
Merhaba VBO okuyucuları! Bir önceki...


Merhaba Arkadaşlar,Özellik seçimi ile ilgili...

Herkese merhabalar, Bu yazımda, "Riske...

Catboost, Yandex şirketi tarafından geliştirilmiş...

Makine öğrenmesinde özellik seçimi yöntemleri...

Makine Öğrenmesi dünyasının “Merhaba Dünya”...
Herkese merhabalar. Serimizin 3. bölümüne...

Pytorch C++ kütüphanesi kullanarak konvolüsyonel...
Merhaba, size bu yazımda...

Bir Veri Bilimi projesinde en...

LightGBM diğer boosting algoritmaları ile...

Merhaba VBO okuyucuları, Bir önceki...

https://www.kaggle.com/c/titanic No Free Lunch Teoremi...
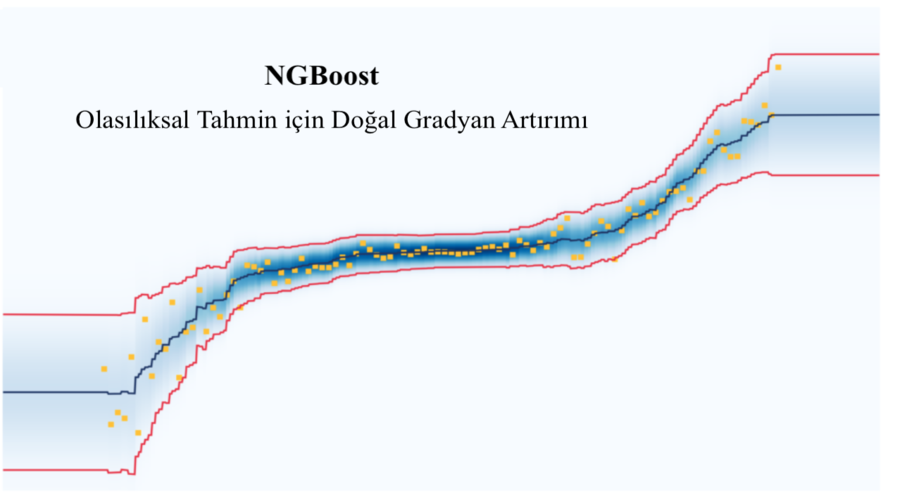
Bu yazımda, son zamanlarda araştırmak...

Corona günlerinden herkese merhaba,Bu yazımda,...

Herkese merhabalar. Yapay Zeka Uygulama...

Yapay zeka, son dönemlerde hem...

2019 yılında, ilk kez Çin’in...

“Sosyal medya platformlarında neler yapabilirim?”...

Local Outlier Factor(LOF) bir noktanın...