

![]()
Yeniden merhaba!
Hemen hemen her yazımızda veri analitiğinin, karmaşık ve dinamik bir süreç olduğuna değiniyoruzdur. Büyük veri setleri, farklı kaynaklardan gelen veri çeşitliliği ve hızla değişen iş gereksinimleri, veri analistlerine ve mühendislerine zorlayıcı bir ortam yaratıyor. Geleneksel veri yapıları ve analitik yöntemler, bu hızlı değişime ayak uydurmakta zorlanırken ve süreçler zaman alıcı ve karmaşık hale geliyor. Bu yazıda bu zorluklarla başa çıkmak ve veri analitiği süreçlerini modernleştirmek için tasarlanmış dbt üzerine konuşacağız.🤩
dbt veya “data build tool”, analitik kodların modülarize edilmesini ve merkezileştirilmesini sağlayan bir araçtır. Temel amacı, veri ekiplerine veri setlerini hazırlama, işleme ve belirli analitik sorulara cevap bulma konusunda yazılım mühendisliğinin pratiklerini sunarak yardımcı olmaktır.
Bu amacı için:
- Veri modelleri (analitik sorgular) üzerinde iş birliği yapmayı,
- Geliştirme sürecinin kontrolü için sürümlendirmeyi (burada kastedilen git/github VCS ile dbt projesinin entegre edilebiliyor olmasıdır),
- Sorgularınızı güvenli bir şekilde canlı ortama dağıtmadan önce test etmeyi ve belgelemeyi
mümkün kılar.
DBT iki farklı şekilde karşımıza çıkmaktadır.
- dbt Core : Yerel olarak yüklenebilen açık kaynaklı bir komut satırı aracıdır ve veritabanlarıyla iletişim bağdaştırıcılar (adapters) aracılığıyla sağlanır.
- dbt Cloud : dbt Core bulut tabanlı entegre geliştirme ortamı olarak sunulur. Kullanıcı arayüzü, CI/CD, izleme (monitoring) ve uyarılar (alerting) gibi bileşenleri mevcuttur. Aynı zamanda entegre bir geliştirme ortamı (IDE) sunar ve yerel komut satırınızdan (CLI) veya kod düzenleyicinizden dbt komutları geliştirmenize ve çalıştırmanıza olanak tanır.
dbt projesinin genel yapısı nedir? Hangi bileşenlerden oluşur? 👀👇
Bir dbt projesi, projenizin bağlamı ve verilerinizi nasıl dönüştüreceğiniz hakkında tüm bilgileri içerir. Her proje minimumda “dbt_project.yml” dosyasına ihtiyaç duyacaktır. Proje ayrıca aşağıdakileri (ve daha fazlasını) içerebilir:
- models: Geliştiricilerinizin zamanlarının çoğunu bir dbt ortamında geçirdikleri yerdir. Modeller öncelikle bir select ifadesi olarak yazılır ve .sql olarak kaydedilir.
- seeds: dbt projenizdeki (genellikle seeds dizininizde bulunan) CSV dosyalarıdır ve dbt, “dbt seed” komutunu kullanarak veri ambarınıza yükleyebilir.
- tests: dbt projenizdeki modelleriniz ve diğer kaynaklarınız (ör. sources, seeds ve snapshots) hakkında yaptığınız iddialardır. dbt testini çalıştırdığınızda, dbt size projenizdeki her testin başarılı mı yoksa başarısız mı olduğunu söyleyecektir.
- macros: Birden çok kez yeniden kullanılabilen kod parçalarıdır.
Tasarım gereği dbt, “dbt_project.yml” dosyası, “models” dizini, “snapshot” dizini vb. gibi üst seviye yapıyı zorunlu kılmaktadır. Bahsi geçen üst seviye dizinler içerisinde projenizi, kuruluşunuzun ve veri hattınızın ihtiyaçlarını karşılayacak şekilde düzenleyebilirsiniz. Bir dbt kullanıcısı olarak asıl odak noktanız, temel iş mantığını yansıtan “models” (örn. select sorguları) yazmak olacaktır. dbt, bu modellerin nesnelere dönüştürülmesini sizin için gerçekleştirecektir.
