

24 toplam görüntülenme , 1 views today
Herkese merhaba!
Bu yazıya giriş yaparken yine “verinin giderek artan hacmi ve önemi” hakkında birkaç cümle yazmayı düşünüyordum, ancak bu farkındalık noktasına bence çoktan ulaştık😉 Geçmişten günümüze veri hacmindeki artış sürerken, büyük veri kümelerini anlamlı ve kullanışlı bilgilere dönüştürmek için, yüksek performanslı ve ölçeklenebilir veri işleme çözümlerine ihtiyaç duyulmuş, böylece paralel hesaplama ve dağıtık sistemler gibi teknolojiler geliştirilmiştir. Bu sistemler, veriyi parçalara bölerek ve bu parçaları birden fazla işlemci veya bilgisayarda işleyerek işlem hızını önemli ölçüde artırmayı sağlamıştır. Bu durum, geleneksel veri tabanlarının sınırlarını aşan ve büyük veri kümeleriyle etkin bir şekilde başa çıkabilen yeni nesil veri depolama ve işleme çözümlerine olan ihtiyacı da beraberinde getirmiştir. İşte bu noktada, ClickHouse gibi yüksek performanslı ve ölçeklenebilir çözümler ön plana çıkmıştır.
Bu makalede, ClickHouse’un ne olduğunu, nasıl çalıştığını ve neden giderek daha popüler hale geldiğini inceleyeceğiz. Ayrıca, bu güçlü aracın kullanım alanlarına ve avantajlarına da detaylı bir şekilde değineceğiz. Veri dünyasında yeni ufuklar keşfetmek ve veri işleme süreçlerinizi optimize etmek için bu defa ClickHouse’u keşfe çıkıyoruz. Hadi!🤩
ClickHouse nedir?
ClickHouse, Yandex.Metrica için geliştirilmiş olan, çevrimiçi analitik işleme (OLAP) için yüksek performanslı, sütun odaklı bir SQL veri tabanı yönetim sistemidir (DBMS). Hem açık kaynaklı olarak , hem de sunucusuz (serverless) bir hizmet olarak bulutta ( ticari amaçlı ) sunulmaktadır.
Bu tanıma istinaden, öncelikle OLTP ve OLAP kavramlarını bir tekrar hatırlayalım:
- OLTP (Online Transactional Processing): “Çevrimiçi -İşlem- İşleme” anlamına gelir. Herhangi bir kuruluştaki günlük işlemleri yönetme görevine sahiptir. Temel amacı veri analizi değil, veri işlemedir. İnternet bankacılığı, çevrimiçi uçak bileti rezervasyonu, alışveriş sepetine kitap ekleme gibi işlemler için kullanımı örnek olarak verilebilir.
- OLAP (Online Analytical Processing): “Çevrimiçi -Analitik- İşleme” anlamına gelir. Karar destek sistemleri ve raporlama için veri analizi sağlayan sitemlerdir. Bu sistemlerdeki asıl amaç ise veriyi işlemek değil, analiz etmektir. Kullanıcıya özgü ürün, şarkı, film vb. listelerin oluşturulması için kullanıcı davranışlarının analiz edilmesi de burada örnek olarak gösterilebilir.
OLTP, veri tabanlarındaki birden fazla işlem akışını yönetmek ve depolamak için ideal çözüm olarak nitelendirilebilir, ancak veri tabanından karmaşık sorgular gerçekleştirmek için uygun değildir. Bu nedenle iş analistleri çok boyutlu verileri analiz etmek için OLAP sistemini kullanır. OLAP senaryoları, aşağıdaki özelliklere sahip karmaşık analitik sorgular için büyük veri kümelerinin üzerinde gerçek zamanlı yanıtlar gerektirir:
- Veri kümeleri çok büyük olabilir (milyarlarca veya trilyonlarca satır).
- Veriler birçok sütun içeren tablolarda düzenlenir.
- Belirli bir sorguyu yanıtlamak için yalnızca birkaç sütun seçilir.
- Sonuçlar milisaniye veya saniye cinsinden döndürülmelidir.
