

![]()
Bu yazımızda Big Data Analytics dergisinde 2016 yılında Garcia vd. (2016) tarafından yazılan “Big data preprocessing:methods and prospects“ isimli makale inceleme notlarımı sizlerle paylaşacağım. Makale özeti sayılmaz, birebir çeviri de değil, her şey yazarlara ait değil, içinde benden de bir şeyler var. Ortaya karışık bir şey işte, idare edin 🙂 Bazı kelimelerin Türkçe karşılığı dilimizde oturmuş, bazılarını bulamadım ve ben çevirmeye kalktım. Tam emin olmadıklarımın yanlarına orijinal İngilizce karşılıklarını da yazdım.
1. Giriş
Makale temel olarak büyük veri madenciliği, veri ön işleme safhası hakkında bizi bilgilendirmeyi amaçlıyor. Bildiğimiz gibi Cross Industry Standard Process for Data Mining (CRISP-DM) adında veri madenciliği süreci ve safhaları için bir standart oluşturulmuş. Data preparation safhası veri ön hazırlığının yapıldığı safhadır. Büyük veri üzerinde veri madenciliğinde de böyle bir safha olmak durumunda. İşte bu makale bu safhanın büyük veride ne alemde olduğuna dair genel bir bakış (review) makalesi. Büyük verideki veri ön işleme yaklaşımlarının tanımı, özellikleri ve sınıflandırılmasına değinilmiş.

MapReduce büyük veride genel bir popülerliğe sahip olsa da veri madenciliğinde sıkça kullanılan iterasyon (ara sonuçları kullanarak veriyi tekrar tekrar okuma) ve çevrimiçi işleme konusunda yetersiz kalmaktadır. Apache Spark, MapReduce’un bu eksilerini giderek büyük veri dünyasına parlak bir giriş yaptı. Spark, genel amaçlı bir motordur. Ancak Spark’ın bu genel amaçlılık yaklaşımının eksik kaldığı bazı noktalar, başka projelerin doğmasına yol açmıştır. Örneğin Apache Storm; Storm gerçek zamanlı dağıtık işleme platformudur. Benzer şekilde Apache Flink de stream ve batch-processing konusunda Spark’ın açık bıraktığı noktaları dolduruyor.
Bilindiği üzere kaliteli bilgi, kaliteli bir veriyle elde edilir ancak. Bu sebeple genelde önemsenmeyen veri hazırlığı/ön işleme, aslında veri madenciliğinin en önemli aşamasıdır. Çünkü bozuk veri ile istediğiniz kadar mükemmel görünen modeller kurun, sağlıklı bir sonuç alamazsınız. Kaliteli ve düzgün veri; sadece sonuçların yüksek doğruluğunu değil, veri madenciliği algoritmalarının performansını da olumlu etkiler. Veri hazırlığını tarihi eser restore eder gibi titizlikle yapmak lazım. Bazen verilerin biz pazarcıların eline düşmüş zavallı altınlar gibi olduğunu düşünüyorum. Tarihi eserde yanlış restorasyon sırıtıyor ama veri, ne de olsa veri, hepsi 1-0, çok gafa yormaya gerek yoh nasolsa 🙂
2. Veri Ön İşleme (Data preprocessing)
Veri ön işleme; veri madenciliği modelleri kurulmadan önce veri seti üzerinde yapılan bir takım düzeltme, eksik veriyi tamamlama, tekrarlanan verileri kaldırma, dönüştürme, bütünleştirme, temizleme, normalleştirme, boyut indirgeme vb. işlemlerdir. Bu aşamada ister istemez veri üzerinde bilgi keşfi yapılmış olur. Bir önceki aşamayı adamlar boşu boşuna veri ön işlemenin önüne koymamışlar. Veri anlama aşamasında zaten veride ne düzeltmeler yapılacağı konusunda gafada bir ışık yanmış olması lazım.
Veri ön işleme çok zaman alan bir aşamadır. Literatürde bir kaç yerde %80 rakamlarını gördüm. Hakkıyla bir ön işleme yapıldığında gerçekten veri madenciliği sürecinin %80’ini kaplayacağına inanıyorum. Yazarların bazı veri ön işleme görevleri ile ilgili çizimleri aşağıdadır.
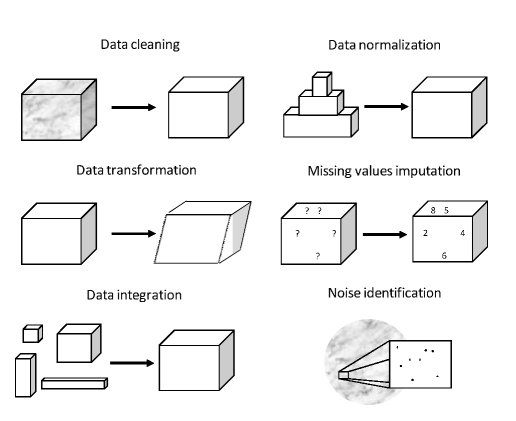
2.1. Bozuk Veri
Bir çok veri madenciliği algoritması girdi olarak temiz, kaliteli ve gürültüsüz veri aldığı varsayımına dayanarak çalışır. Oysaki gerçekte böyle bir veri yoktur. Yani oluştuğu esnada mükemmel olan ve hiç ön işleme gerektirmeyen anlamında yoktur.