Yazının devamında Apache Spark ile DBT kullanımı açısından bir örnek yapacağız, DBT’nin çalışma mantığını ve yapısal kavramları yine örnek ile anlamaya çalışacağız. Farklı bir veri platformuna bağlanmak isterseniz, buna yönelik gereklilikleri dbt dokümanlarındaki ilgili sayfada bulabilirsiniz.
Örnek Çalışma
Başlamadan önce çalışmanın gerekliliklerine değinelim:
- Docker’da çalışan Spark Thrift sunucu ve Hive-metastore olarak çalışacak bir Postgresql veri tabanı
- Bu çalışma özelinde oluşturulmuş bir Python sanal ortamı (>= 3.8)
- Linux işletim sistemi
- dbt-labs’a ait repoda bulunan veri setleri ve modeller
İki temel adımda ilerleyeceğiz:
- Veri platformu/kaynağı simülasyonu
- dbt projesinin oluşturulması ve çalıştırılması
Ve başlıyoruz! 💕
1. Veri platformu/kaynağı simülasyonu
- Öncelikle, örnek veri setlerini Spark-Thrift sunucusuna kopyalamamız gerekiyor. (Tabi bu veriler gerçekte büyük veri depolama sistemlerinde saklanır, burada verileri spark sunucusunda csv olarak tutacağız.
cd /path/to/your/datasets
docker cp . <spark_thrift_container_id>:/opt
- Spark thrift sunucusuna bağlanalım.
docker-exec -it <container_id> bash
- Beeline’ı çalıştıralım ve Hive’a bağlanalım.
/usr/spark/bin/beeline
!connect jdbc:hive2://localhost:10000
- Tablolarımızı oluşturalım.
CREATE TABLE default.raw_customers (
id int,
first_name string,
last_name string
)
USING CSV
OPTIONS (path "/opt/raw_customers.csv",
delimiter ",",
header "true");
CREATE TABLE default.raw_orders (
id int,
user_id int,
order_date date,
status string
)
USING CSV
OPTIONS (path "/opt/raw_orders.csv",
delimiter ",",
header "true");
CREATE TABLE default.raw_payments (
id int,
order_id int,
payment_method string,
amount bigint
)
USING CSV
OPTIONS (path "/opt/raw_payments.csv",
delimiter ",",
header "true");
- Tablo ve verileri kontrol edelim.
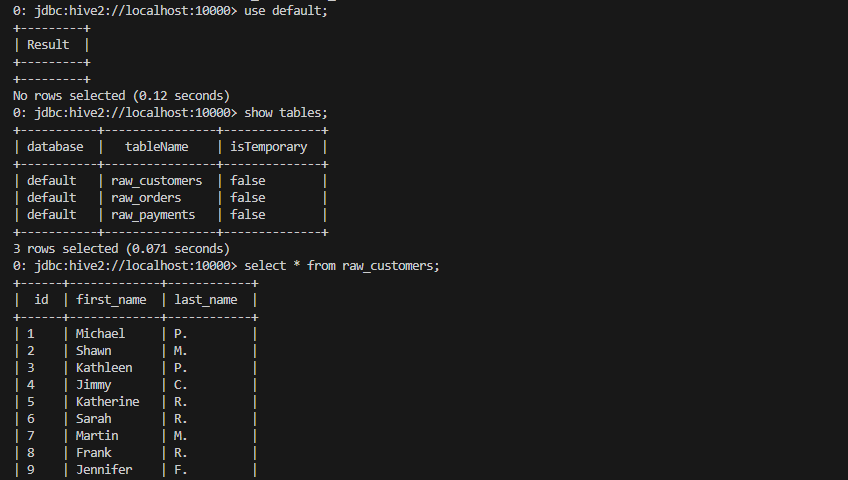
Veri platformunu simüle ettik ve verilerimiz hazır. Şimdi bu verilerimiz üzerinde çalışacağız .😉 (Bu çalışmada dbt seed komutuyla nasıl aktarım yapılabileceği kısmına girmedik)
2. dbt projesinin oluşturulması ve çalıştırılması
- Sanal ortamımızı aktif hale getirelim ve ihtiyacımız olan dbt kütüphanesini indirelim.
