

![]()
1. Giriş
Merhabalar. Bildiğimiz gibi Spark, büyük veri dünyasının en popüler analitik motoru. Özellikle durağan büyük boyutlu veriler (persistent data) üzerinde hızlı bir şekilde makine öğrenmesi algoritmalarını çalıştırabilmesi Spark’ı farklı kılan özelliklerin başında geliyor. Arkadaşımız o kadar yetenekli ki sadece durağan verileri işlemiyor, aynı zamanda akan verileri de işleyebiliyor. Spark’ın makine öğrenmesi için bir kütüphanesi var. Aslında iki kütüphanesi var. Birisi eski RDD tabanlı ve geliştirilmesine son verilen, ikincisi dataframe tabanlı ve geliştirilmeye devam edilen. Spark 2.0 ile birlikte geliştiricileri ML kütüphanesini scikit-learn kütüphanesinden esinlenerek yeniden yarattılar. Tablovari verinin yaygınlığı sebebiyle dataframe tabanlı olan yeni ML kütüphanesi geliştirilmeye devam ediliyor. Umarım yakın zamanda scikit-learn kadar olgunlaşır. Bu arada scikit-learn kütüphanesini de Spark üzerinde dağıtık olarak kullanabilmek mümkünmüş. Ancak ben henüz denemedim, denersem tecrübelerimi paylaşabilirim.
Makine öğrenmesi denince birçok insan hemen model aşamasına odaklanır. Aslında makine öğrenmesi, bir çok safhanın ardışık olarak sıralandığı bir süreçtir. Bu süreç içerisinde modeli oluşturmak için kullanılan algoritmaların bulunduğu model safhası haricinde, veri ön işleme gibi başka aşamalar da vardır. Sanılanın aksine makine öğrenmesi, sadece makineye ham maddeyi verip bacak bacak üstüne atıp sonra da ürünün arkadan çıkmasını beklemekten ibaret değildir.

Önce problem anlaşılır, bu problemin çözümü için verinin nerelerde bulunduğu ve nasıl temin edileceği araştırılır. Veri okunur, bütünleştirilir, eksiği gediği giderilir, keşfedici analizler yapılır, nitelikler arası ilişkilere bakılır. Veri hazırlığı aşamasında kategorik değişkenler indekslenir, varsa metin (text) halindeki niteliklerin içinden sayısal nitelikler alınır. Daha sonra probleme uygun model seçilir, model değerlendirilir, ayarlamalar ve düzeltmeler yapılır. Gerekirse defalarca model tekrar eğitilir, değerlendirilir ve ayar çekilir. İşin özü aslında makine öğrenmesi süreci biraz karmaşıktır. Şayet süreç sadece aşağıdaki gibi basit olsaydı sorun yoktu.
Ancak gerçekte süreç daha karmaşıktır:
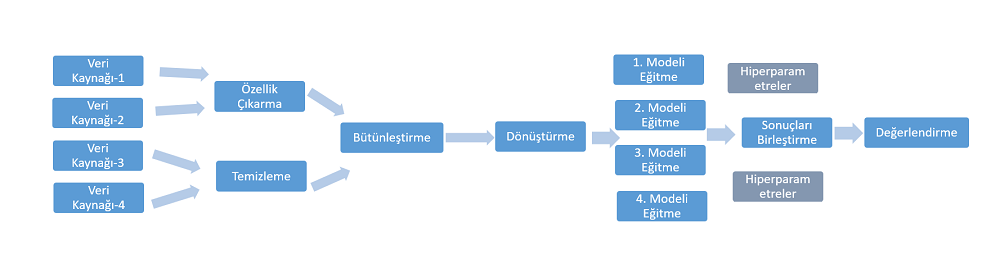
Bu karmaşıklıkla daha iyi başa çıkabilmek, belli bir düzen içerisinde makine öğrenmesi sürecini yürütmek ve veri bilimcinin işini kolaylaştırmak için ML (yeni) kütüphanesi olaya biraz daha geniş pencereden bakmış ve makine öğrenmesi sürecindeki diğer safhalarda da veri bilimcilerin işini kolaylaştırmaya çalışmış. İşte bu yazımızda ağırlıklı olarak bu konuyu yani Spark ML Pipeline kavramını ele alacağız. 4. bölüme kadar olan bölüm alıştırma ve işin altında yatan mantığı öğrenme aşamasıdır. Asıl iş; “Parçaları Pipeline ile Birleştirmek” bölümündedir. Buraya kadar olan bilgi ve uygulamalar 4. Bölümde yapılanları daha iyi anlayabilmek içindir. Şayet düzgün bir Pipeline kurabilirseniz işte o zaman bacak bacak üstüne atma muhabbetini bir nebze olsun yapabilirsiniz 🙂
1.1. Spark ML ve Pipeline ile ilgili Temel kavramlar
Pipeline’ı daha iyi anlayabilmek için ML kütüphensinde kullanılan bazı kavramların ne anlama geldiğini bilmemiz gerekiyor.