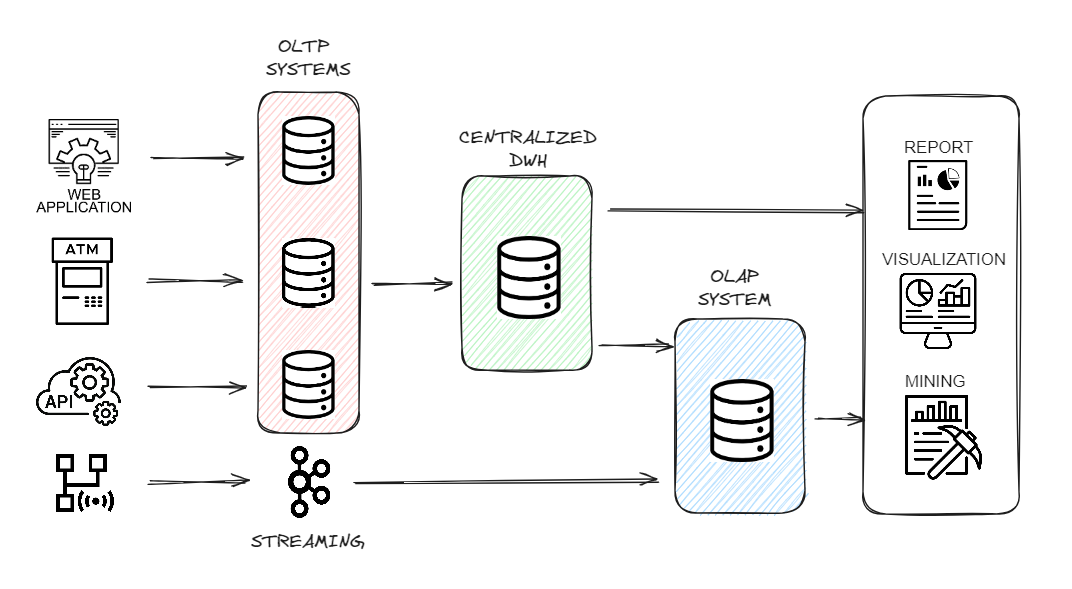
Peki, satır ve sütun odaklı ne demek, bunlar arasındaki farkı da gözden geçirelim:
- Satır odaklı veri tabanları (Row-oriented databases): Verileri kayıtlara göre düzenleyen, bir kayıtla ilişkili tüm verileri yan yana bellekte tutan veri tabanlarıdır. Satır odaklı veri tabanları, verileri organize etmenin geleneksel yoludur ve yine de verilerin hızlı bir şekilde depolanması konusunda bazı önemli faydalar sağlar. Satırları verimli bir şekilde okumak ve yazmak için optimize edilmiştir. (Örneğin, Postgresql, MySQL)
- Sütun odaklı veri tabanları (Column-oriented databases): Verileri alanlara göre düzenleyen ve bir alanla ilişkili tüm verileri bellekte yan yana tutan veri tabanlarıdır. Sütun tabanlı veri tabanları popülerlik kazanmış ve veri sorgulamada performans avantajları sağlamıştır. Sütunlar üzerinde verimli bir şekilde okuma ve hesaplama yapmak için optimize edilmişlerdir. (Örneğin, ClickHouse, Redshift, BigQuery)
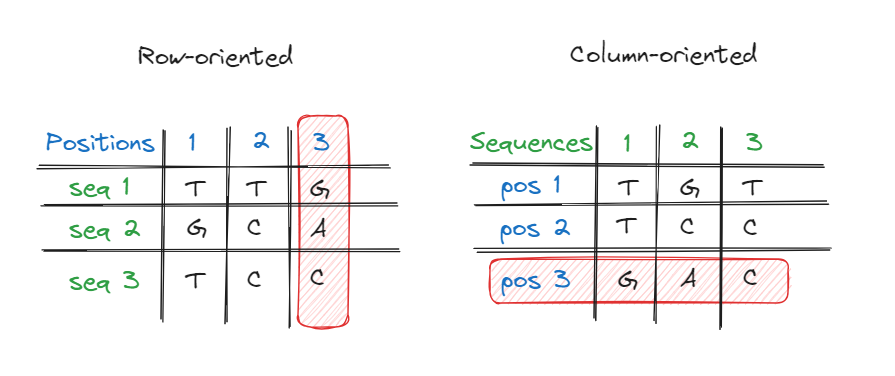
Böylece ClickHouse’un üzerine inşa edildiği genel kavramları hatırlamış olduk.