source dbt-env/bin/activate
pip install "dbt-spark[PyHive]"
- Şimdi “tutorial_spark” adında bir dbt projesi başlatalım.
dbt init tutorial_spark
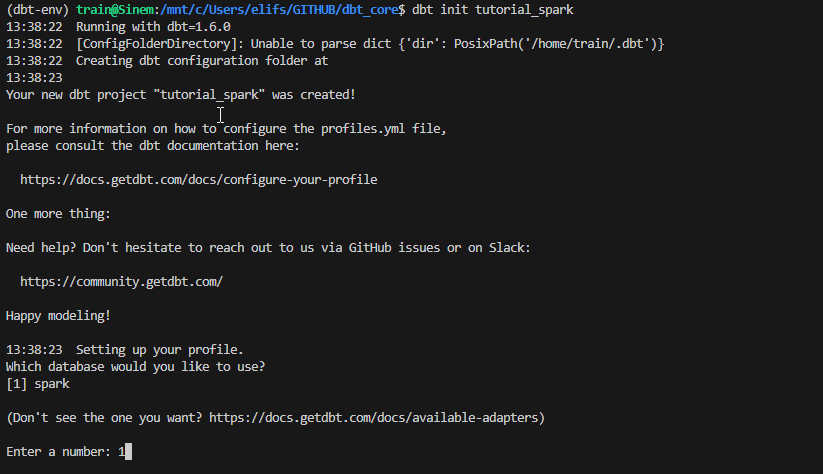
- Başlatma işleminde dbt bazı seçenekler yönlendirilecek, burada veri platformuna ait host ve port bilgilerini, ayrıca hangi şemaya yazmak istediğimiz bilgisini vereceğiz. Ek olarak, bizden bir “thread” isteyecek, bunun sebebi ise şu; dbt çalıştırıldığında, modeller arasındaki bağlantıların DAG’ını (a Directed Acyclic Graph) oluşturur ve “thread” sayısı, dbt’nin aynı anda üzerinde çalışabileceği grafikteki maksimum yol sayısını temsil eder. Yani, “threads: 1” olarak belirtirseniz, dbt yalnızca bir model oluşturmaya başlayacak ve bir sonrakine geçmeden önce onu bitirecektir. Aşağıda solda görüleceği üzere, bize bir proje strüktürü oluşturdu bile. Alt klasör isimlerinden bazıları tanıdık geldi değil mi😌

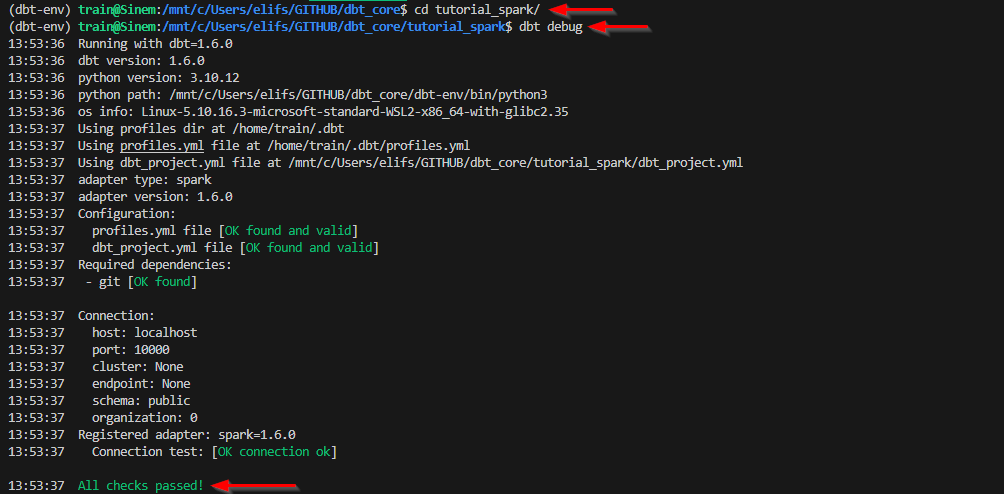
- Bir terslik olup olmadığını kontrol etmek için de önerisini yerine getirelim.😅 Önce oluşturduğu dizine gidelim ve debugging işlemini başlatalım. Aşağıda görüleceği şekilde kontrol işleminden geçtik.
