
Hata Matrisi (Confusion Matrix) Python Uygulama
![]()
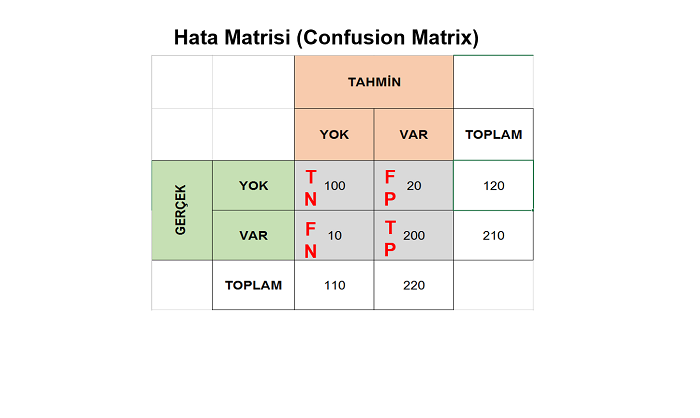
Daha anlaşılır olması için şöyle basit bir örnek yapalım. Aşağıda y_pred tahmin sonuçlarını, y_test gerçek sonuçları ve Sonuç ise hata matrisindeki karşılığı ifade etsin. Bu tabloyu tamamen kafadan attık. Çünkü en baştan veri oluştur, böl, eğit, test et vs. uğraşmayalım doğrudan hata matrisine dalalım istedik. TP,TN,FP,FN gibi kısaltmaların ne anlama geldiği bu yazıda açıklanmıştı. Sıkma […]
Hata Matrisini (Confusion Matrix) Yorumlama
![]()
Makine öğrenmesinde kullanılan sınıflandırma modellerinin performansını değerlendirmek için hedef niteliğe ait tahminlerin ve gerçek değerlerin karşılaştırıldığı hata matrisi sıklıkla kullanılmaktadır. Her ne olursa olsun sınıflandırma tahminleri şu dört değerlendirmeden birine sahip olacaktır: Doğruya doğru demek (True Positive – TP) DOĞRU Yanlışa yanlış demek (True Negative – TN) DOĞRU Doğruya yanlış demek (False Positive – FP) YANLIŞ […]
Iris Verisi ile Sınıflandırma Alıştırması (Python Scikit-Learn)

![]()
Meşhur iris verisinden daha önce bir yazımızda bahsetmiştik. Bu yazımızda iris veri seti ile Python scikit-learn kütüphanesini kullanarak basit bir sınıflandırma çalışması yapacağız. Bu alıştırmada iris çiçeğinin alt ve üst yaprak genişlik ve uzunluklarını kullanarak çiçeğin üç türünden hangisine ait olduğunu bulmaya (sınıflandırmaya) çalışacağız. Gerekli Kütüphaneleri ve Veriyi İndirme from sklearn.datasets import load_iris from sklearn.neighbors […]
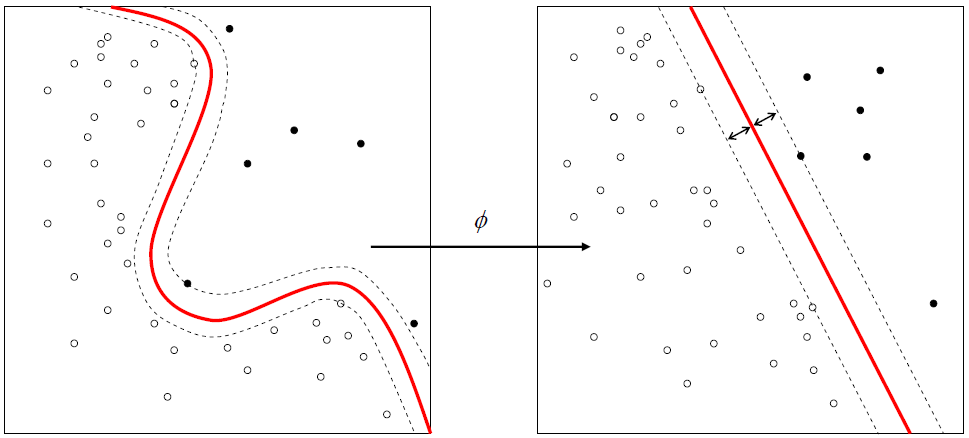
Support Vector Machine (SVM) ile Sınıflandırma: Python Örnek Uygulaması
![]()
Sınıflandırma notları serimize devam ediyoruz. Support Vector Machine (Destek Vektör Makinesi desek nasıl durur bilmiyorum) sınıflandırma için kullanılan yöntemlerden birisidir. Temel olarak iki sınıfı bir doğru veya düzlem ile birbirinden ayırmaya çalışır. Bu ayırmayı da sınırdaki elemanlara göre yapar. Kütüphaneleri İndirme, Çalışma Dizinini Ayarlama, Veri Setini İndirme Veri setini buradan indirebilirsiniz. import numpy as np […]
K En Yakın Komşu (K-Nearest Neighbor) Sınıflandırma: Python Örnek Uygulama

![]()
Sınıflandırma notları serimize devam ediyoruz. Sınıflandırma ve k en yakın komşu teorisinden daha önce bahsetmiştik. Özet olarak tekrar bir üzerinden geçelim. Sınıflandırmada bildiğimiz gibi eğittiğimiz bir model kullanarak hedef niteliğini bilmediğimiz ancak elimizde özellikleri olan bir nesnenin hangi sınıfa dahil olacağını tahmin ediyoruz. Sınıflandırma algoritmalarından k en yakın komşu en yaygın olarak kullanılan algoritmadır. Mantık […]
Lojistik Regresyon (Logistic Regression Classification) ile Sınıflandırma: Python Örnek Uygulaması