Transformer: Bir dataframe’in başka bir dataframe’e dönüştürür. Dönüşüm transform() metoduyla gerçekleşir. Bazen girdi olan dataframe bir kaç ilave sütun ile çıktı olarak üretilir. Girdi sütunlarının tek bir sütun halinde vector formatına dönüştürülmesi veya bir makine öğrenmesi modelinin bir test dataframe’i alıp çıktı olarak bir tahmin seti üretmesi Transformer’a örnek verilebilir.
class Estimator extends PipelineStage{
def transform(df: Dataset[]): Dataframe={
}
}Estimator: Girdi olarak veri alır ancak çıktı olarak bir Transformer üretir. Dönüşüm fit() metoduyla gerçekleşir. Örneğin bir öğrenme algoritması eğitim verisi ile eğitilir ve çıktı olarak model üretir. LogisticRegression bir Estimator’dür ve fit() metoduyla LogisticRegressionModel‘i eğitir.
class Estimator extends PipelineStage{
def fit(dataset: Dataset[]):Transformer = {
// dönüşümle ilgili kodlar
}
}![]()
Evaluator: Eğitim verisi ile eğitilen modelin test verisi ile uyumluluğunun değerlendirilmesi için kullanılan metriktir.BinaryClassificationEvaluator Evaluator için örnek verilebilir.
Pipeline: Muhtelif Estimator ve Transformator’lerden oluşan bir zincirdir. Pipeline safha safha ilerler, her bir safhada bir Transformator ya da Estimator olabilir. Bu safhalara PipelineStage denir. PipelineStage, belli bir dizilime sahiptir, yani sıralı bir dizidir (Array). Dataframe, her bir PipelineStage’den geçerken dönüşüme uğrar. Pipeline doğrusal olabileceği gibi döngüsel olmayan yönlendirilmiş diyagram (Directed Acyclic Graph (DAG)) ile doğrusal olmayan bir Pipeline oluşturulabilir. Her PipelineStage akış içinde bir kez yer alabilir. PipelineModel ise Pipeline nesnesine Transformator ve Estimator’ların yerleştirilmiş halidir.
Parameter: Tüm Transformer ve Estimator’lar artık parametre belirlemek için ortak bir API kullanıyor. Parametreleri algoritmalara göndermek için iki yöntem vardır: Birincisi model nesnesinin fonksiyonlarıyla. Örneğin LogisticRegression nesnesi lr olsun, lr.setMaxIter(10) ile 10 iterasyon parametresi model nesnesine verilmiş olur. İkinci yöntem ise parametreyi fit() veya trasform() metodları içinde göndermek. ParamMap içinde gönderilen parametreler setter ile daha önceden belirlenmiş olanları ezer. Şayet iki ayrı LogisticRegression nesnemiz varsa ve isimlerini lr1 ve lr2 vermişsek, ParamMap içinde maxIter özelliği ile farklı iterasyon sayısı verebiliriz: ParamMap(lr1.maxIter -> 10, lr2.maxIter -> 20).