2.1.1. Kayıp Verileri Tamamlama (Missing value imputation)
Kayıp veri, veri madencilerinin kaçışı olmayan kabusu gibidir. Hemen hemen her veri setinde karşılarına çıkar. Çünkü veri tabiatı itibariyle kötüdür (dirty in nature). Kayıp veriyle uğraşırken dikkatli olmak lazım, yanlış bir hareket felaketle sonuçlanabilir. Eksik verilerin bulunduğu satırları çıkarmak bir yöntem olmakla beraber bazı mahsurları vardır. Veriyi bozabilir, değerli verilerin kaybolmasına sebep olabilir, hele kayıp veriler özellikle bir örüntüye sahip ise ciddi sapmalar (bias) oluşturabilir. Kayıp verileri tamamlamak için istatistiksel yöntemleri veya makine öğrenmesi yöntemleri kullanılması çıkarmaktan daha sağlıklıdır. Ancak yazarlar burada kestirip atmış, bence daha uzun durabilirlermiş. Herhangi yenilikçi (novel) bir önerme bulamadım ben burada zaten bilinen şeyler bunlar. Neyse devam edelim okumaya.
2.1.2. Gürültülü Veriyle Uğraşma (Noisy data)
Veri doğası icabı kötüdür dedik. Bazı veri madenciliği teknikleri verinin dağılımı konusunda varsayımları vardır. Örneğin regresyon normal dağılım ister. Aksi halde tip-1 hata olasılığı artar. Gürültülü veriyle uğraşma konusunda iki ana yaklaşım vardır. İlki bozuk veriyi düzeltme yöntemleri (data polishing methods). İkinci yaklaşım ise gürültülü veriyi filtrelemek ve eğitim verisi olarak kullanmamak.
2.2. Boyut İndirgeme (Dimentionality reduction)
Bağımsız değişken sayısı çok fazla olduğu durumlarda bağımlı değişkene olan etkiler çok zayıflar ve kurulan modellerin yorumlanabilirliği ve gerçek hayata uygulanabilirliği azalır. Bağımsız değişkenin çokluğuna genelde curse of dimentionality deniyor. Yani Türkçesi çok boyutluluğun laneti. Çok boyutluluk ayrıca hesaplama konusunda da ilave yük getiriyor.
2.2.1. Özellik Seçimi (Feature Selection)
Özellik seçimi, problemi çözmek için gereksiz ve problemin çözümüne etkisi olmayan özellikleri tespit ederek bunları kullanmamaktır. Gereksiz özellikler gereksiz korelasyonlar oluşturur ve modelin genellenebilirliğini zayıflatır. Özellik seçimi ayrıca aşırı öğrenme (overfitting) olasılığını da azaltır, model eğitiminde gereksiz kaynak tüketiminin özellikle ana bellek (bilgisayar rami), önüne geçer. Daha az özellik, daha anlaşılır ve yorumlanır modellerin oluşturulmasını sağlar demiş ve kapatmış konuyu.
2.2.2. Space Transformations
Boyut indirgemenin özellik seçiminden başka yöntemleri de var elbette, örneğin faktör analizi ve ana bileşenler analizi (principal component analysis). Bu ikisi doğrusal yöntemler. Bir de doğrusal olmayanlar var: .LLE ve ISOMAP.
2.2.3. Instance Reduction (IR)
Büyük veri setlerinin veri madenciliği algoritmaları üzerindeki olumsuz etkisini azaltmanın popüler yöntemlerinden birisi IR. Veri boyutunu küçült ama ondan çıkarılacak bilgi kalitesini düşürme felsefesine dayanır.
2.2.4. Instance Selection (IS)
Örneklem seçmek gibi birşey. Klasik usülde evrendeki nesnelerin hepsine ulaşıp veri toplayamadığımız için evreni temsil edebilecek bir örneklem seçiyorduk. Ancak burada evrendeki tüm nesnelere ait veri zaten elimizde. Fazla mal göz çıkardığından hepsini değil de hepsini temsil edecek bir örneklem seçiliyor. Yalnız buradaki fark olay tamamen tesadüfi gelişmiyor, temizleme işlemleri de yapılıyor ve algoritmanın verinin önemli kısımlarına odaklanması sağlanıyor.
2.2.5. Instance Generation (IG)
Instance generation bir bakıma instance selection tersi gibi. Burada da yapay bir veri üretimi var. Ama nerede ve niçin? Eksik yerler, bir alanda temsilcinin olmadığı veya yetersiz olduğu yerler. Yanlış etiketlenmiş verilerin düzeltilmesi bir örnek olarak verilebilir.
2.2.6. Discretization
Veriyi kesikli hale getirme olayı. Örneğin karar ağaçları sürekli değişken kullanmaz. Bu sebeple sürekli değişkenler karar ağacı için kesikli hale getirilir. En çok kullanılan veri ön işleme tekniği. Örneğin yaş değişkeninin çocuk, ergen, genç, orta yaş, yaşlı yapılması. Karar ağaçları gibi bir çok algoritma kesikli değişken istiyor mesela C4.5, Naive Bayes, Apriori. Kesikleştirme veriyi basitleştirme, daha anlaşılır kılma, hızlı ve yüksek doğrulukla öğrenmeyi gibi faydaları var üstelik verinin okunurluğunu artırıyor. Ancak bazı maliyetler var: bilgi kaybı.
