

![]()
K-Fold Cross Validation, sınıflandırma modellerinin değerlendirilmesi ve modelin eğitilmesi için veri setini parçalara ayırma yöntemlerinden biridir. Bu yazımızda k-fold cross validation (k sayısı kadar çapraz doğrulama) yöntemini anlatmaya çalışacağım.
Elimizde bin kayıtlık bir veri seti olsun. Biz bu veri setinin bir kısmı ile modelimizi eğitmek, bir kısmı ile eğittiğimiz modelimizin başarısını değerlendirmek istiyoruz. Basit yaklaşım; %75’ini eğitim için, %25’ini de test için ayırmaktır. Ancak burada veri parçalanırken verinin dağılımına bağlı olarak modelin eğitim ve testinde bazı sapmalar (bias) ve hatalar oluşabilir. İşte k-fold cross validation, veriyi belirlenen bir k sayısına göre eşit parçalara böler, her bir parçanın hem eğitim hem de test için kullanılmasını sağlar, böylelikle dağılım ve parçalanmadan kaynaklanan sapma ve hataları asgariye indirir. Ancak modeli k kadar eğitmek ve test etmek gibi ilave bir veri işleme yük ve zamanı ister. Bu durum eğitim ve testi kısa süren küçük ve orta hacimli veriler için sorun olmasa da büyük hacimli veri setlerinde hesaplama ve zaman yönünden maliyetli olabilir.
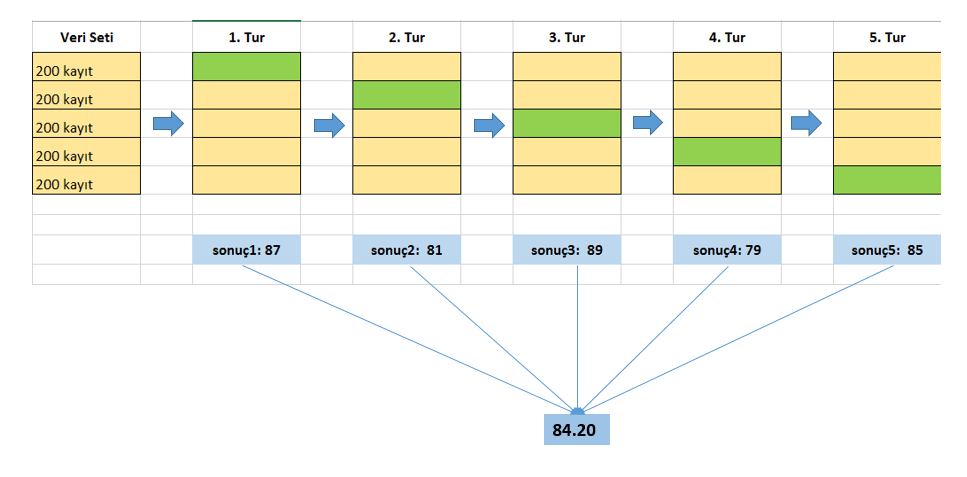
Yukarıdaki şekil ile hemen k-fold cross validation mantığını anlayalım. En soldaki dikdörtgen 1000 kayıtlık veri setini temsil ediyor. Bu veri setini beş eşit parçaya ayırıyoruz. K burada beş oluyor. Algoritmayı, eğitim ve test setleri üzerinde beş defa çalıştırıyoruz. Birinci turda ilk 1-200 kaydı teste, 201-1000 kayıtları eğitime; ikinci turda 201-400 arası kayıtları teste, kalanları eğitime ayırıyoruz. Bu şekilde beş turu tamamlıyoruz. Her turda elde ettiğimiz test sonucunu topluyor ve beşe bölüyoruz. Çıkan sonuç model performans puanımızı veriyor. Bunu bir çok farklı sınıflandırma algoritması üzerinde denedikten sonra en yüksek puan alan algoritma daha başarılı sınıflandırmıştır diyoruz. Elbette veriyi parçalara ayırmanın ve model performansı için metrik belirlemenin de kendine göre incelikleri var ancak bu yazının amacı k-fold cross validation kavramını kısaca açıklamak olduğu için onlara girmiyorum.
5 X 2 Cross Validation
Bu yüntem k-fold cross-validation tekniğinin değişik vir versiyonudur. Bu teknikte tüm veri seti her defasında rastgele ikiye bölünür. Önce bir yarısı eğitim diğer yarısı test olarak kullanılır. Daha sonra tam tersi yapılır. Bu süreç istendiği kadar (N defa) tekrarlanır ve test sonuçları toparlanır (örneğin ortalaması). Süreç aşağıdaki grafikle de anlatılmaya çalışılmıştır.