Teorik bilgi ile daha fazla sıkılmadan hemen uygulamaya geçelim. Uygulama esnasında kullanılan yazılım geliştirme ortamı, programlama dili, işletim sistemi ve sürüm bilgileri: Spark 2.1.1, YARN, Hadoop 2.6.2, Scala 2.11, Apache Zeppelin Notebook, Spark2 interpreter.
2. Veriyi Okumak ve Anlamak
ICS UCI den veri setlerimi Windows ana makineme indirdim. Oradan WinSCP ile Hadoop Cluster Edge Sunucumun lokal diskinde /home/erkan/veri_setlerim/adult/ dizinine kopyaladım. Daha sonra aşağıdaki hdfs komutları ile veri setlerini HDFS’e taşıdım. Olası bir yetki hatasına karşın hem lokal dizinde hem HDFS’de aynı kullanıcı ile işlem yaptım.
[erkan@node3 ~]$ hdfs dfs -mkdir /user/erkan/veri_setlerim/adult [erkan@node3 ~]$ hdfs dfs -put /home/erkan/veri_setlerim/adult/adult.test /user/erkan/veri_setlerim/adult/ [erkan@node3 ~]$ hdfs dfs -put /home/erkan/veri_setlerim/adult/adult.data /user/erkan/veri_setlerim/adult/
2.1. Veriyi anlamak:
Veri seti eğitim ve test olarak iki parçaya ayrılmış durumda. Yani bununla biz uğraşmayacağız. Haklarında farklı demografik bilgiler bulunan insanlardan derlenmiş veri setinde kişilerin gelirinin ellibin dolardan büyük olup olmadığı da etiketlenmiş. Bize verilen niteliklerden öğrenme yaparak yeni bir bireyin gelirinin 50K’dan büyük olup olmadığını bulmamız isteniyor. Bu veri seti makine öğrenmesi eğitimlerinde sıklıkla kullanılır. O yüzden belki daha önce karşılaşmışsınızdır. Biz bu problemi Spark ML Pipeline kullanarak çözmeye çalışacağız.
2.2. Veriyi Yüklemek:
Yüklerken şemayı algılasın diye option("inferSchema","true") seçeneğini kullanıyoruz.
val maasDF = spark.read.format("csv").option("inferSchema","true").load("/user/erkan/veri_setlerim/adult/adult.data")
2.3. Nitelik İsimlerini Değiştirmek, Şemayı Anlamak:
Başlıkları dahil etmedim çünkü indirdiğim dosyaları incelediğimde ilk satırlarda başlık bilgisi yoktu. Ben de o yüzden indirdiğim yerden veri seti niteliklerinden bir sequence liste oluşturdum ve içine sırasıyla nitelik isimlerini yazdım:
val new_columns = Seq("age", "workclass","fnlwgt","education","education-num",
"marital-status","occupation","relationship","race","sex",
"capital-gain","capital-loss","hours-per-week","native-country","salary")
Şimdi bu listeyi kullanarak mevcut dataframe sütun isimlerini komple değiştirelim ve yenibir dataframe adresleyelim. Bildiğimiz gibi Spark’ta dataframe immutable olduğundan her dönüşüm ve değişikliği farklı bir dataframe ismiyle tutmalıyız.
val maasDF2 = maasDF.toDF(new_columns:_*)
Şemamızı yazdıralım ve nitelkler hakkında biraz daha bilgi edinelim:
maasDF2.printSchema() root |-- age: integer (nullable = true) |-- workclass: string (nullable = true) |-- fnlwgt: double (nullable = true) |-- education: string (nullable = true) |-- education-num: double (nullable = true) |-- marital-status: string (nullable = true) |-- occupation: string (nullable = true) |-- relationship: string (nullable = true) |-- race: string (nullable = true) |-- sex: string (nullable = true) |-- capital-gain: double (nullable = true) |-- capital-loss: double (nullable = true) |-- hours-per-week: double (nullable = true) |-- native-country: string (nullable = true) |-- salary: string (nullable = true)
Yukarıdaki 14 niteliği görüyoruz ve şimdi veriyi daha iyi anlamaya başladık. Muhtemelen string olanlar kategorik, double ve integer olanlar ise sürekli niteliklerdir.
