

![]()
Missing Value Imputation, Handling of the Missing Data in R
Utku Kubilay ÇINAR

Ne güzeldir hazır verilerle çalışmak. Eksik gözlem derdin yok, ilişkisel veri tabanlarından verilerini birleştirme çaban yok, gürültülü veri desen ona ne hacet. En sevdiğimiz veri, hazır – işlem gerektirmeyen ve direk analizlerimize başlayacağımız veri setleri olsa da hayatın acımasız gerçekleri var. Böyle verileri gerçek hayatta görmek çok güç.
Veri bilimi ile ilgili çalışan kişiler tidydata yani veriyi hazır hale getirme işlemleriyle uzun zaman geçirirler. Aykırı gözlemler, eksik gözlemler, tabloları birleştirme, yüksek korelasyonlu parametreler ve saymadığım niceleri..
Veri manipülasyonu işlemlerinde istatistik teorilerini bilmenin avantajları yatsınamaz bir gerçektir. Eksik veriyi, yansız tamamlamak ciddi bir bilgi birikimi gerektirir ama cankurtaran görevi gören istatistik bilimi sayesinde işimiz kolaylaşmaktadır. İstatistik teorileriyle geliştirilen birçok algoritma sayesinde bu büyük sorun büyük ölçüde araştırmacının işini kolaylaştırmaktadır. Eksik veriyi doldurmak için tabi birden fazla algoritmalar ve yöntemler mevcuttur ama veriyi doldururken (imputasyon) yapılırken yansız(unbias) doldurmak önemlidir. Verinin karakterini bozmadan, bize söylediği bilgileri ve doğruları kaçırmadan eksik veriyi doldurmak önemlidir.
Eksik verinin tanımını doğru yapmak gerekir. Eksik veriler belli bir düzene göre mi eksik yoksa rastlantısal olarak mı eksik kalmış ? Bu sorunun cevabı önemlidir. Tamamıyla Rastlantısal Olarak Kayıp Veriler (TROK) olarak adlandırılan eksik veriler, başka bir parametrenin etkisiyle doğrudan ya da dolaylı olarak eksilmeyen, veri setinde tamamen rastlantısal (rastgele) olarak dağılmış eksik verilerdir. İstatistikte bunun rastlantısal olarak dağılmasını isteriz. Bunun için “missing value analysis” yapılır ve bu testi yaparken t – Testi (başka testler de mevcuttur) kullanılır. Hipotezimiz ise kayıp veriler rastlantısal dağılıp dağılmadığıdır ve araştırmacı, kayıp verilerin rastlantısal olarak dağılmasını amaçlar ve test eder.
Veri setimizin herhangi bir parametresinde ciddi oranda eksik gözlem varsa( yarı yarıya eksik, hatta verinin %70 – 80’ i eksikse) analizlerde kullanırken çok dikkat edilmelidir hatta belki o parametre kullanılmamalıdır, silinmelidir. Eksik verinin bulunduğu parametrede üstüne bir de gürültülü veri varsa vay araştırmacının haline! Ölmüş ağlayanı yok. Bir de üstüne bağımlı değişken üzerinde açıklayıcılığı yüksek bir parametreyse.. Acın, acımdır sayın araştırmacı…
Eksik veriden kaynaklanacak hata toleransını azaltmak için çok sayıda method vardır. En basit yöntem olarak eksik – kayıp veriyi yok sayarak diğer adıma geçmektir. Fakat eksik verinin çok olduğu yöntemlerde hata yüzdesi çok fazla olacağı için bu durum araştırmacının yükünü arttıracaktır. Bu yöntemlerin bazıları Hot / Cold Deck, EM (beklenti maksimizasyonu), regresyon, karar ağacı, Naive Bayes, K – en yakın komşuluk, ortalama değer ve en son gözlem gibi yöntemler kullanılabilir. Fakat bu yazıda istatistiksel yöntemlerle geliştirilen birkaç algoritma üzerine durulacaktır, bu algoritmalar R programlama dilinde yaygın olarak kullanılır. Bu sebeple yazımda, R programlama literatüründe yaygın olarak kullanılan algoritmalar incelenmiştir.
Bazı parametreler bağımsız değişkenler için çok önem arz etmektedir ve bu parametrelerde eksik gözlemler bulunuyorsa eksik verileri yansız, etkili ve etkin bir şekilde değer ataması yapılmalıdır. Literatürde de bu durum tavsiye edilmektedir.
Eksik gözlemden kaçmak pek güçtür. Anket çalışması yapıldığında kişi cevap vermek istemeyebilir, verilerin aktarımında hata olmuş olabilir, birincil anahtarların eşleşmemesinden az da olsa kaynaklanabilir, ölçüm cihazından kaynaklı eksikler olabilir. Ölçülebilen ya da gözlemlenebilen her çalışmada bulunabilir eksik gözlem ve veri kaybına sebep olabilir. Bu eksik gözlemleri doldururken kullanılabilecek bazı algoritmalar mevcuttur. Bunlardan bazıları;
Regresyon Analizi ile eksik veri
Regresyon analizinde bağımlı değişkeni, bağımsız değişkenlerle tahmin etmek hedeflenir. Eksik verileri regresyon analizi ile doldurmak istenildiğinde tıpkı bağımsız değişkenlerle tahmin etmeye çalışıldığı gibi eksik verileri tahmin etmeye çalışır.
Regresyon analizi ile eksik veriler doldurulduğunda bazı varsayımlar vardır. Birincisi eksik verilerin tamamen rassal olarak dağıldığıdır. İkincisi ise kayıp veriyi regresyon modeline sokulduğunda diğer bağımsız değişkenlerde eksik veri olmamasıdır.
Hot – Deck ile eksik veri
Hot – Deck eksik veriyi doldurma işlemini yaparken K- en yakın komşuluğu ile eksik gözlemleri doldurur. Benzerlik uzaklığı/yapısı ile hesaplanır ve imputasyon gerçekleştirilir. Benzerliği tam olarak belirlenemediğinden(tanımlanması yapılamasının güç olduğundan) standart bir yapısı yoktur. Eksik veri için ona en benzer olduğuna inanılan gözlem değeri atanır.