2.3. Dengesiz (Imbalanced) Öğrenme. Örneklem Azaltma (Undersampling) ve Örneklem Artırma (Oversampling) Yöntemleri
Bir çok denetimli öğrenme uygulamasında sınıflar arası öncül olasılıklar (prior probabilities) çok farklı ve dengesiz olabiliyor. Buradaki sıkıntı şu dengesiz sınıflar öğrenmede çoğunluğu oluşturan sınıf lehine bir sapma (bias) oluşturur. Bu sebeple seyrek sınıf için isabetsiz tahminler artar. Her ne kadar algoritmik olarak dengesiz sınıflara çare mümkünse de burada konumuz veri ön işleme olduğu için bu sorunu veri ön işleme teknikleriyle nasıl çözeriz onu tartışıyor olacağız. Veri ön işlemede dengesizliğin önüne geçmek için denge oluşana kadar yeniden örneklem alma yapılır. Bunun algoritmik düzenlemeye göre avantajı veri madenciliği algoritmasından bağımsız olmasıdır. Örneklem azaltmada baskın sınıftan kırpılarak örneklem alınır, örneklem artırma da zayıf sınıfa ilaveler yapılır. Bunlar gibi sezgisel olmayan (non-heuristic) teknikler veriden elde edilecek bilgiyi battal edebilir ya da aşırı öğrenme ihtimalini yükseltebilir. Sezgisel (heuristic) yaklaşımlardan Synthetic Minority Oversampling TEchnique (SMOTE) bu alanda en meşhurudur.
2.4. Veri Madenciliğinin Yeni Alanlarında Veri Ön İşleme
Veri ön işleme genelde denetimli öğrenme için yapılıyor ancak denetimsiz öğrenmenin boynu bükük değil. Onun için de bazı yaklaşımlar var. Feature Selection (FS) ve kayıp veri tamamlama bunlardan en popüleri. Hedef değişkenin kiden fazla etikete sahip olan sınıflandırmalar (multi-label classification) sınıf dengesizliğine çok meyillidir. Bu sebeple tekrar örneklem tekniği önerilir. Akan veri (data stream) de veri madenciliğinde zor konulardan biri, çünkü bilgi zaman içinde değişiveriyor.Akan veri için de kayıp veri tamamlama, özellik seçimi ve instance reduction öneriliyor.
3. Büyük Veri Ön İşleme (Big Data Preprocessing)
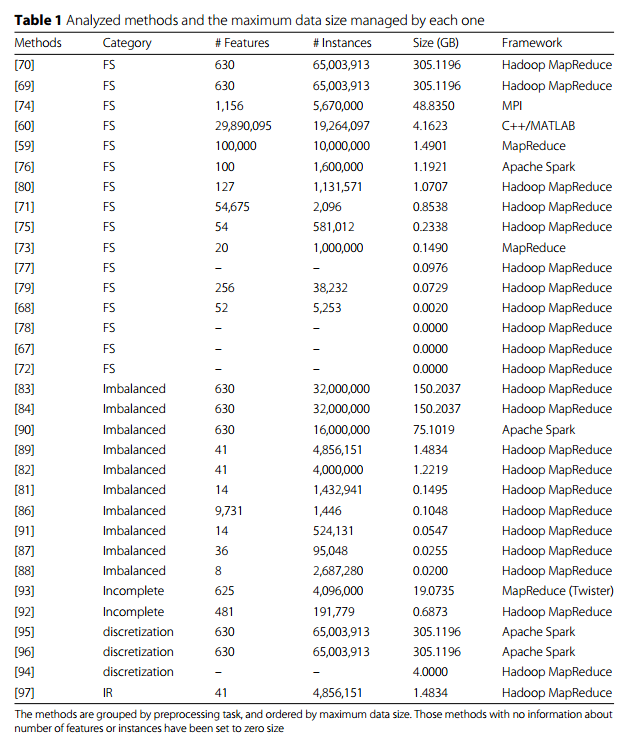
Bu bölümde büyük veri ön işleme konusunda literatürde katkıda bulunan çalışmalara özetle yer verilecektir. Aşağıdaki tablo çalışmaları özetliyor.
3.1. Spark MLlib: Machine Learning Library
Spark MLlib kütüphanesi Spark topluluğunun kullandığı makine öğrenmesi kütüphanesiydi ve RDD üzerine kuruluydu. Ancak Spark yönünü Dataframe’e kırmaya başlayınca yeni kütüphane bunun için yazıldı ve buna da ml dendi ve daha yeni özellikleri barındırıyor.
3.1.1. Kesikleştirme ve Normalleştirme (Discretization ve Normalization)
Kesikleştirme sürekli değişkenin kesikli aralıklara dönüştürülmesidir. Normalleştirme ise dağılımda yapılan tadilattır. Çeşitleri; binarizer, bucketizer, discrete cousine transform, normalizer, standart scaler, min max scaler, elementwise product.
3.1.2. Nitelik Çıkarımı (Feature Extraction)
Nitelik çıkarımı orijinal nitelikleri karıştırarak yeni ancak gereksiz olmayan değişkenler elde edilmesini sağlar. Polynomial Expansion, Vector Assembler, Single Value Decomposition, Principal Component Analysis.
3.1.3. Nitelik Seçimi (Feature Selection)
Fazla bilgi kaybına meydan vermeden niteliklerin ilgili alt kümesini seçmeye çalışır. VectorSlicer, RFormula, Chi-Squared selector. Nitelik seçimi ile ilgili yapılan 16 çalışma birer cümle halinde özetlenmiş.
3.1.4. Özellik İndeksleyici ve Kodlayıcı (Feature Indexers and Encoders)
İndeks ve kodlama kullanarak bir niteliği bir türden diğerine dönüştürme. StringIndexer, OneHotEncoder, VectorIndexer.