2.4. Veri Seti Hakkında Temel İstatistiksel Bilgiler:
Satır sayısına bakalım:
val satirSayisi = maasDF2.count() satirSayisi: Long = 32561
Nümerik niteliklerin temel istatistiklerine bakalım:
maasDF2.describe("age","fnlwgt","education-num","capital-gain","capital-loss","hours-per-week").show()
+-------+------------------+------------------+-----------------+------------------+----------------+------------------+
|summary| age| fnlwgt| education-num| capital-gain| capital-loss| hours-per-week|
+-------+------------------+------------------+-----------------+------------------+----------------+------------------+
| count| 32561| 32561| 32561| 32561| 32561| 32561|
| mean| 38.58164675532078|189778.36651208502| 10.0806793403151|1077.6488437087312| 87.303829734959|40.437455852092995|
| stddev|13.640432553581356|105549.97769702227|2.572720332067397| 7385.292084840354|402.960218649002|12.347428681731838|
| min| 17| 12285.0| 1.0| 0.0| 0.0| 1.0|
| max| 90| 1484705.0| 16.0| 99999.0| 4356.0| 99.0|
+-------+------------------+------------------+-----------------+------------------+----------------+------------------+
Kategorik değişkenler ile hedef değişken gelir arasındaki ilişkiye çapraz tablo ile bakalım:
Kadın ve erkeklerin 50K’nın üzerinde kazanma sayıları:
maasDF2.stat.crosstab("sex","salary").show()
+----------+------+-----+
|sex_salary| <=50K| >50K|
+----------+------+-----+
| Male| 15128| 6662|
| Female| 9592| 1179|
+----------+------+-----+Erkekler sanki daha çok kazanıyor gibi.
Mesleklere göre gelir durumu:
maasDF2.stat.crosstab("occupation","salary").show()
+------------------+------+-----+
| occupation_salary| <=50K| >50K|
+------------------+------+-----+
| Armed-Forces| 8| 1|
| ?| 1652| 191|
| Sales| 2667| 983|
| Exec-managerial| 2098| 1968|
| Craft-repair| 3170| 929|
| Protective-serv| 438| 211|
| Farming-fishing| 879| 115|
| Prof-specialty| 2281| 1859|
| Machine-op-inspct| 1752| 250|
| Tech-support| 645| 283|
| Adm-clerical| 3263| 507|
| Handlers-cleaners| 1284| 86|
| Transport-moving| 1277| 320|
| Other-service| 3158| 137|
| Priv-house-serv| 148| 1|
+------------------+------+-----+
Yönetici tayfasıyla profesyonel meslek erbabı 50’yi daha çok aşmayı başarmış. Özel ev hizmetleri (neyse?) hemen hemen hepsi 5oK’nın altında kalmış garibanlar.
Gelir seviyesini gruplayalım bakalım kaç kişi 50K’nın altında kaç kişi üstünde:
val gelirGrubu = maasDF2.groupBy("salary").count()
gelirGrubu.show()
gelirGrubu: org.apache.spark.sql.DataFrame = [salary: string, count: bigint]
+------+-----+
|salary|count|
+------+-----+
| >50K| 7841|
| <=50K|24720|
+------+-----+
50K'nın altında kazananlar yaklaşık üç kat daha fazla. Buradan kabaca insanların dörtte birinin 50K üzerinde, kalan dörtte üçünün ise 50K altında gelire sahip olduğunu söyleyebiliriz. Bu oran niye önemli? Şimdi biz kimin 50K'nın üzerinde geliri olduğunu tahmin etmeye çalışıyoruz. İki tane sonuç var: 50K'dan yüksek veya değil. Şayet sallasak ve hepsine 50K'dan düşük desek zaten %75'ini doğru bileceğiz. O yüzden bizim makine öğrenmesi sonucu daha yüksek doğruluk değerlerine ulaşmamız lazım ki yaptığımız işin bir anlamı olsun. Yani bu problemde %75 doğruluk başarısı düşük bir başarı.