Hot deck atfının avantajları arasında kavramsal basitliği, değişkenlerin ölçüm düzeylerini koruması (kategorik değişkenler kategorik olarak, sürekli değişkenler sürekli olarak kalır) ve tamamlanmış veri matrisi elde edilmesi sayılabilir. Tamamlanmış veri matrisi sayesinde de standart istatistiksel analizler uygulanabilir. (Şahin. Ş., 2012)
Naive Bayes ile eksik veri
Bayes karar teorisini temel olarak hesaplar, eksik veriyi ve doldurma işlemine dayanır. Bayes sınıflandırmasıyla eksik gözlemler tamamlanır. Sınıflar için ayrı ayrı olasılıklar hesaplanır ve eksik gözlemin bulunduğu örneğin en yüksek olasılığa sahip sınıftan olması söz konusudur. Naive Bayes, her kriterin sonuca olan etkilerinin olasılık olarak hesaplanmasına dayanır.
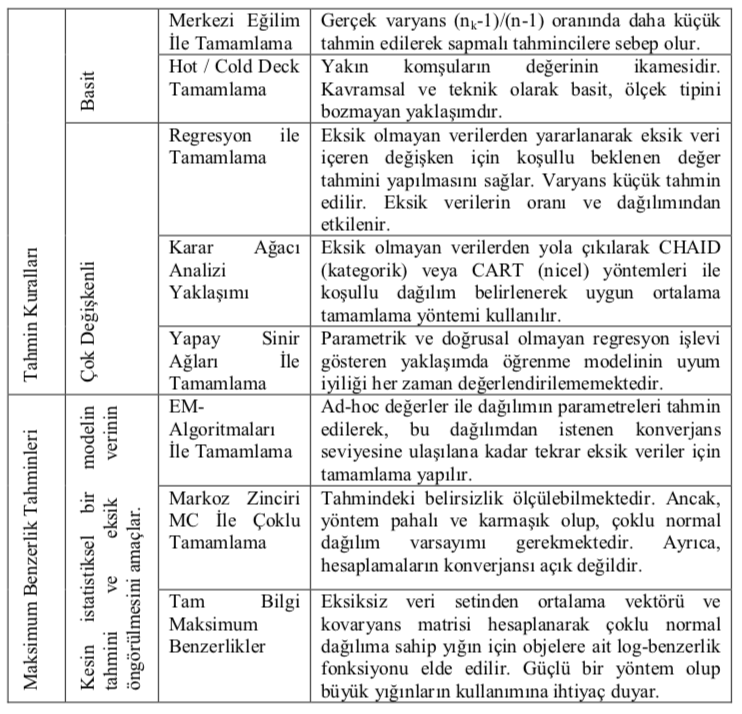

Tablo Kaynak: Dokuz Eylül Üniversitesi İktisadi ve İdari Bilimler Fakültesi Dergisi, Cilt:25, Sayı:2, Yıl:2010, ss.73-83
Uygulama – Eksik Veriler ile Mücadele
R programı, veri işleme konusunda araştırmacıya ciddi kolaylık ve esneklik sunmaktadır. R programı içinde barındırdığı kütüphaneler ile eksik veriyi analiz etme, onları işleme, doldurma (imputasyon) ve görselleştirme gibi hemen hemen her konuda elimizi kolaylaştırır.
Eksik veri ile mücadelemizde R programında çok değerli kütüphaneler bulunmaktadır. Bunların başlıcaları; mice, Amelia, missForest, Hmisc ve mi kütüphaneleridir.
Görüldüğü gibi kayıp veri büyük bir problem olsa bile istatistiksel yöntemlerle geliştirilen algoritmalar mevcut olduğundan artık işimiz sanıldığı kadar zor değil.
Faydalı kütüphaneler
# Uygulamada kullanacağımız ve diğer faydalı pekemonlar
library(mice)
library(Amelia)
library(missForest)
library(Hmisc)
library(mi)
library(VIM)
library(DataExplorer)
library(ggplot2)
library(caret)VIM kütüphanesi içinden “sleep”, uyku veri setini inceleyelim ve buradaki eksik gözlemleri doldurmaya çalışalım.
Hangi parametrelerden toplam kaç tane eksik gözlemimiz var ?
introduce(sleep)## rows columns discrete_columns continuous_columns all_missing_columns
## 1 62 10 0 10 0
## total_missing_values total_observations memory_usage
## 1 38 620 6128Görüldüğü üzere 62 gözlemimiz ve 10 parametremiz var. Eksik gözlemler incelendiğinde ise toplam 38 adet verinin eksik/kayıp olduğunu görüyoruz.
