

![]()
Lineer Regresyon serimize devam ediyoruz. Bu yazı bir öncekinin aynısı olacak ancak uygulamayı Python yerine R ile yapacağız. Çalışma dizninizi ayarlamayı unutmayın. Veri setine buradan ulaşabilirsiniz.
R ile Veri Setini Yükleme
dataset = read.csv('Kidem_ve_Maas_VeriSeti.csv')
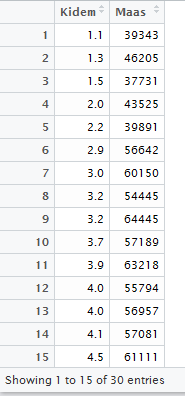
Bağımsız değişkenimiz Kidem, bağımlı değişkenimiz Maas yukarıdaki tabloda görülmektedir. Gerçek hayatta da tecrübe ettiğimiz gibi kıdem arttıkça maaş da artar. Yani bağımsız ve bağımlı değişken arasında doğrusal pozitif bir ilişkinin varlığından söz edebiliriz. Bu yazıda R kodları ve grafikleri ile bu doğrusal ilişkiyi daha bilimsel bir yöntemle ortaya koyacağız. Veri setimizi yükledikten sonra işimize başlayalım:
R ile Veri Setini Eğitim ve Test olarak İkiye Ayırma
library(caTools) set.seed(123) split = sample.split(dataset\$Maas, SplitRatio = 2/3) training_set = subset(dataset, split == TRUE) test_set = subset(dataset, split == FALSE)
Yukarıda ne yaptık kısaca açıklayayım: Kütüphane yükledik, rastgele örnekleme temel olacak bir rakam belirledik seed(123), hedef değişkenimizin 2/3’ünü eğitim seti olacak şekilde ayırdık ve eğitim için seçilenlere TRUE, test için seçilenlere FALSE damgasını vurduk. training_set ve test_set’i vurduğumuz bu damgalara göre ayırıp oluşturduk.
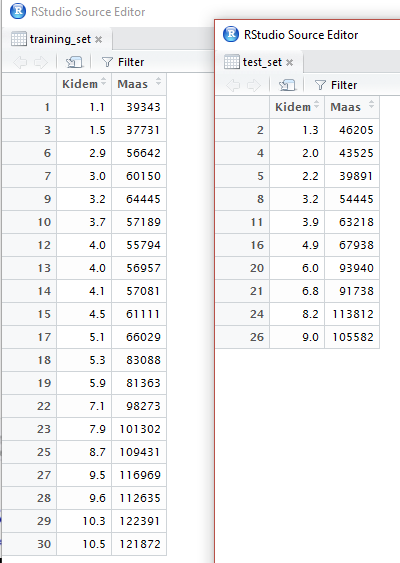
Evet yukarıda gördüğümüz gibi veri setimizi eğitim ve test olmak üzere ikiye ayırdık.
R ile Regresyon Modeli Kurma ve Modeli Eğitme
regressor = lm(formula = Maas ~ Kidem, data = training_set)
Modelimiz hakkında biraz bilgi alalım:
Regresyon Modeli Hakkında Bilgi Alma Sonuçları Yorumlama
summary(regressor) Call: lm(formula = Maas ~ Kidem, data = training_set) Residuals: Min 1Q Median 3Q Max -7325.1 -3814.4 427.7 3559.7 8884.6 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 25592 2646 9.672 1.49e-08 *** Kidem 9365 421 22.245 1.52e-14 *** --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 5391 on 18 degrees of freedom Multiple R-squared: 0.9649, Adjusted R-squared: 0.963 F-statistic: 494.8 on 1 and 18 DF, p-value: 1.524e-14
Yukarıdaki bilgileri biraz yorumlayalım. Biz kıdeme göre maaşı tahmin eden bir model kurmayı hedeflemiştik. Daha doğrusu kıdeme göre maaşı belirlemek istiyoruz. İkisinin arasında nasıl bir ilişki var, kıdem maaşı ne doğrultuda ve ne derece etkiliyor ortaya koymak istiyoruz. Bu probleme uygun model basit doğrusal regresyon modeli. Niçin? Çünkü tek bir belirleyici değişken (kıdem) var ve hedef değişkenimiz de nümerik-sürekli bir değişken. Ve biz problemde hedef değişkenimizi (maaş) herhangi bir sınıfa sokmaya çalışmayıp hedef değişkenimizi (maaş) tahmin etmeye çalışıyoruz. Bu sebeple yukarıdaki bilgilerden bizim için en önemli olanlardan biri katsayılar yani kıdemin önündeki katsayı. Bu katsayı kıdemin maaşı ne derecede etkilediğinin bir göstergesi. Tabi modelimiz ve katsayımızın p değeri istatistiksel bir anlamlılığa (statistically significant) sahipse. Kidem katsayısı 9365 ve p anlamlılık işareti ***, yani anlamlı. Pardon bundan önce modelin anlamlılığına da bakmamız lazım. Modelin anlamlılığı en alt satırdaki p-value: 1.524e-14 gibi neredeyse sıfıra yakın bir değer yani oldukça güçlü bir anlamlılığa sahip. Bu değer, sosyal bilimlerde çoğu zaman 0.05 ve altı yeterli kabul ediliyor. Kısaca modelimiz ve katsayımız anlamlıdır. Bu modeli kullanabiliriz.