3. Veri Hazırlığı
Bu aşamada veri temizliği, etiket indeksleme (label indexing) ve kategorik nitelikler için string indeksleme (string indexing), oneHot Encoding.
3.1. Veri Temizliği
Veri seti içinde null değer var mı bakalım, varsa o satırı komple çıkaralım. Aslında bu basit ancak bazen yanlış bir çözüm olabilir. Burada konumuz eksik değerleri tamamlamak olmadığı için ben temizlik adı altında sadece null veya aykırı değerleri bulup ilgili satırı çıkaracağım.
3.2. Null Değer İçeren Nitelikleri Bulma
Sanırım dataframe içindeki null değer içeren sütunları bulan hazır bir fonksiyon yok. Varsa da ben bilmiyorum. Hal böyle olunca iş başa düştü ve ben de basit bir programlama ile null içeren sütunları bulayım dedim. Şöyle yapmayı düşünüyorum.
- Dataframe sütun isimlerini nitelikler isminde bir listeye aktar.
- sayac adında bir değişken belirle ve başlangç değeri olarak 1 ata.
- Liste içinde for döngüsü ile dolaş.
- Dolaşırken her bir sütun null içeriyor mu kontrol et ve say. Sayının sıfırdan büyük olup olmadığını if ile kontrol et.
- Eğer null varsa sayı sıfırdan büyüktür yani ilgili sütun null içeriyordur.
- Sütun ismini ve nul içerip içermediğini yazdır.
Nitelikleri listeye aktarma:
var nitelikler = maasDF2.columns nitelikler: Array[String] = Array(age, workclass, fnlwgt, education, education-num, marital-status, occupation, relationship, race, sex, capital-gain, capital-loss, hours-per-week, native-country, salary)
Sayac ve for döngüsü:Nitelikler listei içini nitelik ile dolaşıyoruz. Her turda ilgili niteliği isNull ile filtreleyip sayıyoruz.
var sayac = 1
for (nitelik <= nitelikler){ if(maasDF2.filter(maasDF2.col(nitelik).isNull).count() > 0){
println(sayac+". "+nitelik + " içinde null değer var.")
}else{
println(sayac+". "+nitelik + " içinde null değer yok.")
}
sayac+=1
}
Yukarıdaki kodun çıktısı:
sayac: Int = 1 1. age içinde null değer yok. 2. workclass içinde null değer yok. 3. fnlwgt içinde null değer yok. 4. education içinde null değer yok. 5. education-num içinde null değer yok. 6. marital-status içinde null değer yok. 7. occupation içinde null değer yok. 8. relationship içinde null değer yok. 9. race içinde null değer yok. 10. sex içinde null değer yok. 11. capital-gain içinde null değer yok. 12. capital-loss içinde null değer yok. 13. hours-per-week içinde null değer yok. 14. native-country içinde null değer yok. 15. salary içinde null değer yok.
Gördüğümüz gibi yukarıdaki 14 nitelik ve bir hedef nitelik olmak üzere toplam 15 sütunun hiçbirinde null değer yok.
Soru işareti olan değerleri bulma:
Buradada yukarıda null değere benzer bir süreci takip ediyoruz.
var sayac = 1
for (nitelik <= nitelikler){ if(maasDF2.filter(maasDF2.col(nitelik).contains("?")).count() > 0){
println(sayac+". "+nitelik + " içinde ? var.")
}else{
println(sayac+". "+nitelik + " içinde ? yok.")
