
Hiyerarşik Kümeleme Python Uygulama

![]()
Kümeleme ve hiyerarşik kümelemede ilerlemeye devam ediyoruz. Bu yazımızda Python hiyerarşik kümeleme uygulaması yapacağız. Önce kütüphaneleri ve veri setini yükleyelim: Veri setini buradan indirebilirsiniz. import numpy as np import matplotlib.pyplot as plt import pandas as pd import os os.chdir(‘Calisma_Dizniniz’) dataset = pd.read_csv(‘Mall_Customers.csv’) Spyder varialble explorer ekranından veri setimizi görelim. Veriyi Anlamak Yukarıda görülen veri seti […]
Hiyerarşik Kümeleme ve R ile Dendogram Çizmek

![]()
Bir önceki yazımızda hiyerarşik kümelemeden bahsetmiştik. Noktaları ve kümeleri birleştire birleştire tek büyük bir kümeye ulaşmıştık ve bu küme ne işimize yarayacak demiştik. Cevabı dendogramda saklı. Aslında hiyerarşik kümelemede belirlenen adımlar uygulanırken her hareket kaydediliyor ve dendogram oluşturuluyor. Bu yazımızda dendogram ne işe yarar, nasıl oluşturulur, nasıl okunur? sorularının cevabını R ile yapacağımız basit bir […]
Hiyerarşik Kümeleme Giriş

![]()
Hiyerarşik kümeleme de K-Ortalamalar tekniği gibi aslında aynı sonucu hedefliyor fakat, farklı bir yöntemle, taneciklerden bütüne doğru ilerliyor. K-Ortalamalar tekniğinde olduğu gibi küme kullanıcıdan sayısını istemiyor. İki tip hiyerarşik kümeleme yöntemi var: Agglomerative (sözlük karşılığı yığınsal) ve Divisive (bölücü). Agglomerative yöntemde başlangıçta her nokta bir kümedir. Bu nokta, en yakınındaki noktaları toplayarak küçük kümeleri, daha […]
K-Ortalamalar Tekniği (K-Means Clustering) İle Kümeleme: Python Uygulaması

![]()
Daha önceki üç yazıda kümeleme ve K-ortalamalar algoritmasının temel mantığından ve küme sayısını seçme yönteminden bahsettik. Bu yazımızda Python ile K-Ortalamalar tekniğini kullanarak uygulama yapacağız. Önce kütüphaneleri ve veri setini yükleyelim:Veri setini buradan indirebilirsiniz. import numpy as np import matplotlib.pyplot as plt import pandas as pd import os os.chdir(‘Calisma_Dizniniz’) dataset = pd.read_csv(‘Mall_Customers.csv’) Spyder varialble explorer […]
K-Ortalamalar Kümeleme (K-Means Clustering) Tekniğinde Küme Sayısını Belirlemek

![]()
Kümeleme serimizin son iki yazısında kümeleme konusuna giriş yaptık ve K-Ortalamalar algoritmasının temel çalışma mantığından bahsettik. Bu yazımızda küme sayısının nasıl seçileceğinden bahsedeceğiz. Öncelikle bir çok konuda olduğu gibi ideal küme sayısını neye göre seçeceğimizi belirleyecek bir metrik olmalıdır. Kümelemedeki temel mantığı hatırlayalım: Birbirine benzeyenler, yakın olanlar aynı kümede olsun birbirine benzemeyenlerle mümkün olduğunca uzak […]
K-Ortalamalar Kümeleme (K-Means Clustering) Giriş

![]()
Kümeleme notlarına devam ediyoruz. Serinin bir önceki yazısında kümeleme kavramına giriş yapmış uzaklık ve benzerlikten bahsetmiştik. Bu yazımızda K-Ortalamalar kümeleme tekniğine giriş yapacağız. Adım adım K-ortalamalar kümeleme algoritması nasıl çalışır bakalım: Öncelikle kaç tane küme elde etmek istediğimizi belirtelim. Optimal küme sayısı bulma konusunda yazacağım sonra. Seçilen küme sayısı kadar rastgele bir küme merkezi (centroid) seçme. […]
Hadoop Ekosistemi Temel Bileşenler: HDFS, MapReduce, YARN ve Spark