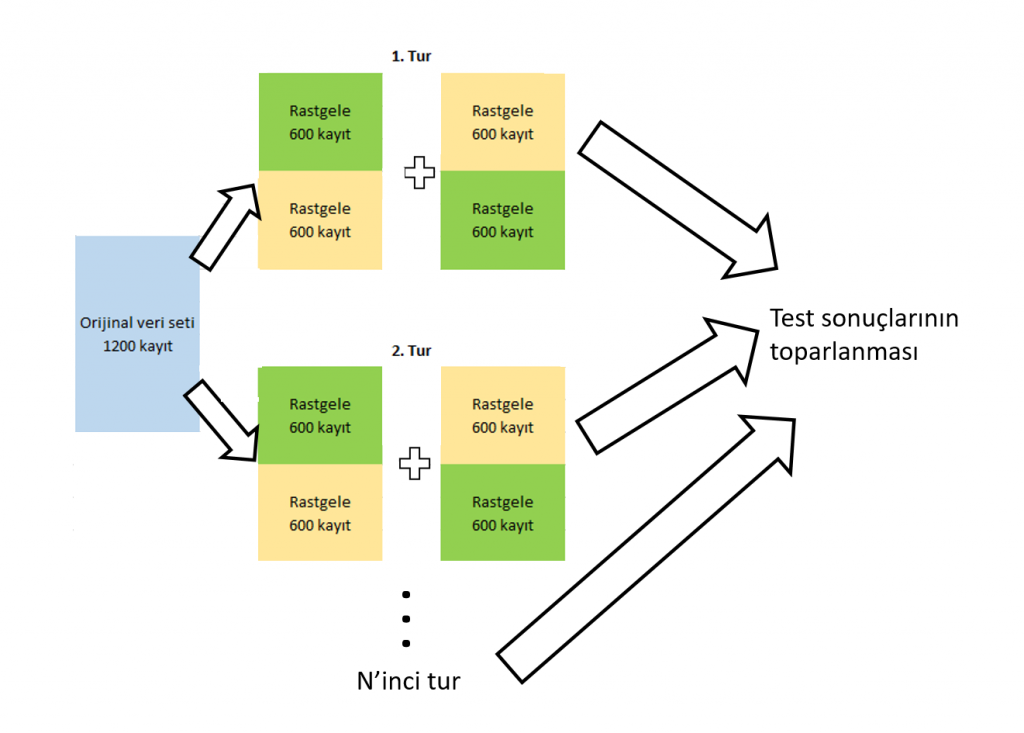
Veriyle kalın…
Gayet açıklayıcı ve net bir yazı olmuş. Paylaşım için teşekkürler.
Teşekkür ederim Alkan Bey. İyi çalışmalar…
Merhaba yazınız gayet açıklayıcı ve güzel yalnız kafama takılan tek bir yer var.K sayısını neye göre belirliyoruz acaba örneğin bir çok örnekte k=10 iken bazı örneklerde k farklı değerler alabiliyor.
Merhaba, geç cevap için kususra bakmayın. Benim gördüğüm K sayısı genelde 5 veya 10 alınıyor. Burada önemli olan her bir parçanın verinin genel dağılımını temsil edebilecek asgari örneklem sayısına haiz bulunmasıdır. Eğer veriniz çok az elemandan oluşuyorsa ve siz çok yüksek bir K sayısı belirliyorsanız, her bir parça veriyi temsilden uzaklaşacak ve model testi konusunda sıkıntılar oluşacaktır. https://stats.stackexchange.com/questions/27730/choice-of-k-in-k-fold-cross-validation burada daha fazla bilgi edinebilirsiniz.
Görüntü sınıflandırmada bu yöntemin başarısı nasıldır. Ben CNN algoritmasına bu yöntemi uyguladım fakat başarı oranı yarı yarıya azaldı. Bunun sebebi nedir?
Merhaba. CV modelinizi değerlendirmenize ve sıhhati konusunda kanaat edinmenize yardımcı olur. Başarı daha çok kullandığınız sınıflandırıcı ve kullandığınız hiperparametreler ile ilgilidir. CV ortalaması, basit bölmedeki test seti ile genelde yakın çıkar. Fark büyük ise veri heterojen olabilir veya seçimle ilgili bir hata olabilir. Seçtiğiniz k sayısı çok büyükse test setinin değerlendirme gücü zayıflar ve performansı kötü gösterebilir. Şimdilik aklıma gelen bunlar. Kolay gelsin…