3.1.5. Metin Madenciliği için Diğer Ön İşleme Yöntemleri
Metin madenciliğindeki ön işleme çalışmaları daha yapısal örüntüler ortaya çıkarmaya çabalar. TF-IDF, Word2Vec, CountVectorizer, Tokenizer, StopWordsRemover, n-gram.
3.2. Büyük Veri İçin Yapılan Diğer Katkılar
3.2.1. Özellik Seçimi
3.2.2. Dengesiz Veri (Imbalanced Data)
Dengesiz veride sınıfların dengesiz dağıldığını ve bunun da çoğunluk sınıftan yana sapmaya yol açtığını bunu düzeltmek gerektiğini söylemiştik. Bu konuda büyük veri aleminde özellikle MapReduce mantığında yapılan 8 çalışma birer cümleyle özetlenmiş.
3.2.3. Eksik Veri (Incomplete Data)
İster insan, ister makine hatası sonucu olsun gerçek hayatta kayıp ve eksik veri sık sık karşılaşılan bir durumdur. Üstelik ilişkisel veri tabanları gibi çok katı kurallarla işlemeyen büyük veri dünyası tabiatı gereği eksik ve kayıp veriye daha müsaittir. Diğer veri ön işleme tekniklerine göre büyük veride bu konuda yapılan çalışma azdır [92-93].
3.2.4. Kesikleştirme (Discretization)
Sık sık sınıflandırıcının (machine) performans ve etkinliğini artırmak için kullanılır. Bilgi keşfi sürecinde (discovery knowledge process) önemli yeri vardır. Ancak standart kesikleştirme yöntemleri büyük veri aleminde geçer akçe değildir. Bu alanla ilgili çalışmalar [94-95].
3.2.5. Instance Reduction (IR)
Instance reduction örneklem sayısını azaltmaya yöneliktir. Küçük ve orta ölçekli verilerde kendini kanıtlamış olsa da büyük veri aleminde işe çok yaramaz. Bununla ilgili tek çalışma [97]. Bu çalışmada ileri düzey IR kullanılmış ve adına SSMA-SFLSDE denilmiş. [97]’yi genişleten başka bir çalışma [98]
Bu bölümde geniş ölçekli veride ön işleme konusuna literatürde yapılmış çalışmalara değindik. Spark MLlib ön işleme için çok geniş yelpazede araçlar öneriyor ancak bunların hemen hemen hepsi oldukça basit.
4. Büyük Veri Ön İşlemede Zorluklar ve Yeni Olasılıklar
Yeni olasılıkların önümüzdeki yıllarda şu üç konu altında olmasını bekliyoruz: yeni teknolojiler, mevcut ön işleme tekniklerinin büyük ölçeğe uyarlanması, yeni büyük veri öğrenme paradigmaları.
4.1. Yeni Teknolojiler
Veri ön işleme konusunda Spark, Hadoop’tan daha iyi performans gösteriyor demiş. Ben bu cümleyi düzeltmek istiyorum. Spark Hadoop’un rakibi değil MapReduce’un rakibidir. MapReduce Hadoop olmayıp onun temel bileşenlerinden biridir, dağıtık veri işlemeye uygun bir programla paradigmasıdır. Ancak Spark MepReduce’a göre daha genç olduğu için ön işleme konusunda daha alacak çok yolu var. Bu nedenle MLlib kütphensinin eri ön işleme konusunda daha da zenginleşmesini bekliyoruz. Ben de. Flink de akan veri ve batch prosessing konusunda Spark’ın arkasından sağlam bir şekilde geliyor ancak veri ön işleme kütüphanesi Spark kadar zengin değil.
4.2 Mevcut Tekniklerin Büyük Veri için Uyarlanması
Şimdiye kadarki gayretlerin çoğu özellik seçimi (FS) konusunda görünüyor ancak diğer ön işleme teknikleri konusunda kayda değer bir çalışma görünmüyor. Mesela instance reduction, kayıp veri tamamlama, gürültülü veriyle uğraşma. Veride optimum bir iyileştirme yapmak için bir kaç tekniğin bir düzenleme ve kombinasyonu konusunda bir boşluk var. Bu durum [99]’da tartışılmış. Bir tekniğin uygulanmasına göre karma yaklaşım daha karmaşık ancak büyük veriyle birlikte bu yaklaşımla başa çıkmak gerekecek görünüyor.
4.3. Yeni Büyük Veri Öğrenme Paradigmaları
Veri madenciliği dinamik bir alan yeni problemler ortaya çıkıyor, haliyle veri ön işleme teknikleri de yeni zorluklarla karşılaşıyor. Bu zorlukların çoğunluğu büyük veri dünyasından kaynaklanıyor[100].
5. Sonuç
Büyük verinin veriyi işleme ve saklama tarzı veri tabanlarında bilgi keşfini etkiledi. Gelecekte endüstri ve akademik camia tarafından ortaya çıkacak önemli zorluklar ele alınmak durumda kalınacak. Çünkü büyük veri teknolojileri bir yandan olgunlaşırken diğer yandan yeni ihtiyaçlar için yeni teknolojiler ortaya atılıyor.
6. Benim Genel Değerlendirmem
Bu alandaki kaynakları bir araya toplamış bir çalışma. Kaynakçanın kısa açıklamaları yazılmış ve tasnif edilmiş hali gibi adeta. Zaten çalışmanın amacı da mevcut hale ve yapılan diğer çalışmalara bir göz atmak.
7. Kaynakça
Yazarlar: García, S., Ramírez-Gallego, S., Luengo, J., Benítez, J. M., & Herrera, F. (2016). Big data preprocessing: methods and prospects. Big Data Analytics, 1(1), 9.