![]()
Merhaba bu yazımda büyük verinin en önde gelen teknolojisi Hadoop ve onun temel bileşenleri ve çevre bileşenlerinden kısa kısa bahsedeceğim. Amacım ne nedir ne işe yarar sorularına basit ve öz cevaplar vererek Hadoop ve ekosistemi hakkında genel bilgi vermektir. Google’dan önce Doug Cutting ve Mike Cafarella webi crawl etmek ve indekslemek suretiyle bir arama motoru […]
Veri Madenciliğinde Kümeleme (Clustering)

![]()
√Kümeleme sınıflandırmadan farklı olarak denetimsiz/eğitimsiz bir yöntemdir. Sınıflandırmada bir hedef değişken vardır ve veri setinin bir kısmı eğitim için ayrılır, modelin öğrenmesini sağlanır. Bu öğrenmeye göre aynı niteliklere sahip yeni bir nesnenin hangi sınıfa dahil olacağı tahmin edilir. Kümelemede ise hedef değişken yoktur dolayısıyla sınıf da yoktur. Sınıflandırmada amaç benzer nesneleri aynı sınıfa dahil etmek […]
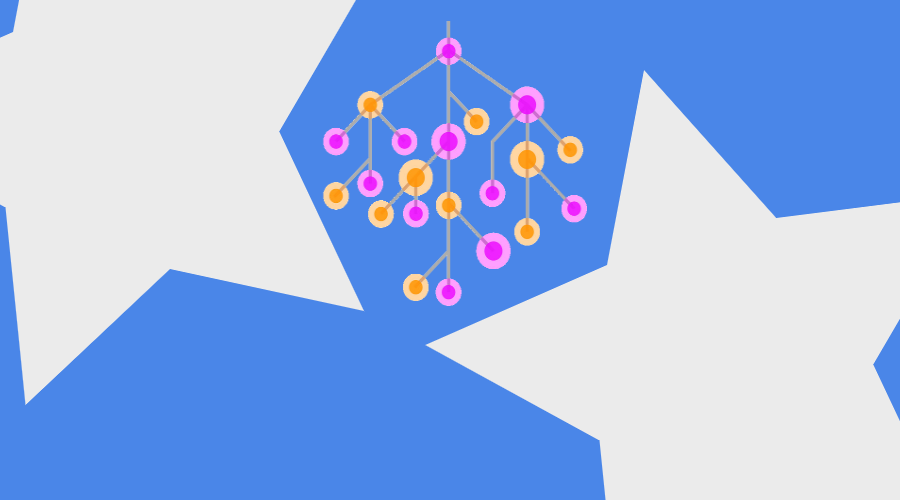
Karar Ağaçlarında Random Forest Tekniği ile Sınıflandırma: Örnek R Uygulaması
![]()
Python ile yaptığımız Random Forest örneğini bu yazımızda R ile yapacağız. Çalışma Dizinini Ayarlama, Veri Setini İndirme Veri setini buradan indirebilirsiniz. setwd(‘Calisma_Dizininiz’) dataset = read.csv(‘SosyalMedyaReklamKampanyası.csv’, encoding = ‘UTF-8’) Veri Seti Görünüm Veriyi Anlamak Yukarıda gördüğümüz veri seti beş nitelikten oluşuyor. Veri seti bir sosyal medya kayıtlarından derlenmiş durumda. KullaniciID müşteriyi belirleyen eşsiz rakam, Cinsiyet, Yaş, […]
Karar Ağaçlarında Random Forest Tekniği ile Sınıflandırma: Örnek Python Uygulaması
![]()
Random forest, birden fazla karar ağacını kullanarak daha uyumlu modeller üreterek daha isabetli sınıflandırma yapmaya çalışan bir sınıflandırma modelidir. Bu yazımızda Python ile basit bir random forest sınıflandırması uygulaması yapacağız. Kütüphaneleri İndirme, Çalışma Dizinini Ayarlama, Veri Setini İndirme Veri setini buradan indirebilirsiniz. import numpy as np import matplotlib.pyplot as plt import pandas as pd import […]
Karar Ağacı ile Sınıflandırma (Classification with Decision Tree): R ile Örnek Uygulama
![]()
Python ile yaptığımız Karar Ağacı örneğini bu yazımızda R ile yapacağız. Çalışma Dizinini Ayarlama, Veri Setini İndirme Veri setini buradan indirebilirsiniz. setwd(‘Calisma_Dizininiz’) dataset = read.csv(‘SosyalMedyaReklamKampanyası.csv’, encoding = ‘UTF-8’) setwd(‘Calisma_Dizininiz’) dataset = read.csv(‘SosyalMedyaReklamKampanyası.csv’, encoding = ‘UTF-8’) Veri Seti Görünüm Veriyi Anlamak Yukarıda gördüğümüz veri seti beş nitelikten oluşuyor. Veri seti bir sosyal medya kayıtlarından derlenmiş durumda. KullaniciID müşteriyi belirleyen eşsiz rakam, Cinsiyet, […]
Python ile Karar Ağacı (Decision Tree with Python)
![]()