cd tutorial_spark
dbt debug
- Şimdi çalışmanın başında edindiğimiz örnek modelleri tutorial_spark altına kopyalayalım/taşıyalım. Yukarıda da sözü geçtiği şekilde models klasörü ana yapı taşlarından biridir.
cp /path/to/your/models/* /path/to/yout/tutorial_spark/models
- Listelediğimizde aşağıdaki gibi dosyalarımız ve klasörlerimiz artık mevcut. (example klasörü “dbt init” dediğimizde default olarak geliyor)
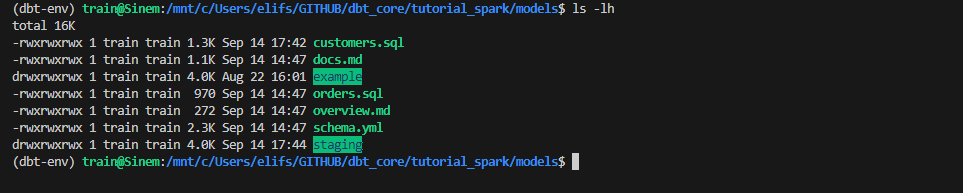
- Vee dbt’yi harekete geçirelim.
dbt run
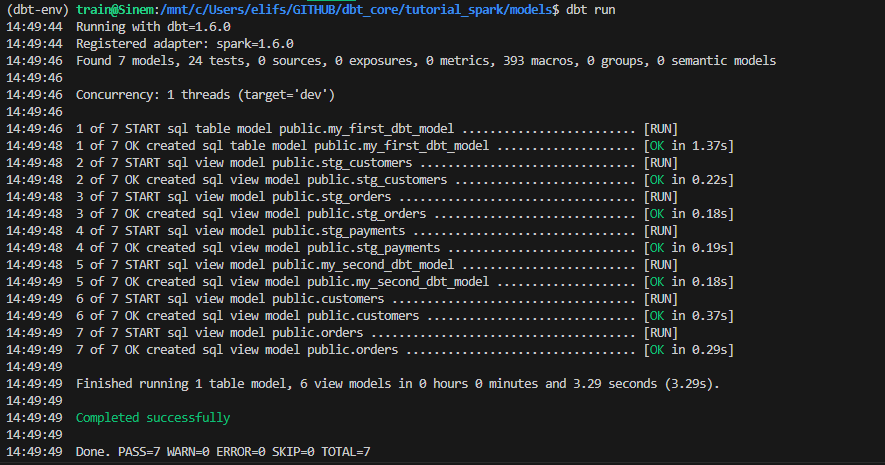
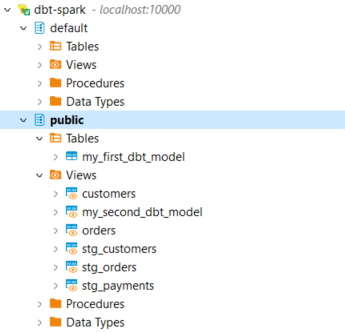
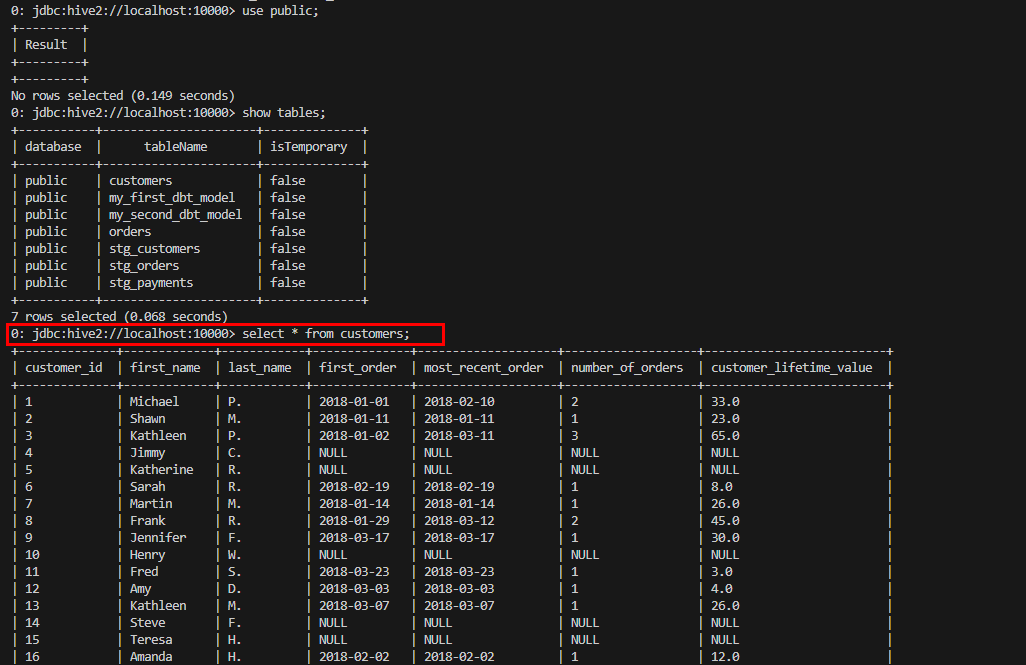
- Son olarak table/viewlarımız oluşmuş mu bakalım. 🤩
Değerlendirme
Peki tüm bunlar nasıl oldu ?😅
dbt run, models klasörü altında derlenmiş sql model dosyalarını bizim geçerli kıldığımız veri platformunda çalıştırdı. Modeller, derleme sırasında oluşturulan bağımlılık grafiğinin tanımladığı sırayla çalıştırıldı. (Daha detaylı bilgi için yine ilgili dokümana göz atmanızı öneririm)
Aşağıdaki ekran alıntılarında görüleceği üzere models/staging klasöründe bulunan modeller bir ara adım olarak çalıştı, customers.sql ve orders.sql modelleri ile bu sayede customers ve orders “view”ları oluşturuldu. Burada ayrıca Jinja template kullanıldığını görüyoruz. dbt’de SQL, bir şablon dili olan Jinja ile birleştirilebiliyor, Jinja’yı kullanmak dbt projenizi SQL için bir programlama ortamına dönüştürüyor ve normalde SQL’de mümkün olmayan şeyleri yapmanıza imkan sağlıyor.