Kapak Resmi :http://www.ascentitgroup.com/data-processing/
1. Aggarwal CC. Data Mining: The Textbook. Berlin, Germany: Springer; 2015.1. Aggarwal CC. Data Mining: The Textbook. Berlin, Germany: Springer; 2015.
2. Wu X, Zhu X, Wu GQ, Ding W. Data mining with big data. IEEE Trans Knowl Data Eng. 2014;26(1):97–107.
3. Laney D. 3D Data Management: Controlling Data Volume, Velocity and Variety. 2001. http://blogs.gartner.com/doug-laney/files/2012/01/ad949-3D-Data-Management-Controlling-Data-Volume-Velocity-and-Variety.pdf.Accessed July 2015.
4. Fernández A, del Río S, López V, Bawakid A, del Jesús MJ, Benítez JM, et al. Big data with cloud computing: aninsight on the computing environment, mapreduce, and programming frameworks. Wiley Interdisc Rew Data MinKnowl Discov. 2014;4(5):380–409.
5. Dean J, Ghemawat S. Mapreduce: Simplified data processing on large clusters. In: OSDI 2004. San Francisco, CA;2004. p. 137–50.
6. White T. Hadoop, The Definitive Guide. Sebastopol: O’Reilly Media, Inc; 2012.
7. Apache Hadoop Project. Apache Hadoop. 2015. http://hadoop.apache.org/. Accessed December 2015.
8. Lin J. Mapreduce is good enough? if all you have is a hammer, throw away everything that’s not a nail! Big Data.2012;1(1):28–37.
9. Karau H, Konwinski A, Wendell P, Zaharia M. Learning Spark: Lightning-Fast Big Data Analytics. Sebastopol: O’ReillyMedia; 2015.
10. Spark A. Apache Spark: Lightning-fast cluster computing. https://spark.apache.org/. Accessed December 2015.
11. Zaharia M, Chowdhury M, Das T, Dave A, Ma J, McCauley M, et al. Resilient distributed datasets: A fault-tolerantabstraction for in-memory cluster computing. In: Proceedings of the 9th USENIX Conference on NetworkedSystems Design and Implementation. NSDI’12. San Jose; 2012. p. 15–28.
12. InfoWorld. Apache Flink: New Hadoop contender squares off against Spark. 2015. http://www.infoworld.com/article/2919602/hadoop/flink-hadoops-new-contender-for-mapreduce-spark.html. Accessed December 2015.
13. Storm. Apache Storm. 2015. http://storm-project.net/. Accessed December 2015.
14. Flink. Apache Flink. 2015. https://flink.apache.org/. Accessed December 2015.
15. Pyle D. Data Preparation for Data Mining. San Francisco: Morgan Kaufmann Publishers Inc.; 1999.
16. García S, Luengo J, Herrera F. Data Preprocessing in Data Mining. Berlin: Springer; 2015.
17. Han J, Kamber M, Pei J. Data Mining: Concepts and Techniques, 3rd ed. Burlington: Morgan Kaufmann PublishersInc; 2011.
18. Zaki MJ, Meira W. Data Mining and Analysis: Fundamental Concepts and Algorithms. New York: CambridgeUniversity Press; 2014.
19. Wang H, Wang S. Mining incomplete survey data through classification. Knowl Inf Syst. 2010;24(2):221–33.
20. Luengo J, García S, Herrera F. On the choice of the best imputation methods for missing values considering threegroups of classification methods. Knowl Inf Syst. 2012;32(1):77–108.
21. Little RJA, Rubin DB. Statistical Analysis with Missing Data. Wiley Series in Probability and Statistics, 1st ed.New York: Wiley; 1987.
22. Frénay B, Verleysen M. Classification in the presence of label noise: A survey. IEEE Trans Neural Netw Learn Syst.2014;25(5):845–69.
23. Zhu X, Wu X. Class Noise vs. Attribute Noise: A Quantitative Study. Artif Intell Rev. 2004;22:177–210.
24. Bellman RE. Adaptive Control Processes – A Guided Tour. Princeton, NJ: Princeton University Press; 1961.
25. Hall MA. Correlation-based feature selection for machine learning. Waikato University, Department of ComputerScience. 1999.
26. Guyon I, Elisseeff A. An introduction to variable and feature selection. J Mach Learn Res. 2003;3:1157–82.
27. Chandrashekar G, Sahin F. A survey on feature selection methods. Comput Electr Eng. 2014;40(1):16–28.
28. Kim JO, Mueller CW. Factor Analysis: Statistical Methods and Practical Issues (Quantitative Applications in the SocialSciences). New York: Sage Publications, Inc; 1978.
29. Dunteman GH. Principal Components Analysis. A Sage Publications. Thousand Oaks: SAGE Publications; 1989.
30. Roweis S, Saul L. Nonlinear dimensionality reduction by locally linear embedding. Science. 2000;290(5500):2323–326.
31. Tenenbaum JB, Silva V, Langford JC. A global geometric framework for nonlinear dimensionality reduction.Science. 2000;290(5500):2319–323.
32. Liu H, Motoda H. On issues of instance selection. Data Min Knowl Disc. 2002;6(2):115–30.
33. Olvera-López JA, Carrasco-Ochoa JA, Martínez-Trinidad JF, Kittler J. A review of instance selection methods. ArtifIntell Rev. 2010;34(2):133–43.
34. García S, Derrac J, Cano JR, Herrera F. Prototype selection for nearest neighbor classification: Taxonomy andempirical study. IEEE Trans Pattern Anal Mach Intell. 2012;34(3):417–35.