Mimariye genel bakış
ClickHouse’un mimarisi, verilerin depolanması, sorgulanması ve yönetilmesi için ölçeklenebilir ve yüksek performanslı bir çözüm sunar. Bileşenleri şu şekilde özetleyebiliriz:
Replica ve Shard Yapısı
ClickHouse, veri güvenilirliği ve yüksek erişilebilirlik sağlamak için bir replica ve shard yapısına sahiptir.
Replica : Replica, bir veri setinin kopyalarından biridir ve veri güvenilirliğini sağlamak için kullanılır. Her replica, verilerin tam bir kopyasını içerir ve herhangi bir replica arızalandığında diğer replica’lar aracılığıyla verilere erişim sağlanabilir. Replica, veri kaybını önlemek ve sistem kesintilerine karşı dirençli bir yapı oluşturmak için kullanılır.
Shard: Shard, bir replica içindeki verilerin bölündüğü parçalardır. Shard’lar, verilerin dağıtık bir şekilde saklanmasını ve işlenmesini sağlar. Her shard, bir veya daha fazla sunucu üzerinde çalışabilir ve belirli bir veri alt kümesini temsil eder. Sharding, veri kümesini paralel olarak işlemek ve yüksek performans sağlamak için kullanılır.
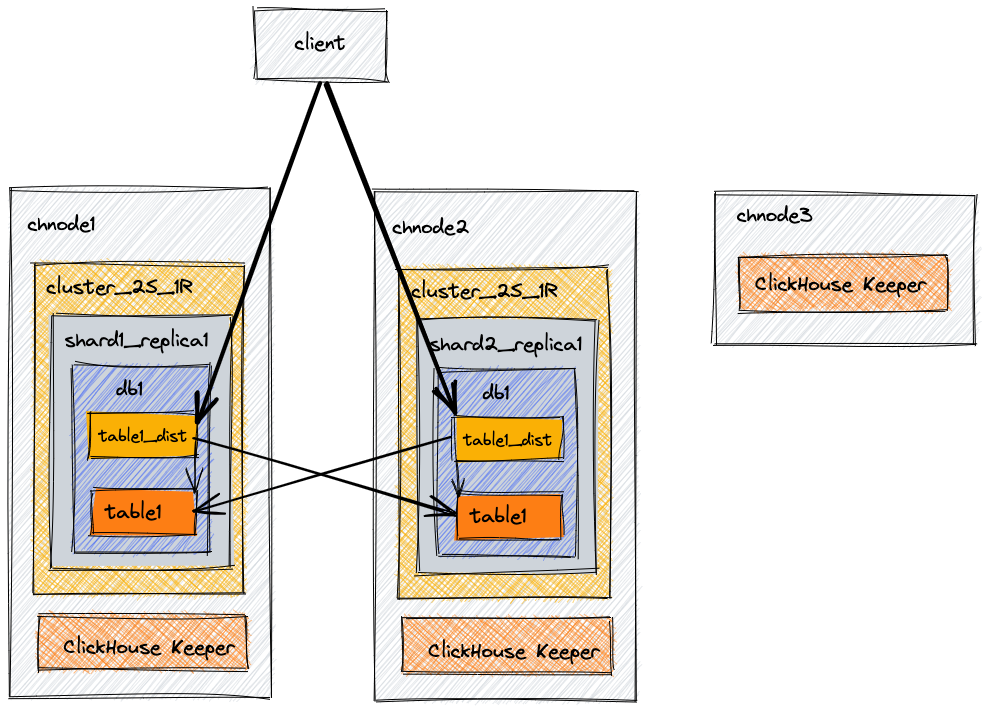
Dağıtık Sistem
ClickHouse, dağıtık bir sistem olarak tasarlanmıştır ve birden fazla sunucu üzerinde çalışabilir. Dağıtık sistem, veri işleme yükünü paylaştırarak ölçeklenebilirlik sağlar. Bu, büyük veri kütleleri üzerinde hızlı ve etkili sorgu yanıtları elde etmek için önemlidir.