Eksik değerlerimizi içeren gözlemler ise,
sleep[!complete.cases(sleep),]## BodyWgt BrainWgt NonD Dream Sleep Span Gest Pred Exp Danger
## 1 6654.000 5712.0 NA NA 3.3 38.6 645 3 5 3
## 3 3.385 44.5 NA NA 12.5 14.0 60 1 1 1
## 4 0.920 5.7 NA NA 16.5 NA 25 5 2 3
## 13 0.550 2.4 7.6 2.7 10.3 NA NA 2 1 2
## 14 187.100 419.0 NA NA 3.1 40.0 365 5 5 5
## 19 1.410 17.5 4.8 1.3 6.1 34.0 NA 1 2 1
## 20 60.000 81.0 12.0 6.1 18.1 7.0 NA 1 1 1
## 21 529.000 680.0 NA 0.3 NA 28.0 400 5 5 5
## 24 207.000 406.0 NA NA 12.0 39.3 252 1 4 1
## 26 36.330 119.5 NA NA 13.0 16.2 63 1 1 1
## 30 100.000 157.0 NA NA 10.8 22.4 100 1 1 1
## 31 35.000 56.0 NA NA NA 16.3 33 3 5 4
## 35 0.122 3.0 8.2 2.4 10.6 NA 30 2 1 1
## 36 1.350 8.1 8.4 2.8 11.2 NA 45 3 1 3
## 41 250.000 490.0 NA 1.0 NA 23.6 440 5 5 5
## 47 4.288 39.2 NA NA 12.5 13.7 63 2 2 2
## 53 14.830 98.2 NA NA 2.6 17.0 150 5 5 5
## 55 1.400 12.5 NA NA 11.0 12.7 90 2 2 2
## 56 0.060 1.0 8.1 2.2 10.3 3.5 NA 3 1 2
## 62 4.050 17.0 NA NA NA 13.0 38 3 1 1Eksik verileri görselleştirelim
aggr(sleep, prop = F, numbers = T)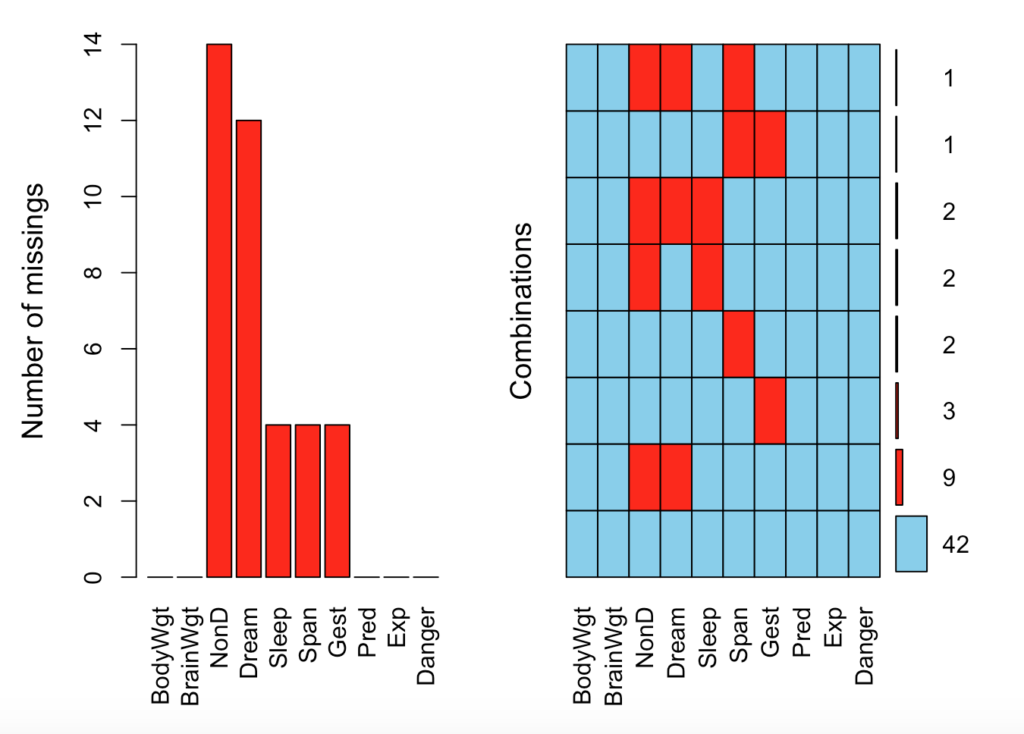
missmap(sleep, col=c('grey', 'steelblue'), y.cex=0.5, x.cex=0.8)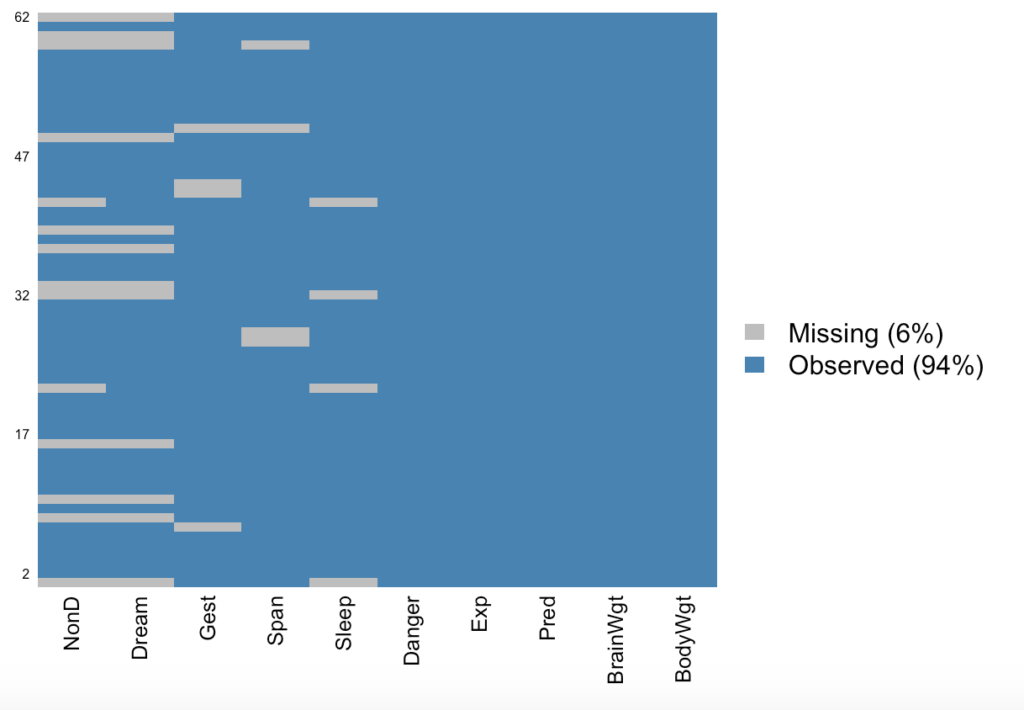
mice kütüphanesi ile eksik verilerin kalıplarını görebiliriz.