35. Triguero I, Derrac J, García S, Herrera F. A taxonomy and experimental study on prototype generation for nearestneighbor classification. IEEE Trans Syst Man Cybern Part C. 2012;42(1):86–100.
36. Liu H, Hussain F, Tan CL, Dash M. Discretization: An enabling technique. Data Min Knowl Discov. 2002;6(4):393–423.
37. Wu X, Kumar V, (eds). The Top Ten Algorithms in Data Mining. Boca Ratón, Florida: CRC Press; 2009.
38. Quinlan JR. C4.5: Programs for Machine Learning. San Francisco, CA: Morgan Kaufmann Publishers Inc.; 1993.
39. Agrawal R, Srikant R. Fast algorithms for mining association rules. In: Proceedings of the 20th Very Large Data BasesConference (VLDB); 1994. p. 487–99.
40. Yang Y, Webb GI. Discretization for naive-bayes learning: managing discretization bias and variance. Mach Learn.2009;74(1):39–74.
41. Yang Y, Webb GI, Wu X. Discretization methods. In: Data Mining and Knowledge Discovery Handbook. Germany:Springer; 2010. p. 101–16.
42. García S, Luengo J, Sáez JA, López V, Herrera F. A Survey of Discretization Techniques: Taxonomy and EmpiricalAnalysis in Supervised Learning. IEEE Trans Knowl Data Eng. 2013;25(4):734–50.
43. López V, Fernández A, García S, Palade V, Herrera F. An insight into classification with imbalanced data: Empiricalresults and current trends on using data intrinsic characteristics. Inf Sci. 2013;250:113–41.
44. Chawla NV, Bowyer KW, Hall LO, Kegelmeyer WP. SMOTE: synthetic minority over-sampling technique. J Artif IntellRes. 2002;16(1):321–57.
45. Li Z, Tang J. Unsupervised feature selection via nonnegative spectral analysis and redundancy control. IEEE TransImage Process. 2015;24(12):5343–355.
46. Han J, Sun Z, Hao H. Selecting feature subset with sparsity and low redundancy for unsupervised learning.Knowl-Based Syst. 2015;86:210–23.
47. Wang S, Pedrycz W, Zhu Q, Zhu W. Unsupervised feature selection via maximum projection and minimumredundancy. Knowl-Based Syst. 2015;75:19–29.
48. Ishioka T. Imputation of missing values for unsupervised data using the proximity in random forests. In:Nternational Conference on Mobile, Hybrid, and On-line Learning. Nice; 2013. p. 30–6.
49. Bondu A, Boullé M, Lemaire V. A non-parametric semi-supervised discretization method. Knowl Inf Syst.2010;24(1):35–57.
50. Impedovo S, Barbuzzi D. Instance selection for semi-supervised learning in multi-expert systems: A comparativeanalysis. Neurocomputing. 2015;5:61–70.
51. Williams D, Liao X, Xue Y, Carin L, Krishnapuram B. On classification with incomplete data. IEEE Trans Pattern AnalMach Intell. 2007;29(3):427–36.
52. Charte F, Rivera AJ, del Jesus MJ, Herrera F. MLSMOTE: Approaching imbalanced multilabel learning throughsynthetic instance generation. Knowl-Based Syst. 2015;89:385–97.
53. Charte F, Rivera AJ, del Jesús MJ, Herrera F. Addressing imbalance in multilabel classification: Measures andrandom resampling algorithms. Neurocomputing. 2015;163:3–16.
54. Xiaoguang W, Xuan L, Nathalie J, Stan M. Resampling and cost-sensitive methods for imbalanced multi-instancelearning. In: 13th IEEE International Conference on Data Mining Workshops, ICDM Workshops, TX, USA,December 7-10, 2013. USA: IEEE; 2013. p. 808–16.
55. Jiang N, Gruenwald L. Estimating missing data in data streams. In: 12th International Conference on DatabaseSystems for Advanced Applications, DASFAA 2007; Bangkok; Thailand; 9 April 2007 Through 12 April 2007.Bangkok; 2007.p. 981–7.
56. Zhang P, Zhu X, Tan J, Guo L. SKIF: a data imputation framework for concept drifting data streams In: Huang J,Koudas N, Jones GJF, Wu X, Collins-Thompson K, An A, editors. CIKM. Toronto; 2010. p. 1869–1872.
57. Kogan J. Feature selection over distributed data streams through convex optimization. In: Proceedings of the 2012SIAM International Conference on Data Mining. Anaheim; 2012. p. 475–84.
58. Lu N, Lu J, Zhang G, de Mántaras RL. A concept drift-tolerant case-base editing technique. Artif Intell. 2016;230:108–33.
59. Singh S, Kubica J, Larsen SE, Sorokina D. Parallel large scale feature selection for logistic regression. In: SIAMInternational Conference on Data Mining (SDM). Sparks, Nevada; 2009. p. 1172–1183.
60. Tan M, Tsang IW, Wang L. Towards ultrahigh dimensional feature selection for big data. J Mach Learn Res. 2014;15:1371–1429.
61. Meng X, Bradley JK, Yavuz B, Sparks ER, Venkataraman S, Liu D, Freeman J, Tsai DB, Amde M, Owen S, Xin D,Xin R, Franklin MJ, Zadeh R, Zaharia M, Talwalkar A. MLlib: Machine learning in apache spark. CoRR. J MachineLearning Res. 2015;17(2016):1–7. abs/1505.06807.
