

![]()
Verinin her geçen gün katlanarak büyüdüğü günümüz dünyasında o veriyi işleyebilmenin ve veriden anlamlı çıkarımlarda bulunabilmenin önemi de katlanarak artmaktadır. Ancak terabaytlarca ve hatta petabaytlarca verimizin olduğu ve içinde ilişkisel veritabanlarının, NoSQL’lerin ve text, CSV ve JSON, parquet gibi yarı yapısal ve yapısal olmayan verilerin bulunduğu bir ekosistemde klasik yöntemlerle analiz yapmak çok zordur. İşte bu noktada Apache Spark devreye girer.
Spark ile ilgili çalışmalara 2009 yılında Amerika’da UC Berkeley’de Matei Zaharia önderliğinde bir grup bilgisayar bilimcisi tarafından başlandı. O zamanlarda Map Reduce dağıtık hesaplamaya imkan veren ilk açık kaynak teknoloji olarak paralel hesaplamada baskın konumdaydı. Çalışmalarının sonuçlarını 2010 yılında “Spark: Cluster Computing with Working Sets” adlı makaleyle yayınladılar. Bu makalede Map Reduce’a atıfta bulunarak, Spark ile Map Reduce’un zayıf kaldığı noktalara ürettikleri çözümleri açıklamışlardır. Scala dili ile geliştirilen Spark, 2010’da açık kaynak proje haline dönüştürülmüş, 2013’te de Apache çatısı altına girmiştir. Spark’ı geliştiren ekip 2013 ayrıca Databricks şirketini de kurmuşlardır
Resmi dökümantasyonundaki tanıma göre Apache Spark büyük ölçekli veri işleme için çok hızlı bir birleşik bir analiz motorudur. Hatta bu hız dökümanda yıldırım hızı olarak tanımlanır. Spark’ın bu kadar popüler olmasının altında da bu hız yatar. Birleşik olmasıysa, streaming ve batch veri analizi, makine öğrenmesi, graf analizi ve klasik sql komutları gibi veriyle ilgili birçok konuya çözüm getirdiğini ifade eder.
Spark Bileşenleri
Apache Spark Spark Core, Spark SQl, Spark Streaming, MLlib ve GraphX bileşenlerinden oluşmaktadır.
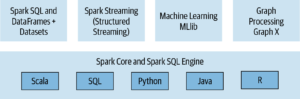
Şekil 1: Apache Spark’ın bileşenleri
1.Spark Core
Spark Core, diğer tüm bileşenlerin üzerine inşa edildiği Spark projesinin motorudur. Cluster’da görevlerin dağıtımı, zamanlaması, hafıza yönetimi gibi işleri yürütür. Core’da ayrıca low-level API’lar (RDD) ve structered API’lar (dataframe, dataset) bulunur.
RDD’ler Spark’la birlikte geliştirilen en düşük seviye API’lardır. RDD’nin açılımı Resilient Distributed Dataset’dir. Resilient olması hataya ve değişikliklere karşı dirençli olmasını (değiştirilememesini), distributed olmasıysa dağıtık olmasını ifade eder. RDD’ler üzerinde transformation ve action olmak üzere iki tip operasyon yapılabilir. Ancak hangi operasyonu yaparsak yapalım üzerinde çalıştığımız RDD değişmez, işlemlerin ve dönüşümlerin sonucu yeni bir RDD’ye atanır.
Spark 2 ile dataframe ve dataset gibi yapısal API’lar ortaya çıkmıştır. Bunlar belli bir şemaya sahip, sütunlardaki verilerin türlerinin belli olduğu (int, string gibi) tablo yapısına sahip API’lardır. Dataframe’ler hem daha hızlı hem de kullanımı daha kolay olduğu için RDD’lerden daha fazla kullanılmaya başlanmıştır. Ancak biz dataftame, dataset, Spark SQL gibi yapısal API’ları da kullansak, Spark Streaming’i de kullansak bunlar arka planda RDD’lere dönüştürülmektedir.
Scala, Python, Java ve R programlama dilleri Spark’ın yüksek seviye API’larıdır. Bu programlama dillerinden herhangi biriyle Spark geliştirmesi yapılabilir.
2.Spark SQL
Spark’ın yapısal veriyle çalışan dağıtık SQL motorudur. Spark’a özgü SQL sorgusuna benzer sorgular oluşturmaya yarar. JSON, CSV gibi dosya formatlarından çekilen verilerin dataframe’lere dönüştürülerek yapısal hale getirdikten sonra üzerlerinde SQL sorguları çalıştırılmasına olanak sağlar. Spark SQL’de Hadoop’un Hive komutları değiştirilmeden çalıştırılabilir. SQL’den vazgeçemeyen veri analistleri için doğrudan klasik sql sorgularını yazabilecekleri bir yapı da sunar. BI araçlarına bağlanmak için JDBC ve ODBC sağlayan modu vardır. Spark SQL diğer modüllerle de uyum içindedir. Mesela SQL sorgularını machine learning kütüphanesi ile birlikte kullanabilirsiniz.
3.Spark Streaming
Sosyal medya, IoT sensörleri, kuyruk mekanizmaları ve diğer streaming teknolojileri gibi kaynaklardan gelen verilerin gerçek zamanlı analizinin yapılmasını sağlar. Kafka, RabbitMQ, Kinesis, Flume, Nifi ve Twitter Spark Streaming’in veri çekebileceği kaynaklara örnek olarak gösterilebilir. Analiz sonuçları HDFS, ilişkisel veritabanları, NoSQL’ler, BI dashboardları ve kuyruk mekanizmaları gibi teknolojilere aktarılabilir. Spark Streaming ayrıca akan veriye machine learning ve GraphX algoritmalarının uygulanmasına da imkan sağlar.