Veri Yönetimi
ClickHouse, verilerin depolanması, yönetilmesi ve erişilmesi için optimize edilmiş bir yapıya sahiptir. Veri partisyonlama, sıkıştırma, indeksleme ve optimizasyon gibi işlemler otomatik olarak gerçekleştirilir. Bu, veri yönetiminin daha verimli ve etkili olmasını sağlar.
Yük Denkleme ve Yüksek Erişilebilirlik
ClickHouse, yük denkleme ve yüksek erişilebilirlik için özel olarak tasarlanmıştır. Veri replikasyonu ve failover mekanizmaları sayesinde, sistem kesintilerine karşı dirençli bir yapı sağlar.
Bu genel yapısal bileşenler, ClickHouse’un yüksek performanslı, ölçeklenebilir ve güvenilir bir çözüm olmasını sağlar.
ClickHouse neden bu kadar hızlı?
ClickHouse da başlangıçta –verileri olabildiğince hızlı filtrelemek (to filter) ve toplamak(to aggregate)- için bir prototip olarak oluşturulmuştur. Bu görevin başarılmasını mümkün kılmak için de aşağıdaki başlıklara odaklanılmıştır:
- Sütun odaklı depolama: Sütun odaklı veri tabanları OLAP senaryolarına daha uygundur. Toplu veri analizleri için optimize edilmesi ve sorguların sadece ilgili sütunları işlemesine izin vermesi işlem hızını artırır. (Kaynak veriler genellikle yüzlerce hatta binlerce sütun içerirken bir rapor bunlardan yalnızca birkaçını kullanabilir. ) Pahalı disk okuma işlemlerinden kaçınmak için sistemin gereksiz sütunları okumaktan kaçınması gerekir.
- İndeksler: Bellekte yerleşik ClickHouse veri yapıları yalnızca gerekli sütunların ve bu sütunların yalnızca gerekli satır aralıklarının okunmasına olanak tanır.
- Veri sıkıştırma: Aynı sütunun farklı değerlerinin bir arada saklanması genellikle daha iyi sıkıştırma oranlarına yol açar (satır odaklı sistemlerle karşılaştırıldığında), çünkü gerçek verilerde bir sütun, komşu satırlar için genellikle aynı veya çok fazla farklı değerlere sahip değildir. Genel amaçlı sıkıştırmaya ek olarak ClickHouse, verileri daha da kompakt hale getirebilecek özel codec bileşenlerini destekler.
- Vektörleştirilmiş sorgu yürütme: ClickHouse yalnızca verileri sütunlarda depolamaz, aynı zamanda sütunlardaki verileri de işler. Bu, daha iyi CPU önbellek kullanımına yol açar ve SIMD CPU talimatlarının kullanımına izin verir.
- Ölçeklenebilirlik: ClickHouse, tek bir sorguyu bile yürütmek için mevcut tüm CPU çekirdeklerinden ve disklerinden yararlanabilir (bu bir sunucu veya bir küme (cluster) olabilir).
Bir çok veri tabanı yönetim sistemi benzer teknikleri kullanırken, ClickHouse’u farklı kılan konular ise şunlar:
- Belirli Görevler için Mikro Optimizasyon: ClickHouse, hash tabloları ve sorting algoritmaları gibi ortak veri tabanı işlemlerinin ince ayarına odaklanır. Genel uygulamalara güvenmek yerine, her bir sorgu için en verimli varyasyonu seçmek üzere veri boyutu, bellek düzeni ve erişim modelleri gibi faktörleri dikkate alır. Düşük seviyeli ayrıntılara verilen bu titiz dikkat, önemli performans kazanımlarına yol açar.
- Veriye Duyarlı Algoritma Seçimi: ClickHouse genel algoritmaları körü körüne uygulamaz. İşlenen verileri (sayılar, diziler, yapılar vb.) analiz eder ve yaklaşımını buna göre uyarlar. Buna kısmi sıralama, kararlı sıralama, bellek içi işleme ve verileri önceden getirme gibi hususlar dahildir. ClickHouse, veri özelliklerini anlayarak görev için en uygun algoritmayı seçer ve bu da daha hızlı yürütme sağlar.