Eğitilen Regresyon Modeli ile Tahmin Yapma
Modelimizi eğittik. Şimdi daha önceden test verisi olarak ayırdığımız veriyi makineye verelim bakalım bize hangi sonuçları verecek ve bu sonuçlar gerçek sonuçlara ne derece yakın.
y_pred = predict(regressor, newdata = test_set) View(y_pred)
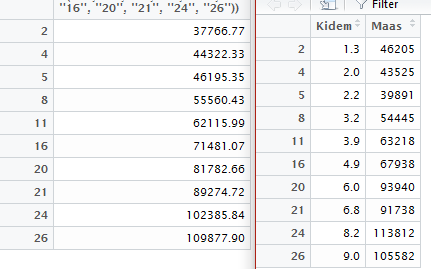
Soldaki liste modelin bize tahmin ettiği, sağdaki ise gerçekte var olan değerlerdir. Örneğin 2 numaralı kayıtta 1.3 yıl kıdem için 37.766,77 TL yıllık maaş öngörmüş. Gerçekte ise bu değer 46.205 TL.
R ile Regresyon Modeli Çizmek
Grafik çizimi için R’ın ggplot2 kütüphanesini kullanacağız. Eğer indirmemiş iseniz install.packages('ggplot2') komutuyla indirebilirsiniz. Grafik komutlarımızı yazalım.
ggplot()+
geom_point(aes(x = training_set\$Kidem, y = training_set\$Maas),
color='red')+
geom_line(aes(x = training_set\$Kidem, y = predict(regressor, newdata = training_set)),
color = 'blue')+
ggtitle('Kıdeme Göre Maaş Tahmini Regresyon Model Grafiği')+
xlab('Kıdem(Yıl)')+
ylab('Maaş(Yıllık - TL)')
Yukarıda dikkat etmek gereken bir nokta var geom_line() fonksiyonuna ikinci parametre y değerini mutlaka eğitim verileriyle elde edilen regresyon doğrusunu çizecek yani eğitim setine dayalı tahmin çizgisini vermemiz gerekir. Eğer geom_point() saçılma diyagramı fonksiyonundaki gibi y parametresine Maas verirsek yanlış olur. Grafiğimiz:
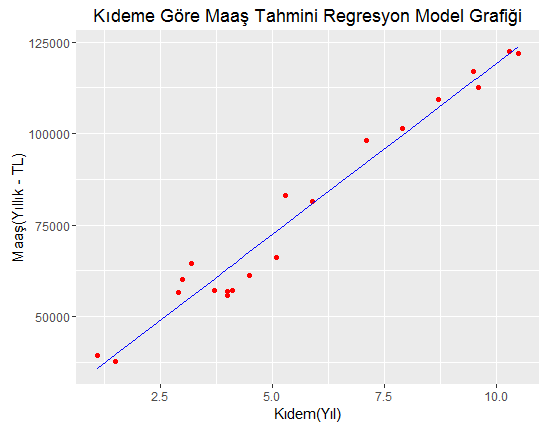
Eğitilen Regresyon Modelini ve Test Verileri Saçılma Diyagramını Çizmek
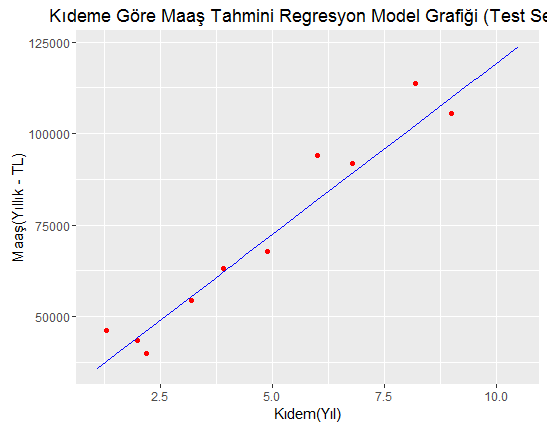
ggplot()+
geom_point(aes(x = test_set\$Kidem, y = test_set\$Maas),
color='red')+
geom_line(aes(x = training_set\$Kidem, y = predict(regressor, newdata = training_set)),
color = 'blue')+
ggtitle('Kıdeme Göre Maaş Tahmini Regresyon Model Grafiği (Test Seti)')+
xlab('Kıdem(Yıl)')+
ylab('Maaş(Yıllık - TL)')
Sadece kırmızı renk yerleri değiştirdim. İşin aslı yeni grafiğimizde regresyon doğrumuz aynı kalacak sadece etrafındaki noktalar eğitim değil test veri setindeki noktalar olacak.
Şükür bitti bu yazı da. Başka bir yazıda görüşmek dileğiyle, veriyle kalın…
hocam bu konu makine öğrenmesi ve derin öğrenmenin temel taşlarından birisi. emeğiniz için teşekkürler.
bu değerli makale için emeğinize sağlık diyorum başarılarınızın devamı diliyorum iyi çalışmalar.
Kaliteli makale icin tesekkur ederim