62. Armbrust M, Xin RS, Lian C, Huai Y, Liu D, Bradley JK, Meng X, Kaftan T, Franklin MJ, Ghodsi A, Zaharia M. SparkSQL: Relational data processing in spark. In: ACM SIGMOD International Conference on Management of Data.SIGMOD ’15. Melbourne; 2015. p. 1383–1394.
63. Guyon I, Gunn S, Nikravesh M, Zadeh LA. Feature Extraction: Foundations and Applications (Studies in Fuzzinessand Soft Computing). Germany: Springer; 2006.
64. Blum AL, Langley P. Selection of relevant features and examples in machine learning. Artif Intell. 1997;97(1-2):245–71.
65. Zhai Y, Ong Y, Tsang IW. The emerging “big dimensionality”. IEEE Comput Intell Mag. 2014;9(3):14–26.
66. Bolón-Canedo V, Sánchez-Marono N, Alonso-Betanzos A. Recent advances and emerging challenges of featureselection in the context of big data. Knowl-Based Syst. 2015;86:33–45.
67. Meena MJ, Chandran KR, Karthik A, Samuel AV. An enhanced ACO algorithm to select features for textcategorization and its parallelization. Expert Syst Appl. 2012;39(5):5861–871.
68. Tanupabrungsun S, Achalakul T. Feature reduction for anomaly detection in manufacturing with mapreduceGA/kNN. In: 19th IEEE International Conference on Parallel and Distributed Systems (ICPADS). Seoul; 2013. p.639–44.
69. Triguero I, del Río S, López V, Bacardit J, Benítez JM, Herrera F. ROSEFW-RF: The winner algorithm for the ECBDL’14big data competition: An extremely imbalanced big data bioinformatics problem. Knowl-Based Syst. 2015;87:69–79.
70. Peralta D, Río S, Ramírez S, Triguero I, Benítez JM, Herrera F. Evolutionary feature selection for big dataclassification: A mapreduce approach. Math Probl Eng. 2015. Article ID 246139.
71. Kumar M, Rath SK. Classification of microarray using mapreduce based proximal support vector machine classifier.Knowl-Based Syst. 2015;89:584–602.
72. Hodge VJ, O’Keefe S, Austin J. Hadoop neural network for parallel and distributed feature selection. Neural Netw.2016. doi:10.1016/j.neunet.2015.08.011.
73. Chen K, Wan W-q, Li Y. Differentially private feature selection under mapreduce framework. J China Univ PostsTelecommun. 2013;20(5):85–103.
74. Zhao Z, Zhang R, Cox J, Duling D, Sarle W. Massively parallel feature selection: an approach based on variancepreservation. Mach Learn. 2013;92(1):195–220.
75. Sun Z, Li Z. Data intensive parallel feature selection method study. In: International Joint Conference on NeuralNetworks (IJCNN). USA: IEEE; 2014. p. 2256–262.
76. Ordozgoiti B, Gómez-Canaval S, Mozo A. Massively parallel unsupervised feature selection on spark. In: NewTrends in Databases and Information Systems. Communications in Computer and Information Science. Germany:Springer; 2015. p. 186–96.
77. Chao P, Bin W, Chao D. Design and implementation of parallel term contribution algorithm based on mapreducemodel. In: 7th Open Cirrus Summit. USA: IEEE; 2012. p. 43–7.
78. Dalavi M, Cheke S. Hadoop mapreduce implementation of a novel scheme for term weighting in textcategorization. In: International Conference on Control, Instrumentation, Communication and ComputationalTechnologies (ICCICCT). USA: IEEE; 2014. p. 994–9.
79. He Q, Cheng X, Zhuang F, Shi Z. Parallel feature selection using positive approximation based on mapreduce. In:11th International Conference on Fuzzy Systems and Knowledge Discovery FSKD. USA: IEEE; 2014.p. 397–402.
80. Wang J, Zhao P, Hoi SCH, Jin R. Online feature selection and its applications. IEEE Trans Knowl Data Eng.2014;26(3):698–710.
81. Park SH, Ha YG. Large imbalance data classification based on mapreduce for traffic accident prediction. In: 8thInternational Conference on Innovative Mobile and Internet Services in Ubiquitous Computing (IMIS). Birmingham;2014. p. 45–9.
82. Hu F, Li H, Lou H, Dai J. A parallel oversampling algorithm based on NRSBoundary-SMOTE. J Inf Comput Sci.2014;11(13):4655–665.
83. del Río S, López V, Benítez JM, Herrera F. On the use of mapreduce for imbalanced big data using random forest.Inf Sci. 2014;285:112–37.
84. del Río S, Benítez JM, Herrera F. Analysis of data preprocessing increasing the oversampling ratio forextremely imbalanced big data classification. In: IEEE TrustCom/BigDataSE/ISPA, Volume 2. USA: IEEE; 2015.p. 180–5.
85. Galpert D, Del Río S, Herrera F, Ancede-Gallardo E, Antunes A, Aguero-Chapin G. An effective big data supervisedimbalanced classification approach for ortholog detection in related yeast species. BioMed Res Int. 2015.article 748681.
86. Wang X, Liu X, Matwin S. A distributed instance-weighted SVM algorithm on large-scale imbalanced datasets. In:IEEE International Conference on Big Data. USA: IEEE; 2014. p. 45–51.
87. Bhagat RC, Patil SS. Enhanced SMOTE algorithm for classification of imbalanced big-data using random forest. In:IEEE International Advance Computing Conference (IACC). USA: IEEE; 2015. p. 403–8.
88. Zhai J, Zhang S, Wang C. The classification of imbalanced large data sets based on mapreduce and ensemble ofelm classifiers. Int J Mach Learn Cybern. 2016. doi:10.1007/s13042-015-0478-7.