- Sürekli Karşılaştırma ve Entegrasyon: ClickHouse ekibi, “en iyisi” olarak lanse edilen yeni algoritmaları ve veri yapılarını aktif olarak arar ve değerlendirir. Bu durum, ClickHouse’un en son gelişmelerden yararlanmasını ve performansın ön saflarında kalmasını sağlar.
Kullanım senaryoları ve örnek uygulama
ClickHouse’un kullanımı aşağıdaki senaryolarda rahatlıkla değerlendirilebilir:
- Gerçek zamanlı veri analitiği
- Günlük (log), olay (event) ve iz (trace) gözlemleme
- İş zekası ve raporlama
- Makine öğrenmesi ve üretici yapay zeka
Ayrıca ClickHouse Azure Blob Storage, DeltaLake, HDFS, Kafka, Postgresql gibi bir çok harici sistemle entegre edilebilmektedir. Hangi entegrasyonu kullanacağınız tamamen ihtiyacınıza bağlı tabii.
Bu yazıda, Postgresql, ClickHouse ve Superseti nasıl entegre edeceğimize değineceğiz. Microsoft’un sağladığı “AdventureWorksDw” veri setlerini kaynak olarak değerlendireceğiz ve şu şekilde ilerlerleyeceğiz:
- Docker ile Postgresql, ClickHouse, Superset konteynerleri oluşturma (ClickHouse’u tek node olarak kullanacağız)
- Postgresql’e veri setlerini yükleme
- Postgresql ile ClickHouse bağlantısını kurma
- Superset yapılandırma
- Superset ve ClickHouse bağlantısını kurma
1.Docker ile Postgresql, ClickHouse, Superset konteynerleri oluşturma
- docker-compose.yaml dosyasını aşağıdaki şekilde ayarlayalım. (Tabi normalde şifreleri açıkça yazmıyoruz değil mi:))
version: '3.7'
services:
# CLICKHOUSE - default
clickhouse:
container_name: clickhouse
image: clickhouse/clickhouse-server
ports:
- "8123:8123"
- "9000:9000"
volumes:
- clickhouse_data:/var/lib/clickhouse/
environment:
- CLICKHOUSE_DB=clickhouse_db
- CLICKHOUSE_USER=clickhouse
- CLICKHOUSE_DEFAULT_ACCESS_MANAGEMENT=1
- CLICKHOUSE_PASSWORD=Ankara06
# POSTGRESQL - Adventureworks
postgresql:
container_name: postgresql
image: erkansirin78/postgresdata-101:15
ports:
- "5432:5432"
environment:
- POSTGRES_USER=postgres
- POSTGRES_PASSWORD=Ankara06
volumes:
- postgresql_data:/var/lib/postgresql/data
restart: always
# SUPERSET - default
superset:
container_name: superset
restart: always
build: ./superset
image: superset_clickhouse
volumes:
- ./superset/superset-conf/config:/etc/superset
- ./superset/superset-conf/data:/var/lib/superset
- superset_data:/app/superset_home
ports:
- "8088:8088"
environment:
- SUPERSET_SECRET_KEY=9XR8sk0Xt9MYCb7lvi/2wNtlUU/YC/1xX8UGIUO1uUdX2BcLXlwjpEhI
volumes:
postgresql_data:
clickhouse_data:
superset_data:- Superset’in ClickHouse bağlantısını kurabilmemiz için, ClickHouse sürücüsünü indirmemiz gerekiyor. Bunu Dockerfile kullanarak, baz imaj üzerine ekleyeceğiz. Bu yüzden öncelikle docker-compose dosyası ile aynı dizinde bir “superset” klasörü oluşturalım. Ardından bu dizine geçerek Dockerfile oluşturalım.
mkdir superset cd /superset touch Dockerfile
- Dockerfile içeriği de aşağıdaki gibi olacak.