}
sayac+=1
}
Yukarıdaki kodun çıktısı:
sayac: Int = 1 1. age içinde ? yok. 2. workclass içinde ? var. 3. fnlwgt içinde ? yok. 4. education içinde ? yok. 5. education-num içinde ? yok. 6. marital-status içinde ? yok. 7. occupation içinde ? var. 8. relationship içinde ? yok. 9. race içinde ? yok. 10. sex içinde ? yok. 11. capital-gain içinde ? yok. 12. capital-loss içinde ? yok. 13. hours-per-week içinde ? yok. 14. native-country içinde ? var. 15. salary içinde ? yok.
Null değerlerin aksine bilinmeyen anlamına gelen ? bazı sütunlarda var. ? içeren nitelikler: workclass, occupation ve native-country. Şimdi ? işareti olan satırları dataframe dışı bırakalım. Bunun için de filter kullanacağız. Ancak bu sefer filter önüne not koyacağız ve içeriğin tersini filtreleyecek yani ? bulunmayanları süzecek.
val maasDF3 = maasDF2.filter(not($"workclass".contains("?"))).filter(not($"occupation".contains("?"))).filter(not($"native-country".contains("?")))
Elde ettiğimiz ?'den arındırılmış yeni dataframe'i saydıralım:
maasDF3.count() res122: Long = 30162
Yazı başında veri setini saydırmıştık ve sonuç 32561 çıkmıştı. Yeni dataframe sayısı 30162, demekki 2399 satırda ? varmış.
3.3. Hedef Değişken Indeksleme (Label Indexing)
Hedef değişkenimizde iki farklı değer var; ">50K" ve "<=50K". Bunun için StringIndexer kullanacağız. StringIndexer bu iki niteliği sayacak ve en çok tekrarlanana 0 diğerine 1 verecek. Bu durumda "<=50K" 1, ">50K" 0 olacak. Çünkü ilkinin tekrar sayısı daha yüksek. Hadi kodlamaya başlayalım:
spark.ml.feature.StringIndexer sınıfını indirmemiz gerekir:import org.apache.spark.ml.feature.StringIndexer
Bu sınıftan bir nesne yaratalım ve adına labelIndexer diyelim: val labelIndexer = new StringIndexer() Daha sonra bu nesnenin metodlarını kullanarak input ve output sütun isimlerini belirleyelim: labelIndexer.setInputCol("salary") ve labelIndexer.setOutputCol("salary_index"). Şimdide labelIndexer nesnesinin fit() metodu ile maasDF3 dataframe salary niteliğine uyumlandıralım (İşin özü aslında "<=50K" 1, ">50K" 0 yapmak).
val labelIndexerTransformer = labelIndexer.fit(maasDF3)
labelIndexer.fit(maasDF3) ile modeli eğitip yeni bir değişkene atıyoruz: labelIndexerTransformer ve bununla da maasDF'ü dönüştürüyor ve maasDF3Transformed adında yeni bir dataframe'e atıyoruz.
val maasDF3Transformed = labelIndexerTransformer.transform(maasDF3)
maasDF3Transformed.select("salary","salary_index").show()
maasDF3Transformed: org.apache.spark.sql.DataFrame = [age: int, workclass: string ... 14 more fields]
+------+------------+
|salary|salary_index|
+------+------------+
| <=50K| 0.0|
| <=50K| 0.0|
| <=50K| 0.0|
| <=50K| 0.0|
| <=50K| 0.0| | >50K| 1.0|
| >50K| 1.0|
| >50K| 1.0|
| <=50K| 0.0|
| <=50K| 0.0|
| <=50K| 0.0|
| <=50K| 0.0|
+------+------------+
only showing top 20 rows
Belediğimiz gibi "<=50K" 1.0, ">50K" 0.0 olmuş.