md.pattern(sleep)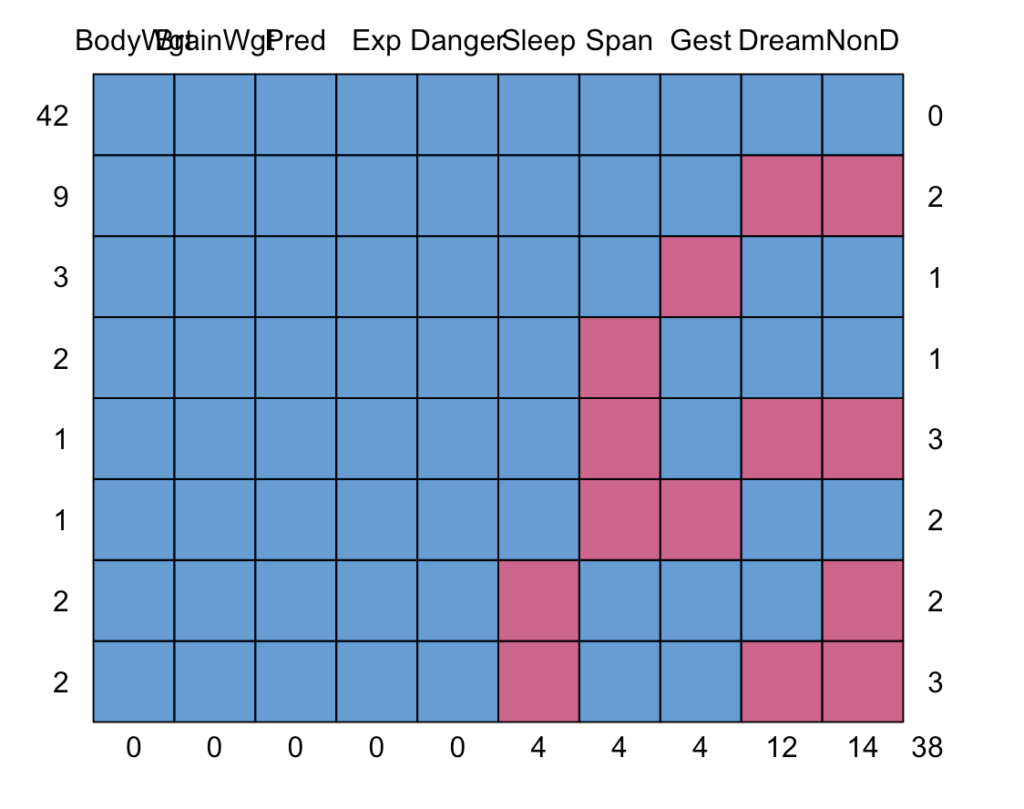
## BodyWgt BrainWgt Pred Exp Danger Sleep Span Gest Dream NonD
## 42 1 1 1 1 1 1 1 1 1 1 0
## 9 1 1 1 1 1 1 1 1 0 0 2
## 3 1 1 1 1 1 1 1 0 1 1 1
## 2 1 1 1 1 1 1 0 1 1 1 1
## 1 1 1 1 1 1 1 0 1 0 0 3
## 1 1 1 1 1 1 1 0 0 1 1 2
## 2 1 1 1 1 1 0 1 1 1 0 2
## 2 1 1 1 1 1 0 1 1 0 0 3
## 0 0 0 0 0 4 4 4 12 14 38Buradaki birler ve sıfırlar, verinin varlığını ya da yokluğunu göstermektedir. Burada 42 gözlem tam iken Gest parametresinde 3 gözlem eksik.
plot_missing(sleep)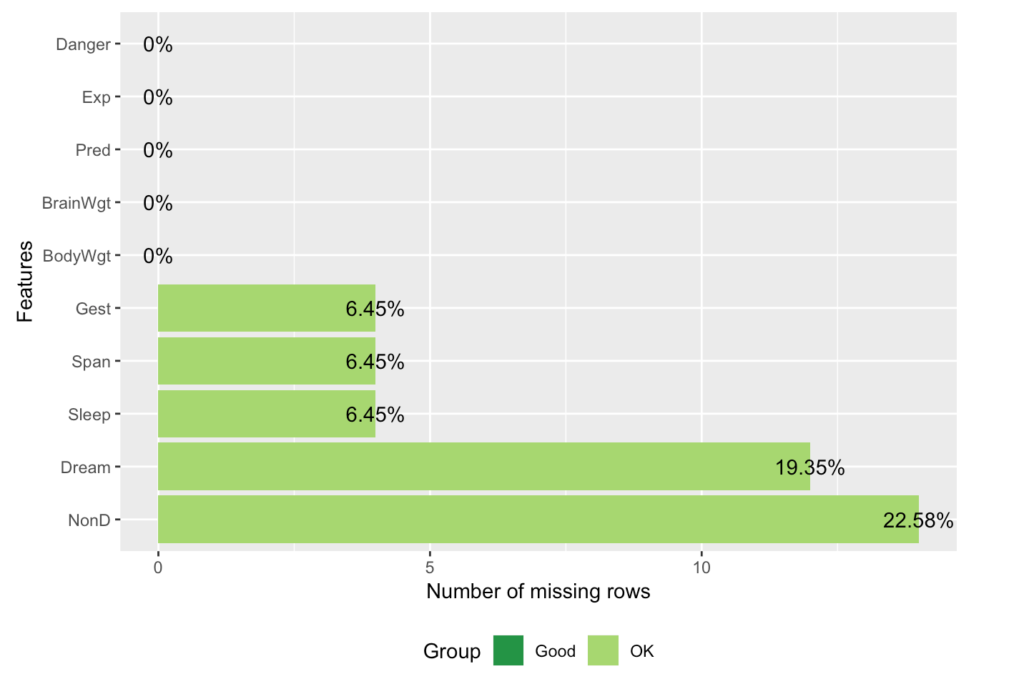
matrixplot(sleep, interactive = T, sortby = "Sleep")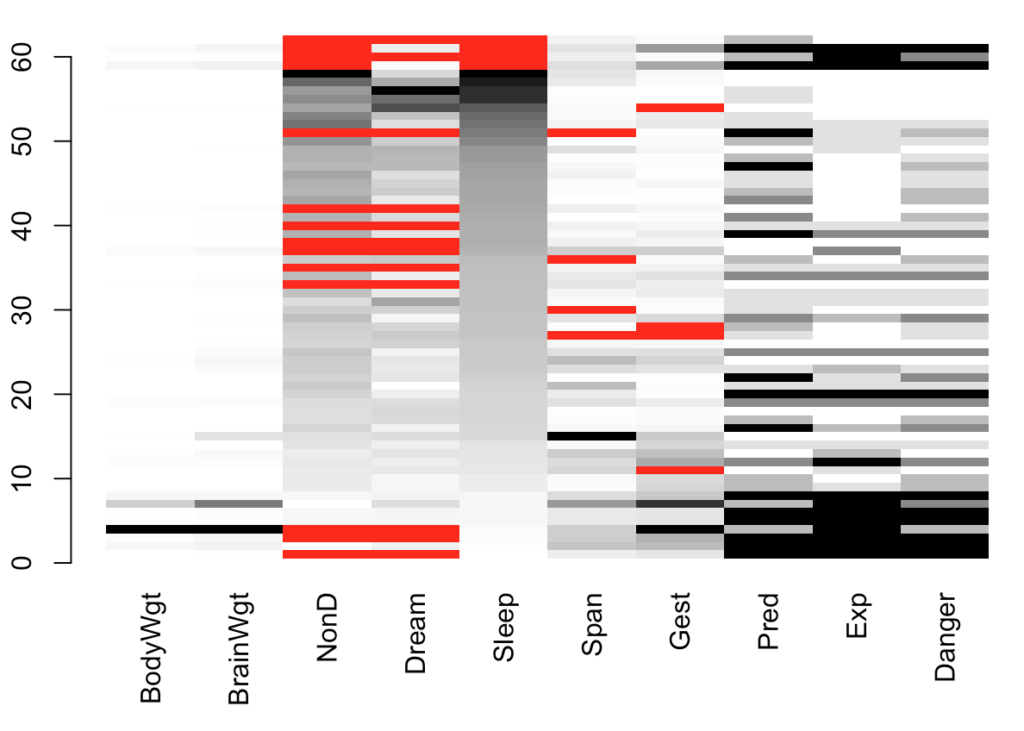