Karar ağaçları sınıflandırma problemlerinin çözümünde yaygın olarak kullanılan algoritmalardandır. Anlaşılması diğer algoritmalara göre daha kolaydır. Karar ağacında öncelikle ağaç oluşturulur ve eldeki veri bu ağaca uygulanır. Bu yazımızla Python dilinde karar ağacı kullanarak sınıflandırma uygulaması yapacağız. Kütüphaneleri İndirme, Çalışma Dizinini Ayarlama, Veri Setini İndirme Veri setini buradan indirebilirsiniz. import numpy as np import matplotlib.pyplot as […]
Naive Bayes Yöntemiyle Sınıflandırma (Classification with Naive Bayes): R ile Uygulama
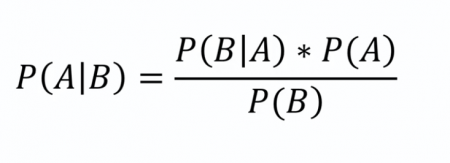
![]()
Python ile yaptığımız Naive Bayes örneğini bu yazımızda R ile yapacağız. Çalışma Dizinini Ayarlama, Veri Setini İndirme Veri setini buradan indirebilirsiniz. setwd(‘Calisma_Dizininiz’) dataset = read.csv(‘SosyalMedyaReklamKampanyası.csv’, encoding = ‘UTF-8’) Veri Seti Görünüm Veriyi Anlamak Yukarıda gördüğümüz veri seti beş nitelikten oluşuyor. Veri seti bir sosyal medya kayıtlarından derlenmiş durumda. KullaniciID müşteriyi belirleyen eşsiz rakam, Cinsiyet, Yaş, […]
Naive Bayes Yöntemiyle Sınıflandırma (Classification with Naive Bayes): Python ile Uygulama
![]()
Sınıflandırma notlarına devam ediyoruz. Teorisinden önceki yazılarda kısmen bahsettiğimiz Naive Bayes sınıflandırıcı ile uygulama yapacağız. Kütüphaneleri İndirme, Çalışma Dizinini Ayarlama, Veri Setini İndirme Veri setini buradan indirebilirsiniz. import numpy as np import matplotlib.pyplot as plt import pandas as pd import os os.chdir(‘Calisma_Dizniniz’) dataset = pd.read_csv(‘SosyalMedyaReklamKampanyası.csv’) Spyder’ın variable explorer penceresinden veri setimizi görelim: Veriyi Anlamak Yukarıda […]
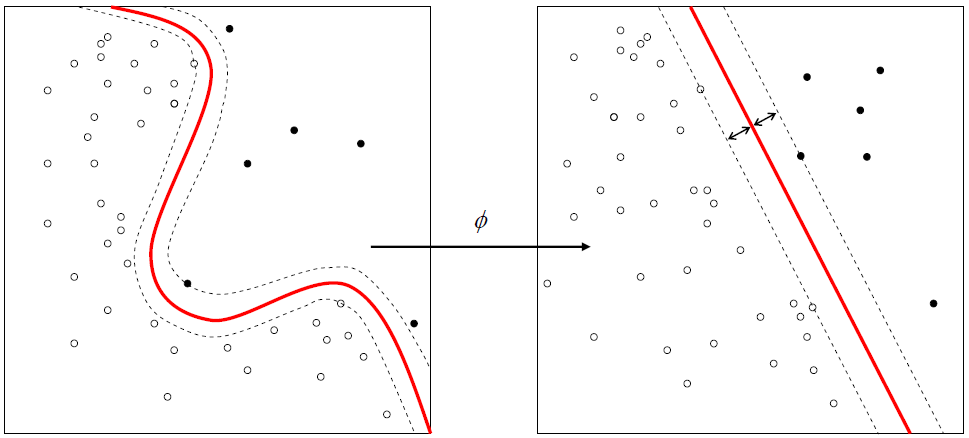
Kernel Support Vector Machine (SVM) ile Sınıflandırma: R ile Örnek Uygulama
![]()
Python ile yaptığımız Kernel SVM örneğini bu yazımızda R ile yapacağız. Çalışma Dizinini Ayarlama, Veri Setini İndirme Veri setini buradan indirebilirsiniz. setwd(‘Calisma_Dizininiz’) dataset = read.csv(‘SosyalMedyaReklamKampanyası.csv’, encoding = ‘UTF-8’) Veri Seti Görünüm Veriyi Anlamak Yukarıda gördüğümüz veri seti beş nitelikten oluşuyor. Veri seti bir sosyal medya kayıtlarından derlenmiş durumda. KullaniciID müşteriyi belirleyen eşsiz rakam, Cinsiyet, […]
Kernel Support Vector Machine (SVM) ile Sınıflandırma: Python ile Örnek Uygulama
![]()
Sınıflandırma notlarına devam ediyoruz. Bazı sınıflandırıcılar doğrusaldır (örn Lojistik regresyon) bazı sınıflandırıcılar ise doğrusal değildir (örneğin KNN). SVM de doğrusal bir doğru ile sınıfları ayırmaya çalışır. Ancak doğrusal ayraçlar doğrusal olmayanlar kadar her zaman başarılı olamaz. Doğrusal olarak birbirinden ayrılamayan sınıflar için kernel trick diye adlandırılan bir yöntem uygulanır. Bu yöntemde kernel fonksiyon uygulanarak normalde […]
K En Yakın Komşu (K-Nearest Nighbor) Sınıflandırma: R ile Örnek Uygulama