Şekil – 2: Spark Stereaming’in kullandığı hedef ve kaynak sistemleri örneği
Spark Stream, gelen veriyi yığınlara (batch) böler. Bu veri yığınları bir RDD dizisi halinde Spark motoruna gelerek analiz edilir. Sonuçlar yine yığınlar halinde hedef sisteme aktarılır. Veriyi mini yığınlara bölme işleminden dolayı milisaniyeler mertebesinde gecikme (latency) yaşanır. Bu gecikmeden dolayı Spark neredeyse gerçek zamanlı (near real-time) sistem olarak anılır.

Şekil – 3: Spark Stereaming’in batch yapısı
4.Spark MLlib
Spark’ın makine öğrenmesi kütüphanesidir. Makine öğrenmesini büyük veriye uyarlayarak ölçeklenebilir bir şekilde sunmuştur. Yaygın olan classification (sınıflandırma), regression (regresyon), clustering (kümeleme) başlıklarındaki algoritmaların çoğunu destekler. Makine öğrenmesini pipeline’lar halinde belli bir düzende ve kolayca uygulanmasını sağlar. Sadece algoritmaların uygulanmasını değil, verinin hazırlık aşamasında uygulanan feature extraction (özellik çıkarma), transformation (dönüştürme) ve dimensionality reduction (boyut azaltma) gibi basamakları da destekler.
Spark’ın Mllib kütüphanesine ek olarak çeşitli firmaların Spark için ürettikleri açık kaynaklı makine öğrenmesi projeleri de vardır. Bunlara Databricks tarafından geliştirilen Spark Deep Learning kütüphanesini ve John Snow Labs tarafından geliştirilen doğal dil işleme kütüphanesi olan Spark NLP‘yi örnek gösterebiliriz. Spark Deep Learning derin öğrenmeyi dağıtık mimariye taşımıştır. TensorFlow ve Keras’ı da destekler. Mllib kütüphanesinde olduğu gibi pipeline’lar halinde uygulanır.
5.GraphX
Spark’ın graf ve ağ analizlerine imkan tanıyan kütüphanesidir. RDD’leri yönlü graflara dönüştürüp üzerinde işlem yapılmasına izin verir. Örnek kullanım alanına sosyal medya arkadaş ağlarının analizi verilebilir.
Map Reduce ile Spark karşılaştırması
Spark’ın ilk çıktığı zamanlarda Hadoop ile bolca karşılaştırılmış olsa da, ikisi birbirinden farklı teknolojilerdir. Spark’ın ana işlevi veri analizidir, bunun yanı sıra yukarıda özetlediğim MLlib gibi bileşenleri de içerir. Bir depolama birimi yoktur. Buna karşın Hadoop’un HDFS adı altında bir dosya sistemi, depolama birimi vardır. Hadoop veri analizi çözümü olan MapReduce’u da içeren geniş bir framework’tür.
MapReduce’da sadece HDFS dosya sisteminde yani disk üzerinde bulunan veri üzerinde analiz yapılabilirken Spark’ta HDFS dahil olmak üzere bir çok veri kaynağı (İlişkisel veritabanları, NoSql, Kafka, elasticsearch vb.) üzerinde analiz gerçekleştirilebilir. Spark bu analizleri yaparken ram üzerinde (in-memory) yapar, belleklerin yetmediği durumlarda diskleri de kullanır. Hızının sırrı da bellekleri kullanabilmesinde yatar. Bu yüzden Spark, Hadoop’tan 100 kat daha hızlı olduğunu iddia eder.
Spark, büyük veri ekosistemindeki birçok teknoloji gibi dağıtık mimariyi desteklediği için cluster’daki tüm sunucular üzerinde aynı anda dağıtık bir şekilde hesaplama yapar. Basit bir örnek verecek olursak cluster’ımızda her birinin 128GB ram’i olan 10 sunucumuz varsa, hesaplama yaparken 1 TB’ın üzerinde bir ram gücünü kullandığı anlamına gelir. Ram ile birlikte tüm bu sunucuların işlemci gücü de kullanılır. Spark’la birlikte kullanılan makine öğrenmesi algoritmaları için de geçerlidir bu hız. Mesela TensorFlow ve PyTorch gibi kütüphanelerle yazılan makine öğrenmesi algoritmaları tek bir ortamda çalıştırabilirken, Spark ile makine öğrenmesi uygulaması geliştirildiğinde tüm cluster’daki sunucularda çalıştırıldığı için daha hızlı olabilmektedir. Bu bağlamda Spark paralel işlem gücünü makine öğrenmesi alanına da uygulamıştır.
Sonuç
- Apache Spark hem batch hem de real-time analize izin veren bunun yanı sıra makine öğrenmesi ve graf analizi ve sql gibi veriyle ilgili bir çok alanı destekleyen açık kaynak bir büyük veri aracıdır.
- Apache Spark bu kadar özelliğine rağmen rakipsiz değildir. Flink gibi güçlü rakipleri vardır.
- Arkasında güçlü bir topluluğun olmasıyla, birçok programlama diliyle analiz yapılabilmesiyle, streaming analizlerin öneminin her geçen gün artmasıyla ve makine öğrenmesi modülünün sürekli geliştirilmesiyle Apache Spark’ın sektördeki yeri sağlamlaşmaktadır.
Kaynaklar
- https://spark.apache.org/
- https://databricks.com/spark/about
- https://github.com/databricks/spark-deep-learning
- Spark: Cluster Computing with Working Sets (Matei Zaharia, Mosharaf Chowdhury, Michael J. Franklin, Scott Shenker, Ion Stoica)
- Spark: The Definitive Guide (Bill Chambers, Matei Zaharia)