FROM apache/superset # Switching to root to install the required packages USER root # Example: installing the Clickhouse driver to connect RUN pip install clickhouse-connect # Switching back to using the `superset` user USER superset
- Konteynerleri çalıştıralım.
docker-compose up --build -d
2.Postgresql’e veri setlerini yükleme
- Postgresql shell’ine bağlanalım
docker exec -it postgresql psql -U postgres
- Veri ambarı için verileri yükleyelim
create database adventureworksdw; \c adventureworksdw; \i AdventureWorksDW2012.sql
Artık verilerimiz Postgresql’de hazır durumda:)
Not: Aynı terminali kullanmaya devam etmek istiyorsak ctrl + D ile çıkış yapalım veya yeni bir terminal açarak aşağıdaki adımları takip etmeye devam edelim.
3. Postgresql ile ClickHouse bağlantısını kurma
Postgresql’de bulunan veriye ClickHouse ile ulaşmanın bir kaç farklı yolu buluyor:
- Postgresql fonksiyonu kullanmak.
- Postgresql tablo motoru kullanarak tablo oluşturmak.
- Postgresql veri tabanı motoru kullanarak veri tabanı oluşturmak.
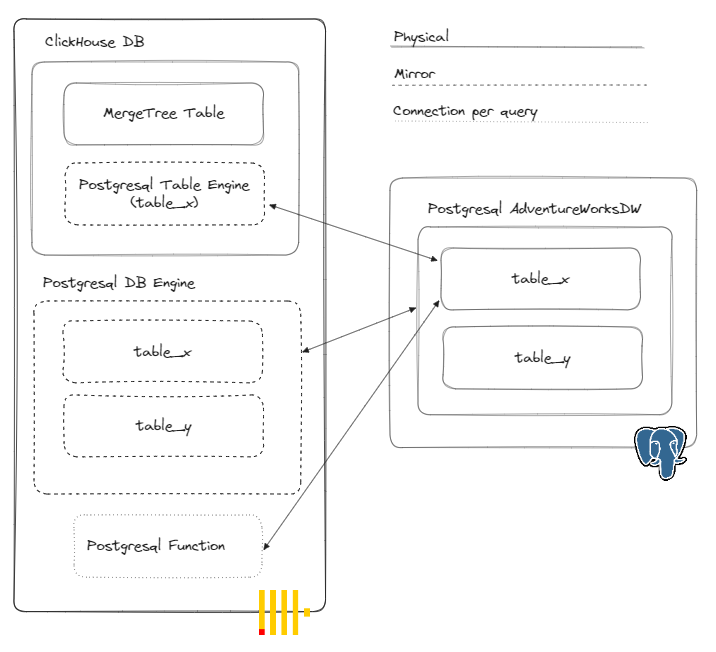
Biz bu çalışmada veri tabanı motorunu kullanacağız.
- ClickHouse konteynerine, ardından istemcisine bağlanalım. Bizi bir gülümseme karşılayacak:)
docker exec -it clickhouse bash -c "clickhouse client --user clickhouse --password Ankara06"
Çıktı:
root@09006fee88e8:/# clickhouse client ClickHouse client version 24.2.2.71 (official build). Connecting to localhost:9000 as user clickhouse. Connected to ClickHouse server version 24.2.2. Warnings: * Linux transparent hugepages are set to "always". Check /sys/kernel/mm/transparent_hugepage/enabled 09006fee88e8 :)
- ClickHouse’da Postgresql bilgilerini vererek veri tabanı bağlantısı oluşturalım.
CREATE DATABASE adv_dw ENGINE = PostgreSQL('postgresql:5432', 'adventureworksdw', 'postgres', 'Ankara06', `public`, 1);Yukarıda parantez içerisinde verdiğimiz parametreler, sırayla:
- Sunucu ve port
- Bağlanacağımız veri tabanı
- Kullanıcı adı
- Şifre
- Veri tabanında bağlanmak istediğimiz şema
- use_table_cache parametresi (1 olarak ayarlanırsa tablo yapısı önbelleğe alınır ve değiştirilip değiştirilmediği kontrol edilmez)
- “adv_dw” veri tabanı oluşmuş mu doğrulayalım.
show databases;
Çıktı:
Query id: 1c3f04d0-907b-4330-a470-a3c3bb3ca1b4 ┌─name───────────────┐ │ INFORMATION_SCHEMA │ │ adv_dw │ │ clickhouse_db │ │ default │ │ information_schema │ │ system │ └────────────────────┘ 6 rows in set. Elapsed: 0.002 sec.