![]()
Sınıflandırma notları serimize devam ediyoruz. Sınıflandırma ve k en yakın komşu teorisinden daha önce bahsetmiştik. Özet olarak tekrar bir üzerinden geçelim. Sınıflandırmada bildiğimiz gibi eğittiğimiz bir model kullanarak hedef niteliğini bilmediğimiz ancak elimizde özellikleri olan bir nesnenin hangi sınıfa dahil olacağını tahmin ediyoruz. Sınıflandırma algoritmalarından k en yakın komşu en yaygın olarak kullanılan algoritmadır. Mantık […]
R Kare ve Düzeltilmiş R Kare

![]()
Regresyon notlarımızda bahsettiğimiz gibi regresyon eğrisi temsil ettiği noktalara olabildiğince en yakından geçmeye çalışıyordu. Bunun için her bir noktanın eğriye olan uzaklığı hesaplanıyor ve toplam mesafeyi en küçük kılan doğru regresyon doğrusu oluyordu. Yukarıda kazanç ve tecrübe arasındaki ilişkiyi gösteren bir grafik bulunuyor. Bu grafiğe göre tecrübe arttıkça kazanç da artıyor görünüyor. Grafiğe bakarak doğrusal […]
Support Vector Machine (SVM)ile Sınıflandırma: R Örnek Uygulaması
![]()
Bu yazıda Sınıflandırma Python ile yaptığımız uygulamanın aynısını R ile yapacağız. Öncelikle çalışma dizinin ayarlayalım: setwd(‘Calisma_dizini’) Veri setini yükleyelim. Veri setini buradan indirebilirsiniz. dataset = read.csv(‘SosyalMedyaReklamKampanyası.csv’, encoding = ‘UTF-8’) Türkçe karakterlerin düzgün okunması için encoding parametresini kullandık. Lazım olan sütunları seçelim. dataset = dataset[3:5] Veri Setini Eğitim ve Test Olarak Ayırmak Aynı sonuçları almak için […]
Python Listesinden Pandas Series Oluşturmak (List to Series)

![]()
Veri bilimiyle uğraşırken sık sık Python listesini Pandas Serisine (tablonun bir sütunu diye düşünelim) çevirmek durumunda kalıyorum. Her seferinde Google’da aratıp sonuçları didiklemek yerine buraya yazayım dedim basit ama çok işe yarıyor. Basit bir örnek ile uygulama yapalım: Duyduğumu unuturum, gördüğümü hatırlarım, yaptığımı bilirim. Pandas kütüphanesini indirelim: import pandas as pd Örnek Python listesini oluşturalım: […]