89. Triguero I, Galar M, Vluymans S, Cornelis C, Bustince H, Herrera F, Saeys Y. Evolutionary undersampling forimbalanced big data classification. In: IEEE Congress on Evolutionary Computation, CEC. USA: IEEE; 2015.p. 715–22.
90. Triguero I, Galar M, Merino D, Maillo J, Bustince H, Herrera F. Evolutionary undersampling for extremelyimbalanced big data classification under apache spark. In: IEEE Congress on Evolutionary Computation, CEC, InPress. USA: IEEE; 2016.
91. Park S-h, Kim S-m, Ha Y-g. Highway traffic accident prediction usin vds big data analysis. J Supercomput. 2016.doi:10.1007/s11227-016-1624-z.
92. Chen F, Jiang L. A parallel algorithm for datacleansing in incomplete information systems using mapreduce. In:10th International Conference on Computational Intelligence and Security (CIS). Kunmina, China; 2014.p. 273–7.
93. Zhang J, Wong JS, Pan Y, Li T. A parallel matrix-based method for computing approximations in incompleteinformation systems. IEEE Trans Knowl Data Eng. 2015;27(2):326–39.
94. Zhang Y, Yu J, Wang J. Parallel implementation of chi2 algorithm in mapreduce framework. In: Human CenteredComputing – First International Conference, HCC. Germany: Springer; 2014. p. 890–9.
95. Ramírez-Gallego S, García S, Mourino-Talin H, Martínez-Rego D, Bolon-Canedo V, Alonso-Betanzos A, Benitez JM,Herrera F. Distributed entropy minimization discretizer for big data analysis under apache spark. In: IEEETrustCom/BigDataSE/ISPA, Volume 2. USA: IEEE; 2015. p. 33–40.
96. Ramírez-Gallego S, García S, Mouriño-Talín H, Martínez-Rego D, Bolón-Canedo V, Alonso-Betanzos A, Benítez JM,Herrera F. Data discretization: taxonomy and big data challenge. Wiley Interdiscip Rev Data Min Knowl Disc.2016;6(1):5–21.
97. Triguero I, Peralta D, Bacardit J, García S, Herrera F. MRPR: A mapreduce solution for prototype reduction in bigdata classification. Neurocomputing. 2015;150 Part A:331–45.
98. Triguero I, Peralta D, Bacardit J, García S, Herrera F. A combined mapreduce-windowing two-level parallel schemefor evolutionary prototype generation. In: IEEE Congress on Evolutionary Computation (CEC); 2014. p. 3036–043.
99. García S, Luengo J, Herrera F. Tutorial on practical tips of the most influential data preprocessing algorithms indata mining. Knowl-Based Syst. 2016. doi:10.1016/j.knosys.2015.12.006.
100. Hashem IAT, Yaqoob I, Anuar NB, Mokhtar S, Gani A, Khan SU. The rise of “big data” on cloud computing: Reviewand open research issues. Inf Syst. 2015;47:98–115.
101. Tsapanos N, Tefas A, Nikolaidis N, Pitas I. A distributed framework for trimmed kernel k-means clustering. PatternRecogn. 2015;48(8):2685–698.
102. Chen Y, Li F, Fan J. Mining association rules in big data with ngep. Clust Comput. 2015;18(2):577–85.
103. Aghabozorgi S, Seyed Shirkhorshidi A, Ying Wah T. Time-series clustering – a decade review. Inf Syst. 2015;53(C):16–38.
104. Zhu Q, Zhang H, Yang Q. Semi-supervised affinity propagation clustering based on subtractive clustering forlarge-scale data sets. In: Intelligent Computation in Big Data Era. Germany: Springer; 2015. p. 258–265.
105. Triguero I, García S, Herrera F. SEG-SSC: a framework based on synthetic examples generation for self-labeledsemi-supervised classification. IEEE Trans Cybern. 2015;45(4):622–34.
106. Gupta S. Learning Real-time Processing with Spark Streaming. Birmingham: PACKT Publishing; 2015.
107. Works K, Rundensteiner EA. Practical identification of dynamic precedence criteria to produce critical results frombig data streams. Big Data Res. 2015;2(4):127–44.
108. Luts J. Real-time semiparametric regression for distributed data sets. IEEE Trans Knowl Data Eng. 2015;27(2):545–57.
109. Sun D, Zhang G, Yang S, Zheng W, Khan SU, Li K. Re-stream: Real-time and energy-efficient resource schedulingin big data stream computing environments. Inf Sci. 2015;319:92–112.
110. De Francisci Morales G, Bifet A. Samoa: Scalable advanced massive online analysis. J Mach Learn Res. 2015;16(1):149–53.
111. Gutiérrez PA, Pérez-Ortiz M, Sánchez-Monedero J, Fernandez-Navarro F, Hervás-Martínez C. Ordinal regressionmethods: survey and experimental study. IEEE Trans Knowl Data Eng. 2015;28(1):127–46.
112. Gibaja E, Ventura S. A tutorial on multilabel learning. ACM Comput Surv. 2015;47(3):52–15238.
Selamlar, Yazılarınızı ilgiyle takip ediyorum, katkılarınızdan dolayı teşekkür ederim. bu yazınızda belirttiğiniz big data analytics dergisine nerden ulaşabilirim. webde ilgili bir kayıt bulamadım
BioMed Central tarafından publish edilen dergi mi acaba
Evet aynen öyle.
https://bdataanalytics.biomedcentral.com/