3.4. Kategorik Nitelik Ön İşleme: StringIndexer ve OneHotEncoder
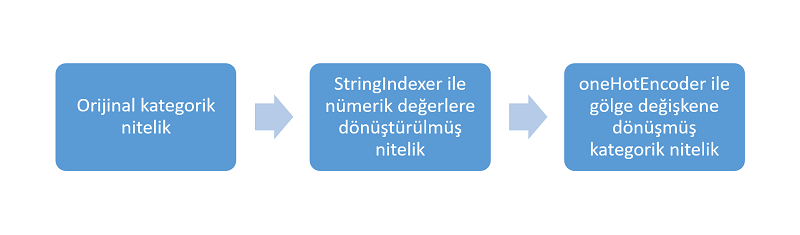
Elimizdeki veri setinde toplam 14 nitelik var. Bunlardan bazıları nümerik bazıları ise kategorik. Genel olarak makine öğrenmesi algoritmaları kategorik niteliklerden hoşlanmazlar, bunun yerine nümerik nitelik ile çalışmayı severler. Bu veri setinde kategorik nitelikler; workclass, education, maritial_status, occupation, relationship, race, sex ve native-country. Bir kategorik nitelik için işlem yapalım, bu en baştaki workclass olsun, yani özel sektörde mi, kamu da mı yoksa kendi işinde mi çalıştığı bilgilerini içeren nitelik. Bu sefer kodları tek seferde yazıp açıklamaya çalışacağım.
import org.apache.spark.ml.feature.{OneHotEncoder, StringIndexer}
val stringIndexer = new StringIndexer()
stringIndexer.setInputCol("workclass")
stringIndexer.setOutputCol("workclass_index")
val stringIndexerTransformer = stringIndexer.fit(maasDF3)
println(s" Labels for work_class are ${stringIndexerTransformer.labels.toList} ")
val maasDF3Indexed = stringIndexerTransformer.transform(maasDF3)
// Çıktılar
import org.apache.spark.ml.feature.{OneHotEncoder, StringIndexer}
stringIndexer: org.apache.spark.ml.feature.StringIndexer = strIdx_f480617eb53e
res36: stringIndexer.type = strIdx_f480617eb53e
res37: stringIndexer.type = strIdx_f480617eb53e
stringIndexerTransformer: org.apache.spark.ml.feature.StringIndexerModel = strIdx_f480617eb53e
Labels for work_class are List( Private, Self-emp-not-inc, Local-gov, State-gov, Self-emp-inc, Federal-gov, Without-pay)
maasDF3Indexed: org.apache.spark.sql.DataFrame = [age: int, workclass: string ... 14 more fields]
Kütüphaneyi indirdik ve takip eden üç satırda yeni bir StringIndexer nesnesi oluşturduk ve girdi, çıktı sütun isimlerini belirledik. Beşinci satırda stringIndexer nesnesinin fit() metodu ile modelimizi eğittik ve maasDF3Indexed değişkenine atadık. Bu arada fit() metoduna parametre olarak en güncel dafaframe olan maasDF3'ü veriyoruz. Dataframe'ler immutable olduğundan her değişiklikte farklı bir isim ile tutmak zorundayız. Biraz kafa karıştırıcı olabilir ancak buna alışmak lazım. Altıncı satırda workclass niteliğindeki benzersiz değerler liste halinde yazdırılıyor (bilgi amaçlı). Son satırda stringIndexerTransformer nesnesi transform() metoduyla workclass_index adında yeni bir sütun eklenmiş yeni dataframe oluşturup maasDF3Indexed adı altında tutuyoruz.
Şimdi oneHotEncoder ile yukarıda oluşturduğumuz workclass_index niteliğini işleyelim.
