
![]()
Büyük veri analizi, günümüzün veri odaklı dünyasında giderek daha önemli hale geliyor. PySpark ve Jupyter Notebook, bu alanda en popüler araçlardan ikisi. PySpark, büyük veriyi işlemek için son derece hızlı ve ölçeklenebilir bir araçken, Jupyter Notebook ise PySpark ile etkileşimli veri analizi ve görselleştirme çalışmaları için sade ve konforlu bir ortam sunar.
Ancak, PySpark ve Jupyter Notebook’u geleneksel yöntemlerle kurmak, karmaşık ve zaman alıcı olabilir. Çoğu zaman paket ve versiyon çakışmaları can sıkıcı olabilir. Ayrıca ortam yönetimi gibi sorunlarla uğraşmanız gerekir. Neyse ki, Docker bu zorlukları ortadan kaldırmak için ideal bir çözüm sunar.
Bu blog yazısında, Docker kullanarak PySpark ve Jupyter Notebook’u nasıl hızlı ve kolay bir şekilde kurup, kullanabileceğimizi göreceğiz. Docker’ın izole edilmiş ortamlar yaratarak bağımlılık sorunlarını nasıl ortadan kaldırdığını ve kurulum sürecini nasıl basitleştirdiğini öğreneceksiniz. Yazı sonunda Jupyter üzerinde basit bir PySpark uygulaması geliştirmiş olacağız.
Ben çalışmalarımı linux bir bilgisayar üzerinde yaptım. MacOS için çok bir fark olacağını sanmam ancak Windows kullananlar bu örneği kendilerine uyarlamalılar. Tavsiyem sanal bir linux makine kullanmaları veya Windows’larda artık Windows Subsystem for Linux (WSL) özelliği var onu kullanmaları.
Kurulumun temelinde aslında spark docker imajı olacak. Tek bir konteyner kuracağız. Yine de docker-compose kullanmayı tercih edeceğim belki sizler yanına postgresql veya başka konteynırlar eklersiniz.
Ön gereksinimler
- Docker kurulu bir bilgisayar
- İnternet bağlantısı
Kurulum
Kendimize bir çalışma dizini yaratalım
(base) [train@trainvm ~]$ mkdir easy_spark_jupyter (base) [train@trainvm ~]$ cd easy_spark_jupyter/
Konteynır içinde yapacağımız kurulumlar, notebook, dosya, veri vb. için bir lokal volume oluşturacağım. Bunun için de bir klasör yaratalım ve sahipliğini değiştirelim.
(base) [train@trainvm easy_spark_jupyter]$ mkdir spark_v (base) [train@trainvm easy_spark_jupyter]$ sudo chown 185:185 -R spark_v/ (base) [train@trainvm easy_spark_jupyter]$ ls -l drwxrwxr-x. 2 185 185 6 May 5 08:15 spark_v
Peki neden 185? spark docker imajını incelediğimizde Dockerfile içinde ARG spark_uid=185 ifadesini görüyoruz. Buradan konteynıra bağlandığımızda içeride spark kullanıcısının 185 id numarasına sahip olacağını anlıyoruz. Amacımız konteynır içindeki kullanıcının elini rahatlatmak o yüzden daha konteynır yaratmadan volume olarak kullanılacak klasör yetkilerini spark(185) kullanıcısına veriyoruz.
Docker Compose dosyası
version: '3.8'
services:
spark:
image: spark:3.5.1
container_name: spark
ports:
- "4040:4040"
- "8888:8888"
volumes:
- ./spark_v:/home/spark
command: sleep infinityDocker compose çalıştıralım
docker-compose up -d docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 3db466fe29dc spark:3.5.1 "/opt/entrypoint.sh …" 27 seconds ago Up 26 seconds 0.0.0.0:4040->4040/tcp, :::4040->4040/tcp, 0.0.0.0:8888->8888/tcp, :::8888->8888/tcp spark
spark konteynıra bağlanalım.
docker exec -it spark bash
Volume ile bağladığımız /home/spark diznine geçelim.
cd /home/spark/
Burada kendimize bir python virtual environment oluşturalım. Bunun için virtualenv paketini kullanacağız ancak sanırım bu yüklü değil. Kontrol edelim.
python3 -m virtualenv .venv /usr/bin/python3: No module named virtualenv
pip ile virtualenv kuralım
python3 -m pip install virtualenv
Şimdi virtualenv ile .venv adında bir virtual environment oluşturalım ve aktif hale getirelim.
spark@3db466fe29dc:~$ python3 -m virtualenv .venv
created virtual environment CPython3.8.10.final.0-64 in 1649ms
creator CPython3Posix(dest=/home/spark/.venv, clear=False, no_vcs_ignore=False, global=False)
seeder FromAppData(download=False, pip=bundle, setuptools=bundle, wheel=bundle, via=copy, app_data_dir=/home/spark/.local/share/virtualenv)
added seed packages: pip==24.0, setuptools==69.5.1, wheel==0.43.0
activators BashActivator,CShellActivator,FishActivator,NushellActivator,PowerShellActivator,PythonActivator
spark@3db466fe29dc:~$ source .venv/bin/activate
(.venv) spark@3db466fe29dc:~$ pwd
/home/spark
En alttan bir üstteki satırda soldaki (.venv) görüyorsunuz. Artık virtual environment hazır. Buraya ne paket yüklerseniz yükleyin konteynır kapatılıp açıldıktan sonra kaybolmayacak. Çünkü burası yani /home/spark dizini volume ile güvence altında.