![]()
Sınıflandırma notlarımıza Lojistik Regresyon ile devam ediyoruz. Daha önce teorisinden bahsettiğimiz lojistik regresyonun Python uygulamasını yapacağız. Kütüphaneleri indirelim, çalışma dizinini ayarlayalım ve veri setimizi görelim. Veri setini buradan indirebilirsiniz. import numpy as np import matplotlib.pyplot as plt import pandas as pd import os os.chdir(‘Calisma_Dizniniz’) dataset = pd.read_csv(‘SosyalMedyaReklamKampanyası.csv’) Spyder’ın variable explorer penceresinden veri setimizi görelim: Veriyi […]
Random Forest Regresyon: R Örnek Uygulaması

![]()
Merhaba. Bu yazımızda serinin 14’üncü yazısında Python ile yaptığımız Random Forest Regresyon uygulamasını R ile yapacağız. Çalışma diznini ayarlayıp veri setini indirelim. Veriyi buradan indirebilirsiniz: setwd(‘Sizin_Calisma_Dizniniz’) dataset = read.csv(‘PozisyonSeviyeMaas.csv’) Burada randomForest paketini kullanacağız. Yüklü değil ise indirip yükleyelim: install.packages(‘randomForest’) library(randomForest) Veri setinden Pozisyon açıklamasını çıkaralım: dataset = dataset[2:3] Modelimizi oluşturalım: set.seed(1234) regressor = randomForest(x = dataset[1], […]
Random Forest Regresyon: Python Örnek Uygulaması
![]()
Random forest regresyon birden fazla karar ağacını kullanarak daha uyumlu modeller üreterek isabetli tahminlerde bulunmaya yarayan bir regresyon modelidir. Karar ağaçlarını kullandığı için kesiklidir. Yani belli bir aralıkta istenen tahminler için aynı sonuçları üretir. Bu yazımızda Python ile basit bir random forest regresyonu uygulaması yapacağız. Kütüphaneleri İndirme, Çalışma Diznini Ayarlama ve Veri Setini İndirme Veriyi buradan […]
Karar Ağacı ile Regresyon (Decision Tree Regression): R Örnek Uygulama
![]()
Merhaba. Bu yazımızda serinin 13’üncü yazısında Python ile yaptığımız Karar Ağacı Regresyon uygulamasını R ile yapacağız. Çalışma diznini ayarlayıp veri setini indirelim. Veriyi buradan indirebilirsiniz: setwd(‘Sizin_Calisma_Dizniniz’) dataset = read.csv(‘PozisyonSeviyeMaas.csv’) Burada rpart paketini kullanacağız. Yüklü değil ise indirip yükleyelim: install.packages(‘rpart’) library(rpart) Veri setinden Pozisyon açıklamasını çıkaralım: dataset = dataset[2:3] Modelimizi oluşturalım: regressor = rpart(formula = Maas ~ […]
Karar Ağacı ile Regresyon (Decision Tree Regression): Python Örnek Uygulama
![]()
Karar ağaçlarını sınıflandırma ve regresyon olarak ikiye ayırabiliriz. Karar ağacı regresyonu özetle şu işi yapıyor: Bağımsız değişkenleri bilgi kazancına göre aralıklara ayırıyor. Tahmin esnasında bu aralıktan bir değer sorulduğunda cevap olarak bu aralıktaki (eğitim esnasında öğrendiği) ortalamayı söyleyiveriyor. Bu sebeple karar ağacı regresyonu diğer regresyon modelleri gibi sürekli değil, kesiklidir. Yani belli bir aralıkta istenen tahminler […]