aggr(sleep, col=mdc(1:2), numbers=TRUE, sortVars=TRUE, labels=names(sleep), cex.axis=.7, gap=3, ylab=c("Eksiklik Oranı","Eksiklik Dilimleri"))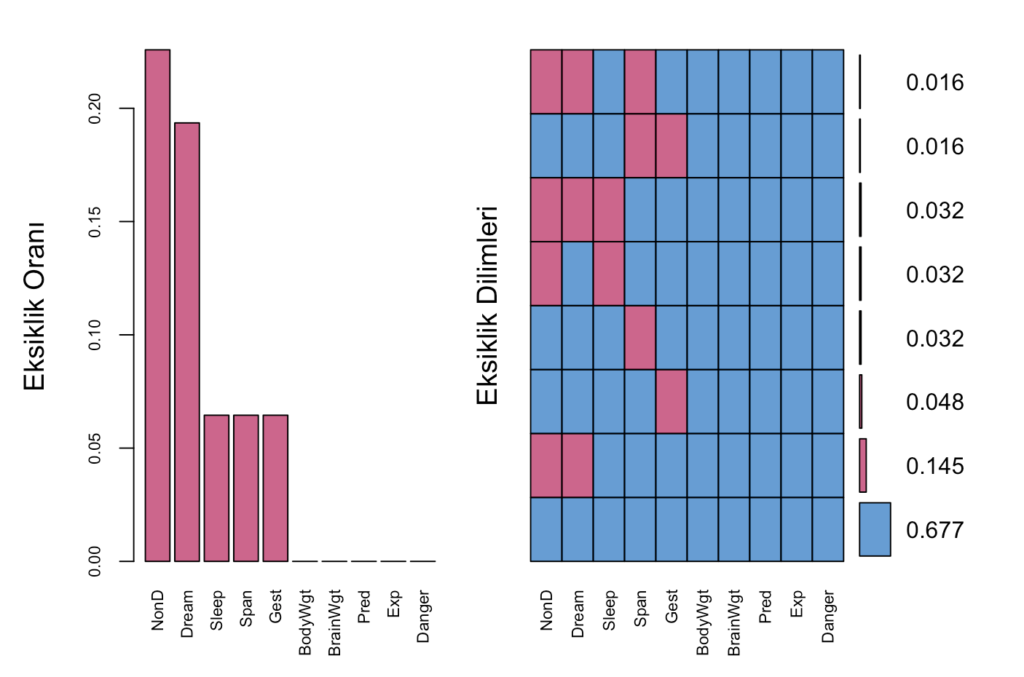
##
## Variables sorted by number of missings:
## Variable Count
## NonD 0.22580645
## Dream 0.19354839
## Sleep 0.06451613
## Span 0.06451613
## Gest 0.06451613
## BodyWgt 0.00000000
## BrainWgt 0.00000000
## Pred 0.00000000
## Exp 0.00000000
## Danger 0.00000000Eksiklik oranı ile o parametrenin yüzde kaçının kayıp veri içerdiğini görebiliyoruz.
Kayıp verilerimizi üretelim.
tamamlanmis <- mice(sleep, m=5, maxit = 50, seed = 50, printFlag=F)
methods(mice) komutu ile eksik veriyi doldurma yöntemlerini görebilir ve verinize uygun olanı seçebilirsiniz.