Artık ClickHouse doğrudan Postgresql’de “public” şemasındaki tablolara ulaşabiliyor.
Postgresql ile doğrudan bağlantı yapmak ve buradaki tablolara ClickHouse üzerinden ulaşmak ClickHouse performansını deneyimlemeyi mümkün kılmayacaktır. Burada amacımız, ihtiyaç durumunda Postgresql’e nasıl bağlantı sağlanacağını göstermektir. Postgresql/ClickHouse bağlantısı için yaklaşımlar ve performans değerlendirmeleri için aşağıdaki linkleri de incelemenizi bu noktada önerebilirim.
ClickHouse and PostgreSQL – a match made in data heaven – part 1
ClickHouse and PostgreSQL – a Match Made in Data Heaven – part 2
Not: Aynı terminali kullanmaya devam etmek istiyorsak ctrl + D ile çıkış yapalım veya yeni bir terminal açarak aşağıdaki adımları takip etmeye devam edelim.
4. Superset yapılandırma
Daha önce Superset ile ilgili yazımda bulunan adımları burada da uygulayalım.
- Admin kullanıcısı oluşturalım
docker exec -it superset superset fab create-admin \
--username admin \
--firstname Superset \
--lastname Admin \
--email admin@superset.com \
--password admin- Lokal veri tabanı son sürüme yükseltelim
docker exec -it superset superset db upgrade
- Rolleri oluşturalım
docker exec -it superset superset init
5.Superset ve ClickHouse bağlantısını kurma