Support Vector Regression(SVR): R ile Uygulama

![]()
Merhaba. Bu yazımızda serinin 11’inci yazısında Python ile yaptığımız SVR uygulamasını R ile yapacağız. Çalışma diznini ayarlayıp veri setini indirelim. Veriyi buradan indirebilirsiniz: setwd(‘Sizin_Calisma_Dizniniz’) dataset = read.csv(‘PozisyonSeviyeMaas.csv’) Burada e1071 paketini kullanacağız. Yüklü değil ise indirip yükleyelim: install.packages(‘e1071’) library(e1071) Veri setinden Pozisyon açıklamasını çıkaralım: dataset = dataset[2:3] Modelimizi oluşturalım: regressor = svm(formula = Maas ~ ., data […]
Support Vector Regression (SVR): Python ile Uygulama
![]()
Bu yazımızda polinom regresyonda kullandığımız veri seti üzerinde SVR uygulayacağız. Dilimiz Python olacak. Kütüphaneleri İndirme, Çalışma Diznini Ayarlama ve Veri Setini İndirme Veriyi buradan indirebilirsiniz. import numpy as np import matplotlib.pyplot as plt import pandas as pd import os os.chdir(‘Sizin_Calisma_Dizniniz’) dataset = pd.read_csv(‘PozisyonSeviyeMaas.csv’) Veriyi Anlamak Yukarıdaki tabloda niteliklerimizi görüyoruz: Pozisyon: İş Ünvanı. Nitelik türü kategorik. […]
Polinom Regresyon: R ile Uygulama

![]()
Merhaba. Bu yazımızda serinin 8 ve 9’uncu yazısında Python ile yaptığımız Polinom Lineer Regresyon uygulamasını R ile yapacağız. Çalışma diznini ayarlayıp veri setini indirelim. Veriyi buradan indirebilirsiniz: setwd(‘Sizin_Calisma_Dizniniz’) dataset = read.csv(‘PozisyonSeviyeMaas.csv’) Veri setimizi görelim: View(dataset) Veriyi Anlamak Yukarıdaki tabloda niteliklerimizi görüyoruz: Pozisyon: İş Ünvanı. Nitelik türü kategorik. Seviye: İş ünvanlarını birbiri arasında maaş, astlık-üstlük […]
Polinom Regresyon: Python ile Uygulama-2
![]()
Python ile polinom lineer regresyon yazımıza kaldığımız yerden devam ediyoruz. Son olarak yeni X_poly nitelikler matrisini oluşturmuş, poly_reg nesnesine bu matrisi parametre vererek modelimizi oluşturmuştuk. Lineer Regresyon Modelin Grafiğini Çizmek Bir önceki yazımızda da söylediğimiz gibi burada lineer model oluşturup grafik ile göstermek istememizin sebebi polinom regresyonu daha iyi anlayabilmekti. Bu sebeple önce lineer modelimizin […]
Polinom Regresyon: Python ile Uygulama-1
![]()
Basit ve çoklu lineer regresyonda bağımlı değişken ile bağımsız değişkenler arasındaki ilişki doğrusaldı. Ancak gerçek hayatta bazı durumlarda değişkenler arası ilişki doğrusal olmayabilir. Böyle durumlarda ilişkiyi modellemek için Polinom Regresyon kullanılabilir. Basit lineer regresyon eşitliği: y = c + bX Çoklu lineer regresyon eşitliği: y = c + b1X1 + b2X2 …… + biXi Polinom […]