summary(tamamlanmis)## Class: mids
## Number of multiple imputations: 5
## Imputation methods:
## BodyWgt BrainWgt NonD Dream Sleep Span Gest Pred
## "" "" "pmm" "pmm" "pmm" "pmm" "pmm" ""
## Exp Danger
## "" ""
## PredictorMatrix:
## BodyWgt BrainWgt NonD Dream Sleep Span Gest Pred Exp Danger
## BodyWgt 0 1 1 1 1 1 1 1 1 1
## BrainWgt 1 0 1 1 1 1 1 1 1 1
## NonD 1 1 0 1 1 1 1 1 1 1
## Dream 1 1 1 0 1 1 1 1 1 1
## Sleep 1 1 1 1 0 1 1 1 1 1
## Span 1 1 1 1 1 0 1 1 1 1
## Number of logged events: 140
## it im dep meth out
## 1 1 2 Span pmm Sleep
## 2 1 2 Gest pmm Sleep
## 3 3 4 Span pmm Sleep
## 4 5 2 Span pmm Sleep
## 5 5 2 Gest pmm Sleep
## 6 6 3 Span pmm Sleepdensityplot(tamamlanmis)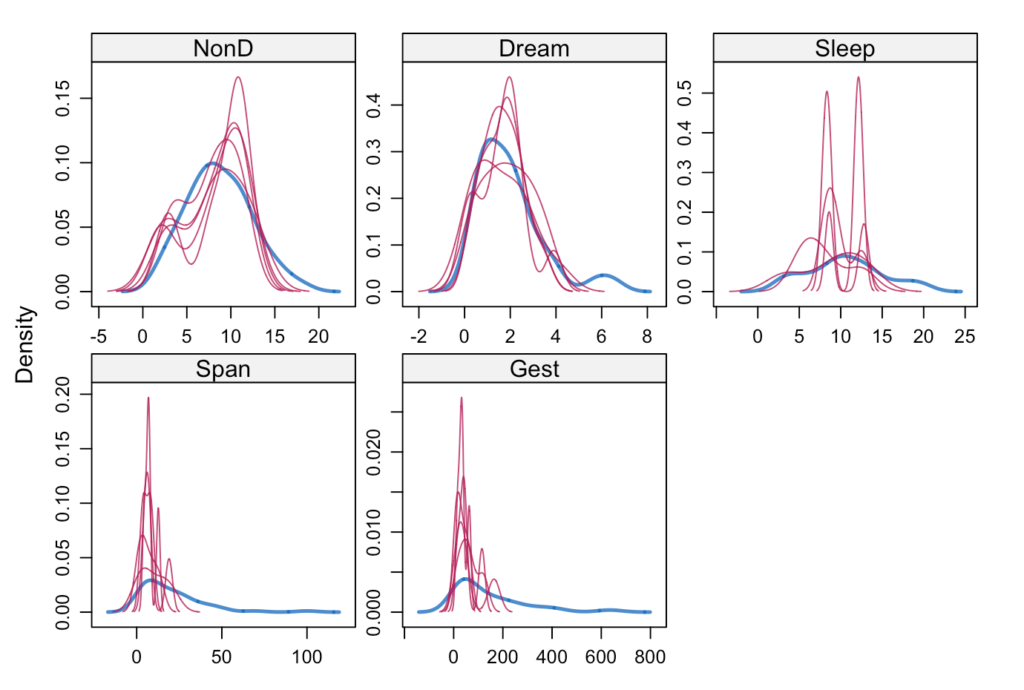
Bu grafik bizim için faydalı bir grafiktir. Magenta rengiyle gördüğümüz değerler bizim ürettiğimiz değerlerdir, mavi renkle gördüğümüz kalın çizgi ise gözlenen değerlerdir. Yansız eksik verileri doldurabilmek için bizim ürettiğimiz değerlerin ana yapıyı ne kadar çok yansıtırsa, ne kadar çok benzerse o kadar iyi eksik verileri doldurmuşuz diyebiliriz. Diğer faydalı grafiğimiz aşağıdaki gibidir. ,
stripplot(tamamlanmis, pch = 20, cex = 1.2)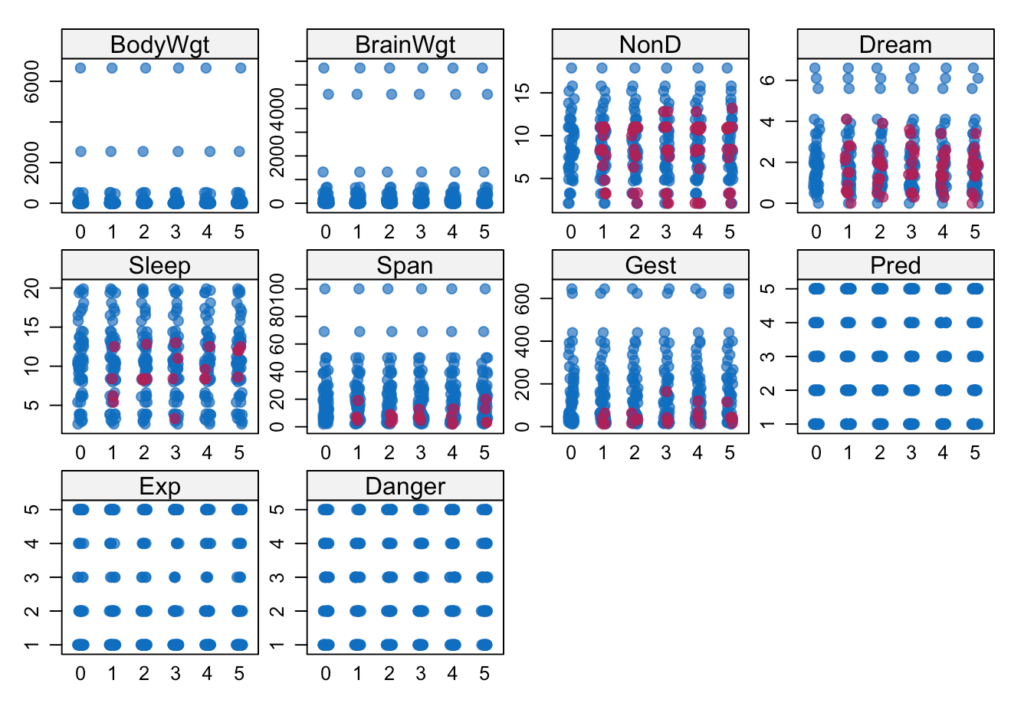
plot(tamamlanmis)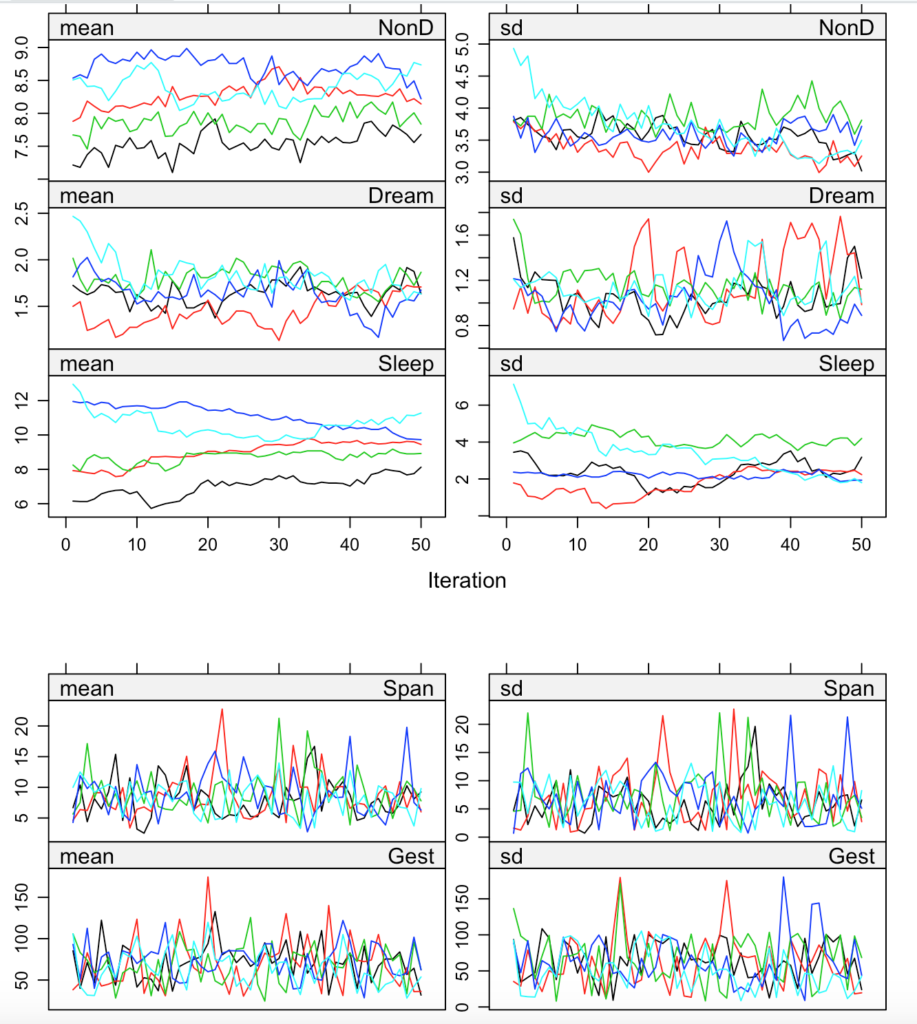
Fonksiyonu oluştururken 5 iterasyonlu yapmasını istemiştik, görselimiz.
Eksik gözlemleri doldurma işlemi yapıldığında NonD değişkenimize eklenen gözlemler,
tamamlanmis$imp$NonD## 1 2 3 4 5