Biz “dbt init” komutuyla beraber oluşturulan klasör/dosya yapısını ve içeriğini koruduk ve dbt_project.yaml dosyasında herhangi bir değişiklik yapmadık. Şimdi, dbt_project.yaml dosyasında models bölümüne bir bakalım. Burada example klasörü altındaki modeller için “view” olarak oluşturulması gerektiği belirtilmiş (ön tanımlı olarak da bütün modeller “view” olarak materyalleştirilir). Peki neden my_first_dbt_model tablo olarak oluştu?


my_first_dbt_model.sql dosyasına göz attığımızda, burada tablo olarak oluşturulması (materyalize edilmesi) gerektiği belirtilmiş ve sonuç da bu şekilde. Yani şunu anlıyoruz, biz dbt_project.yaml dosyasındaki konfigürasyonların haricinde, modeller aracılığı ile de özelleştirme yapabiliyoruz (bir nevi, sql dosyasında belirttiğimiz konfigürasyon, yaml dosyasını eziyor:)).

Bu yazıyı burada sonlandırmak istiyorum çünkü böyle kapsamlı bir aracın tüm özelliklerini buraya sığdırmak neredeyse imkansız. Test etme, belgelendirme ve sürümlendirme (versiyon) gibi başlıklara ait örneklere belki başka bir zaman değiniriz. Ancak dbt’nin sunabilecekleri konusunda bir merak uyandırdım diye düşünüyorum.😏 Burada anlattığım gibi, veri analitiği süreçlerinizi yalınlaştırmak, standartlaştırmak ve hızlandırmak istiyorsanız, dbt’yi çalışmalarınıza dahil etmenizi önerebilirim.
Bir sonraki yazıda görüşmek üzere! 🙋♀️
Kaynaklar
dbt docs: https://docs.getdbt.com/docs/introduction
dbt-labs github docs: https://github.com/dbt-labs/jaffle_shop