Paketleri yükleme
pip install jupyterlab findspark pandas
Jupyter Lab başlatma
jupyter lab --ip 0.0.0.0 --port 8888
En alttaki url’i alıp tarayıcınıza yapıştırın. Jupyter karşınıza çıkacaktır. Aşağıdaki örnektir sizde çalışmaz.
http://127.0.0.1:8888/lab?token=e7ef992ff73678072dce9b22a70930bf811587aa4852b480
Eğer ip numaranız 127.0.0.1’den farklı ise 127.0.0.1 yerine kendi ip numaranızı değiştirip kullanın.
PySpark Uygulaması
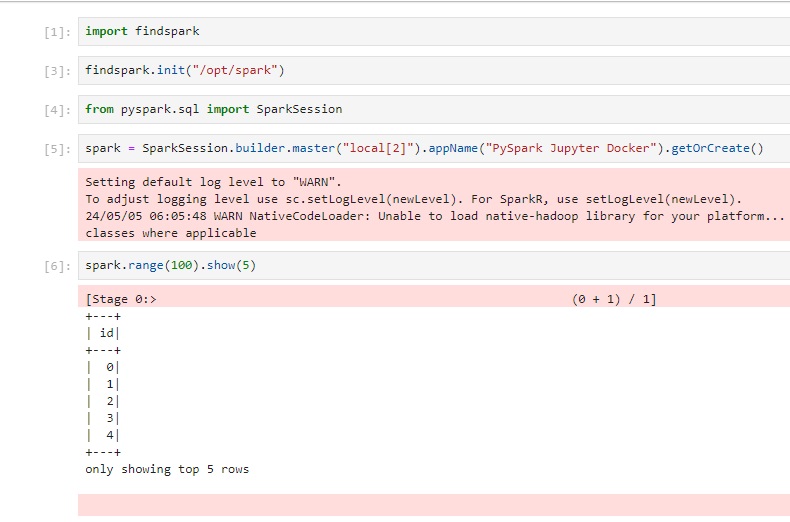
Yeni bir notebook yaratıp aşağıdaki ekran görüntüsündeki gibi basit bir spark uygulaması yazabilirsiniz.
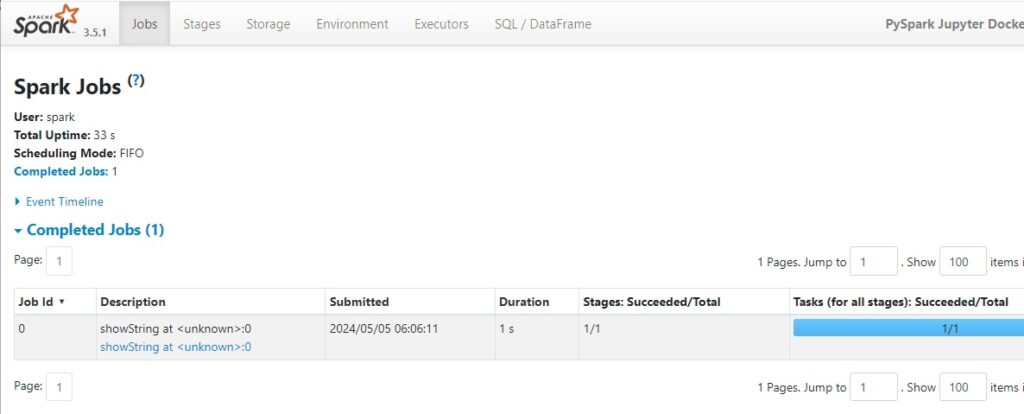
Benzer şekilde http://127.0.0.1:4040/ adresinden Spark UI görebilirsiniz.
Ortamı Kapatıp Tekrar Açma
Terminalde Ctrl+C ile Jupyter Lab’ı durduralım. Konteynırdan çıkalım ve docker compose ile konteynırı durduralım. Sırasıyla;
Ctrl+C exit docker-compose down
Yeniden ortamı hazırlayalım.
docker-compose up -d docker exec -it spark bash # Inside container cd /home/spark/ source .venv/bin/activate jupyter lab --ip 0.0.0.0 --port 8888
Jupyter’i açtığınızda aynı notebook orada hazır olacaktır. Tekrar çalıştırdığınızda PySpark uygulaması çalışacaktır. Gördüğünüz gibi yeniden hiç bir kurulum, paket yükleme vb. yapmadık.
Data Engineering konusunda çok daha fazlasını öğrenmek ve bir kariyer olarak seçmek isterseniz Data Engineering Bootcamp programımızı tavsiye ederim.
Bir sonraki yazıya dek çav…
Kaynaklar
Kapak Görseli: ThisisEngineering on Unsplash
Eline,emeğine sağlık Erkan ŞİRİN hocamız, gençler için güzel bir hizmet olmuş