## 1 3.3 3.2 3.2 2.1 2.1
## 3 11.0 10.6 11.0 11.0 11.0
## 4 10.0 11.0 12.8 12.8 13.2
## 14 3.2 2.1 3.2 2.1 3.3
## 21 6.5 7.7 12.8 8.1 8.4
## 24 11.0 11.0 8.3 10.6 10.8
## 26 11.0 10.9 11.0 10.8 10.9
## 30 8.3 8.4 8.2 8.3 8.4
## 31 4.8 6.3 2.1 6.1 10.8
## 41 7.7 7.6 7.5 8.4 11.0
## 47 10.8 10.9 11.0 10.8 10.9
## 53 3.2 3.3 2.1 2.1 3.2
## 55 8.3 10.0 8.3 10.9 7.4
## 62 8.4 11.0 8.2 11.0 10.9
Hadi birleştirelim,
doldurulmus <- complete(tamamlanmis, 2)
head(doldurulmus)
## BodyWgt BrainWgt NonD Dream Sleep Span Gest Pred Exp Danger
## 1 6654.0 5712.0 3.2 0.5 3.3 38.6 645 3 5 3
## 2 1.0 6.6 6.3 2.0 8.3 4.5 42 3 1 3
## 3 3.3 44.5 10.6 1.9 12.5 14.0 60 1 1 1
## 4 0.9 5.7 11.0 3.9 16.5 9.0 25 5 2 3
## 5 2547.0 4603.0 2.1 1.8 3.9 69.0 624 3 5 4
## 6 10.5 179.5 9.1 0.7 9.8 27.0 180 4 4 4
Böylelikle verilerimizi tamamlamış olduk.
tamamlanmis$pred## BodyWgt BrainWgt NonD Dream Sleep Span Gest Pred Exp Danger
## BodyWgt 0 1 1 1 1 1 1 1 1 1
## BrainWgt 1 0 1 1 1 1 1 1 1 1
## NonD 1 1 0 1 1 1 1 1 1 1
## Dream 1 1 1 0 1 1 1 1 1 1
## Sleep 1 1 1 1 0 1 1 1 1 1
## Span 1 1 1 1 1 0 1 1 1 1
## Gest 1 1 1 1 1 1 0 1 1 1
## Pred 1 1 1 1 1 1 1 0 1 1
## Exp 1 1 1 1 1 1 1 1 0 1
## Danger 1 1 1 1 1 1 1 1 1 0KNN ile doldurma
knn_doldurma <- kNN(sleep, variable = c("NonD", "Dream", "Span"), k = 5)
head(knn_doldurma[,1:10])## BodyWgt BrainWgt NonD Dream Sleep Span Gest Pred Exp Danger
## 1 6654.000 5712.0 3.2 0.8 3.3 38.6 645 3 5 3
## 2 1.000 6.6 6.3 2.0 8.3 4.5 42 3 1 3
## 3 3.385 44.5 12.8 2.4 12.5 14.0 60 1 1 1
## 4 0.920 5.7 10.4 2.4 16.5 3.2 25 5 2 3
## 5 2547.000 4603.0 2.1 1.8 3.9 69.0 624 3 5 4
## 6 10.550 179.5 9.1 0.7 9.8 27.0 180 4 4 4
sleep.imp <- missForest(sleep)## missForest iteration 1 in progress...done!