Çoklu Regresyon (Multiple Regression): R ile Uygulama
![]()
Lineer Regresyon Notlarımıza devam ediyoruz. Son iki yazıda Python ile yaptığımız çoklu lineer regresyonu bu yazımızda R ile yapacağız. Teorik olarak Lineer Regresyon Notları ilk dört yazıda iyi kötü bir şeyler söyledik. Burada teoriden bahsetmeyeceğim. Öncelikle olayı anlamak adına elimizdeki veri seti nedir, kuracağımız model ile neyi çözmeyi amaçlıyoruz, hangi nitelikler hangi değişkenlerle eşleşiyor biraz […]
Çoklu Regresyon (Multiple Regression): Python ile Uygulama-2
![]()
Python ile çoklu lineer regresyon yazımıza devam ediyoruz. Geçen yazıda veri setini eğitim ve test olmak üzere ayırmıştık. Bu yazımızda makinemizi oluşturup eğiteceğiz. Yine scikit-learn linear_model kütüphanesinden LinearRegression sınıfını kullanacağız. Çoklu Lineer Modeli Eğitmek from sklearn.linear_model import LinearRegression regressor = LinearRegression() regressor.fit(X_train, y_train) Makinemizi (regressor) eğittik. Şimdi test edelim bakalım bize ne sonuçlar veriyor. Bunun […]
Çoklu Regresyon (Multiple Regression): Python ile Uygulama-1
![]()
Lineer Regresyon Notlarımıza devam ediyoruz. Bu yazımızda Python ile çoklu lineer regresyon uygulaması yapacağız. Teorik olarak ilk dört yazıda iyi kötü bir şeyler söyledik. Burada teoriden bahsetmeyeceğim. Öncelikle olayı anlamak adına elimizdeki veri seti nedir, kuracağımız model ile neyi çözmeyi amaçlıyoruz, hangi nitelikler hangi değişkenlerle eşleşiyor biraz bahsetmek istiyorum. Önce veri setimizi indirip Spyder’ın yakışıklı […]
Regresyon Modeli Kurmak
![]()
Lineer regresyonun bazı varsayımları var: Doğrusallık (linearity) Eşvaryanslık (homoscedasticity) Çok değişkenli normallik (multivariate normality) Hataların bağımsızlığı (independence of errors) Çoklu bağlantı yokluğu (multicollinearity) Bir lineer model kurmadan önce yukarıdaki varsayımların karşılandığını kontrol etmek gerekir. Regresyon Modeli Kurmak Lineer modelde iki farklı değişkenimiz vardı: ilki bağımlı değişken (hedef değişken – y) diğeri ise bağımsız değişken(ler)(predictors – […]
Basit Regresyon: R ile Uygulama
![]()
Lineer Regresyon serimize devam ediyoruz. Bu yazı bir öncekinin aynısı olacak ancak uygulamayı Python yerine R ile yapacağız. Çalışma dizninizi ayarlamayı unutmayın. Veri setine buradan ulaşabilirsiniz. R ile Veri Setini Yükleme dataset = read.csv(‘Kidem_ve_Maas_VeriSeti.csv’) Bağımsız değişkenimiz Kidem, bağımlı değişkenimiz Maas yukarıdaki tabloda görülmektedir. Gerçek hayatta da tecrübe ettiğimiz gibi kıdem arttıkça maaş da artar. Yani bağımsız ve […]