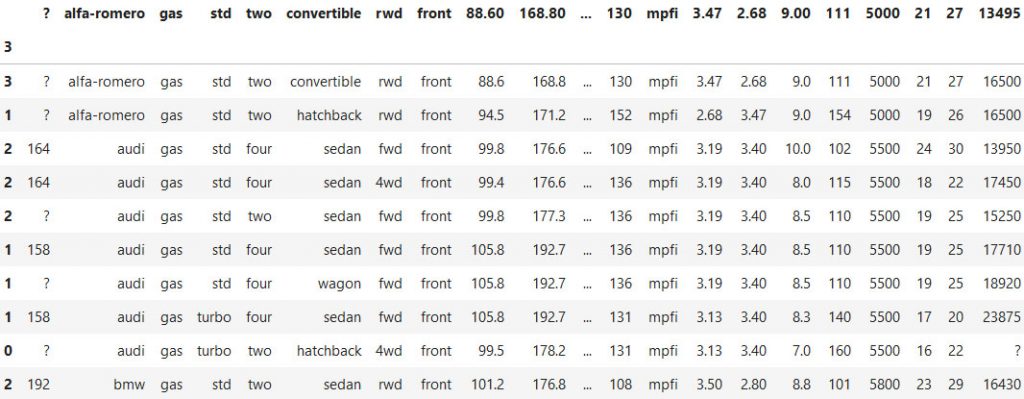
1 – read_csv(nrows=n)
Herkes read_csv() ile veri yüklüyor. Ancak gerekli olmadığı zamanlarda verinin hepsini yüklemek çok zahmetli olmaktadır. 10 GB boyutunda bir veriyi gerekli olmadığı halde yüklemeye çalışmak yerine sadece ilk 10 satırı yükleyip, daha sonra ihtiyaca göre devam edebiliriz.
import io
import requests
url = "http://archive.ics.uci.edu/ml/machine-learning-databases/autos/imports-85.data"
s = requests.get(url).content
df = pd.read_csv(io.StringIO(s.decode("utf-8")),
nrows=10,
index_col=0)
df
2 – map()
Bu fonksiyon, başka bir fonksiyon yardımı ile bir serideki değerleri değiştirmeye yarar.
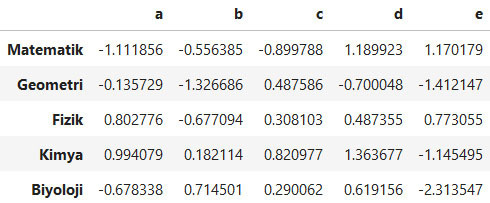
# Dataframe oluştur
df = pd.DataFrame(np.random.randn(5, 5),
columns=list("abcde"),
index=['Matematik', 'Geometri',
'Fizik', 'Kimya',
'Biyoloji'])
# Sayıların virgülden sonraki 2 basamağını alan fonksiyon changefn = lambda x: '%.2f' % x # Değişiklikleri "d" sütununa uygula df['d'].map(changefn)

3 – apply()
Bu fonksiyon, kullanıcıya istediği bir fonksiyonu her bir değere uygulamasına izin verir.
# max - min fn = lambda x: x.max() - x.min() # Yukarıda oluşturduğumuz veriye, fonksiyonu satır bazında uygulayalım df.apply(fn)

4 – isin()
Bu fonksiyon, belirli bir sütunda belirli bir değere sahip satırların seçilmesine yardımcı olur.
df['d'].isin([1])

5 – copy()
Bu fonksiyon, bir pandas objesinin kopyasını oluşturmaya yarar. Bir dataframe objesini başka bir objeye atadığımız zaman, orjinal objede yapılan değişiklikler diğer objeye de yansımaktadır. Bu problemi çözmek için copy() fonksiyonu kullanılır.
# Seriyi oluştur data = pd.Series(['Finlandiya', 'Norveç', 'İsveç', 'Danimarka']) # Seriyi kopyala new = data.copy() # Yeni değer ata new[1] = 'Changed Value' print(new)

print(data)

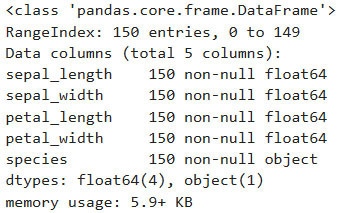
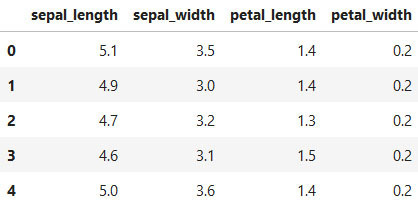
6 – select_dtypes()
Bu fonksiyon, dataframe içindeki istenilen veri tipindeki sütunları kullanıcıya döndürmektedir.
iris = pd.read_csv('data/iris.csv')
iris.info()
iris.select_dtypes(include="float64").head()
Evet, bir yazımızın daha sonuna geldik. Umarım, bu fonksiyon işinizde size oldukça yardımcı olur. Yukarıdaki fonksiyonlar hakkında daha detaylı bilgi almak isteyenler için aşağıya ilgili linkleri koyacağım.
Sağlıkla Kalın.
Kaynakça:
https://towardsdatascience.com/12-amazing-pandas-numpy-functions-22e5671a45b8
https://numpy.org/doc/stable/reference/generated/numpy.clip.html?highlight=clip#numpy.clip
https://numpy.org/doc/stable/reference/generated/numpy.extract.html?highlight=extract#numpy.extract
https://numpy.org/doc/stable/reference/generated/numpy.where.html?highlight=where#numpy.where
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_csv.html