## missForest iteration 2 in progress...done!
## missForest iteration 3 in progress...done!
## missForest iteration 4 in progress...done!
## missForest iteration 5 in progress...done!
## missForest iteration 6 in progress...done!
## missForest iteration 7 in progress...done!head(sleep.imp$ximp)## BodyWgt BrainWgt NonD Dream Sleep Span Gest Pred Exp Danger
## 1 6654.000 5712.0 3.237 1.1956 3.3 38.600 645 3 5 3
## 2 1.000 6.6 6.300 2.0000 8.3 4.500 42 3 1 3
## 3 3.385 44.5 11.218 2.5280 12.5 14.000 60 1 1 1
## 4 0.920 5.7 11.681 2.6150 16.5 6.343 25 5 2 3
## 5 2547.000 4603.0 2.100 1.8000 3.9 69.000 624 3 5 4
## 6 10.550 179.5 9.100 0.7000 9.8 27.000 180 4 4 4
Eğer kod yazımı ile uğraşmak istemiyorsanız çok beğendiğim bir kütüphaneyi sizlerle paylaşmak istiyorum. “MissingDataGUI” kütüphanesi. Bu paket ile kod yazmadan açılan pencerede tıklama ile analizleri yapabiliyoruz. İlerleyen zamanlarda R Studio programı üzerinden kod yazmayarak açılan pencereden işlerimizi halledebileceğimiz paketleri ve araçları göstereceğim. Bununla ilgili bir yazı yazmayı düşünüyorum. R programı kodlama bilmeden, kod yazmayı bilmeden de bazı analizleri yapabilmemize olanak sağlıyor.
Eksik veri ile alakalı olan paketi console kısmına “install.packages(”MissingDataGUI“)” yazarak ve paketi çağırarak kullanabilirsiniz. Ayrıca bu aynı durum “Amelia” kütüphanesi ile de mümkün. Bunun için “install.packages(”Amelia“)” yazdıktan sonra “AmeliaView()” ile çalıştırabilirsiniz. Daha bitmedi…. VIMGUI paketi ise en beğendiğim. Bunun içinde aynı şekilde bu paketi indirip, ardından bilgisayarınıza kurmanız gerekmektedir. Bu yazıda bu programı kullanmadım fakat bu paket ile çok güzel eksik veriyi görselleştirmeler ya da veriyi doldurken kullanacağı algoritmaları seçebilirsiniz. Kullanışlı, güzel birkütüphane.
Görüldüğü üzere eksik/kayıp veri bazı algoritmalar ile tamamlanabilmektedir. Eksik veri büyük bir problemdir evet ama “büyük bir problem” değildir. Asıl problem yansız tahmin edebilmek, bu yansızlığı ayarlayabilmek ve ona uygun yöntemi ya da doldurulacak veriyi ayarlamaktır. Biraz zaman, biraz istatistiksel bilgi ve tecrübe gerektirmektedir. Eğer zaman serisinde eksik veri analizi yapıyorsanız daha dikkatli olmalısınız, trend varsa yine az da olsa göz kararı olarak aralığı tahmin edebilirsiniz ama bilimsel hesaplamalarla bu işi yapmalı ve güvenirliğini arttırmalısınız.
Literatürden de görülebileceği gibi eğer kayıp verileriniz tamamıyla rastgele dağılmadığı durumlarda, eksik veri ile mücedele için daha fazla alan bilgisi gerekmektedir. TROK(Tamamıyla Rastlantısal Olarak Kayıp Veriler) olmayan veri setlerinde serilerin ortalaması, medyanı ya da basit atama ile yapılan doldurmaların(imputasyon) başarılı sonuçlar vermediği, bayesci istatistik yaklaşımları, makine öğrenmesi algoritmaları ise daha başarılı sonuçlar verildiği görülmüştür. Açıklanan varyansların oranlarına dikkat edilip, yanlılığın önüne geçmek gerekmektedir. Düşük eksik veriye sahip veri setleri ile çok sayıda eksik verilere sahip veri setleri karşılaştırıldığında, düşük eksik verilerin negatif yanlılık gösterildiği de değinilmiştir.
Eksik verileri doldururken veri setini değiştirdiğimizi unutmamız gerekmektedir. Bunun için verinin dağılımını hatta daha önemlisi “verinin karakterini” değiştirmeden atama yapmamız gerektiği unutulmamalıdır.
Varsayımlarınızın sağlanması dileğiyle,
Veri ile kalın, Hoşça kalın..
Kaynak: http://web.maths.unsw.edu.au/~dwarton/missingDataLab.html
Kaynak: Dokuz Eylül Üniversitesi İktisadi ve İdari Bilimler Fakültesi Dergisi, Cilt:25, Sayı:2, Yıl:2010, ss.73-83
Kaynak: Mehmet Akif Ersoy Üniversitesi Eğitim Fakültesi Dergisi, Eylül 2015, Sayı 35, 87 -111
Görsel Kaynaklar: www.trackpal.com/blog, https://blog.qlik.com/missing-data
Kaynak: https://www.kaggle.com/captcalculator/imputing-missing-data-with-the-mice-package-in-r