Kurulumda Superset için clickhouse sürücüsünü indirmiştik. Bu yüzden aşağıdaki şekilde bağlantıyı kolaylıkla sağlayabiliriz.
- http://localhost:8088/login/ arayüzünden admin/admin ile giriş yapalım
- Veri tabanı bağlantılarının sayfasına ulaşalım (Sağ üst köşede “Settings” menüsünde “Database Connections”)
- Yeni veri tabanı bağlantısı oluşturma penceresine ulaşalım ve ClickHouse’u seçelim (Sağ üst köşede “+ DATABASE” )
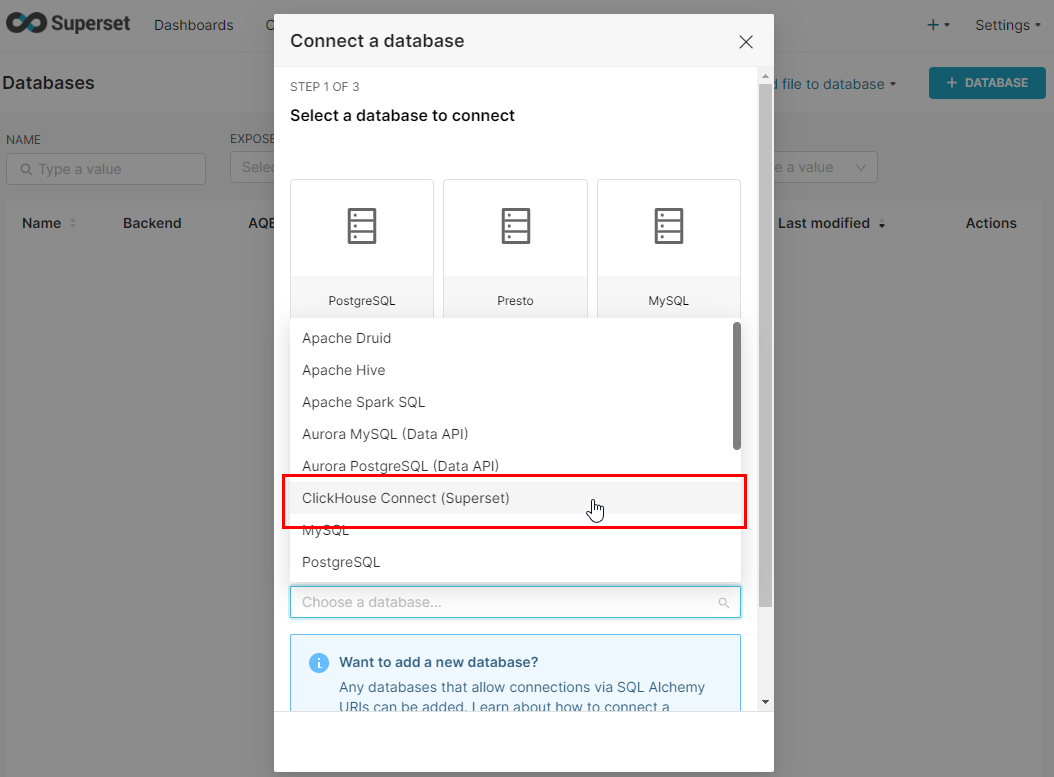
- Bağlantı bilgilerimizi girelim ve bağlantıyı tamamlayalım
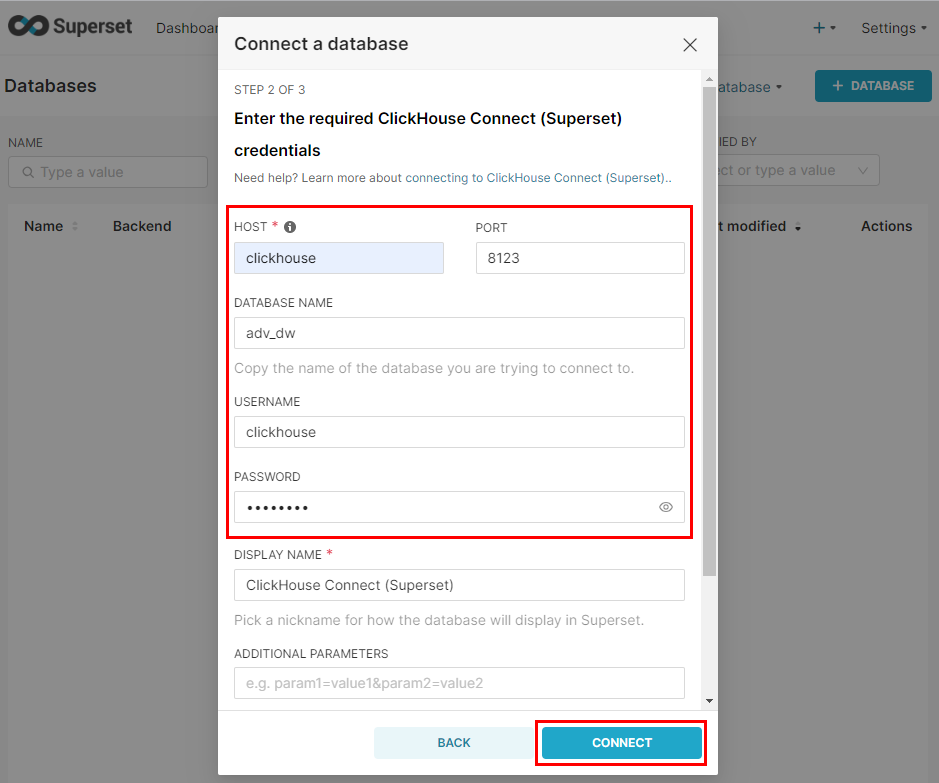
Böylece ClickHouse ve Superset iletişimini de sağlamış olduk. (Superset ile ilgili yazımda SQL Lab, grafik ve panel oluşturma ile ilgili genel bilgilerden de bahsetmiştim)
Bu makalede, ClickHouse’un ne olduğunu, nasıl çalıştığını ve entegrasyona dair bazı örneklerini inceledik. Sütun odaklı mimarisi, yüksek performansı ve ölçeklenebilirliği ile ClickHouse, büyük veri analitiği ve iş zekası uygulamaları için ideal bir çözüm sunmaktadır. ClickHouse’un sunduğu bu avantajları keşfetmek ve veri işleme süreçlerinizi optimize etmek için şimdi ClickHouse’u denemeye ne dersiniz? Hadi, veri dünyasında yeni ufuklara yelken açalım! 🚀
Tekrar görüşmek üzere ✌️
Kaynaklar
https://clickhouse.com/docs/en/intro
Uzun zamandır araştırma yapıpda en net bulduğum içerik.
Teşekkürler.