val oneHotEncoder = new OneHotEncoder()
oneHotEncoder.setInputCol("workclass_index")
oneHotEncoder.setOutputCol("workclass_onehotindex")
val oneHotEncodedDF = oneHotEncoder.transform(maasDF3Indexed)
oneHotEncodedDF.select("workclass","workclass_index","workclass_onehotindex").show(truncate = false)
//Çıktılar
import org.apache.spark.ml.feature.{OneHotEncoder, StringIndexer}
oneHotEncoder: org.apache.spark.ml.feature.OneHotEncoder = oneHot_4c6798d674c9
res29: oneHotEncoder.type = oneHot_4c6798d674c9
res30: oneHotEncoder.type = oneHot_4c6798d674c9
oneHotEncodedDF: org.apache.spark.sql.DataFrame = [age: int, workclass: string ... 15 more fields]
+-----------------+---------------+---------------------+
|workclass |workclass_index|workclass_onehotindex|
+-----------------+---------------+---------------------+
| State-gov |3.0 |(6,[3],[1.0]) |
| Self-emp-not-inc|1.0 |(6,[1],[1.0]) |
| Private |0.0 |(6,[0],[1.0]) |
| Private |0.0 |(6,[0],[1.0]) |
| Private |0.0 |(6,[0],[1.0]) |
| Private |0.0 |(6,[0],[1.0]) |
| Private |0.0 |(6,[0],[1.0]) |
| Self-emp-not-inc|1.0 |(6,[1],[1.0]) |
| Private |0.0 |(6,[0],[1.0]) |
| Private |0.0 |(6,[0],[1.0]) |
| Private |0.0 |(6,[0],[1.0]) |
| State-gov |3.0 |(6,[3],[1.0]) |
| Private |0.0 |(6,[0],[1.0]) |
| Private |0.0 |(6,[0],[1.0]) |
| Private |0.0 |(6,[0],[1.0]) |
| Self-emp-not-inc|1.0 |(6,[1],[1.0]) |
| Private |0.0 |(6,[0],[1.0]) |
| Private |0.0 |(6,[0],[1.0]) |
| Self-emp-not-inc|1.0 |(6,[1],[1.0]) |
| Private |0.0 |(6,[0],[1.0]) |
+-----------------+---------------+---------------------+
only showing top 20 rows
İlk satırda OneHotEncoder nesnesi oluşturduk. İkinci ve üçüncü satırda girdi ve çıktı için nitelik adı belirledik. Üçüncü satırda oneHotEncoder nesnesi transform() metoduna son dataframe olan maasDF3Indexed'i parametre verdik. Dönüştürme sonunda yeni bir nitelik daha eklendiğinden yeni dataframe'i oneHotEncodedDF adıyla tuttuk. Son satırda üzerinde işlem yapıyor olduğumuz workclass niteliği orjinal sütun, stringIndexer ve OneHotEncoder ile dönüştürülmüş sütünları seçip show() ile görüyoruz. Yukarıdaki şekil ile anlatılmak isteneni burada liste halinde görebiliyoruz.
3.5. Vector Assembler
Spark ML kütüphanesi girdi olarak tüm nitelikleri bir sütun altında vektör türünde ister. Nasıl olur bu peki, formatı nedir? Bunu az önce son olarak oluşan oneHotEncodedDF üzerinden basitçe anlatalım. oneHotEncodedDF içinden workclass sütunu ile ilgili dönüşümü gösteren tüm yeni sütunları seçip göstermiştik.
Bu dönüşüm nasıl oldu ve en son niteliğin formatı hakkında konuşalım.
1. StringIndexer sınıfı ile workclass kategorik niteliğini aşağıdaki şekilde görülen rakamlarla eşleştirdik.
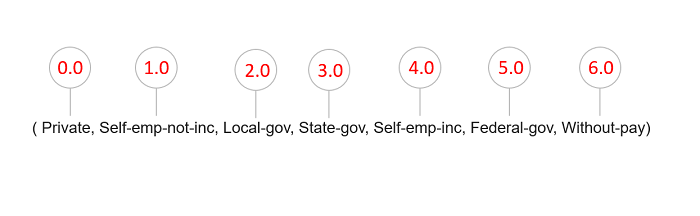
Aşağıda bir satırdan workclass ile ilgili dönüşüme uğramış üç sütunu görüyoruz. Yukarıdaki eşleşmede State-gov'un 3.0 ile eşleştiğini göstermiştik. Aşağıda ise workclass_index niteliğinde bu değeri görüyoruz. workclass_onehotindex sütunu ise vector ve workclass sütununu içindeki State-gov değerini rakamlarla gösteriyor.
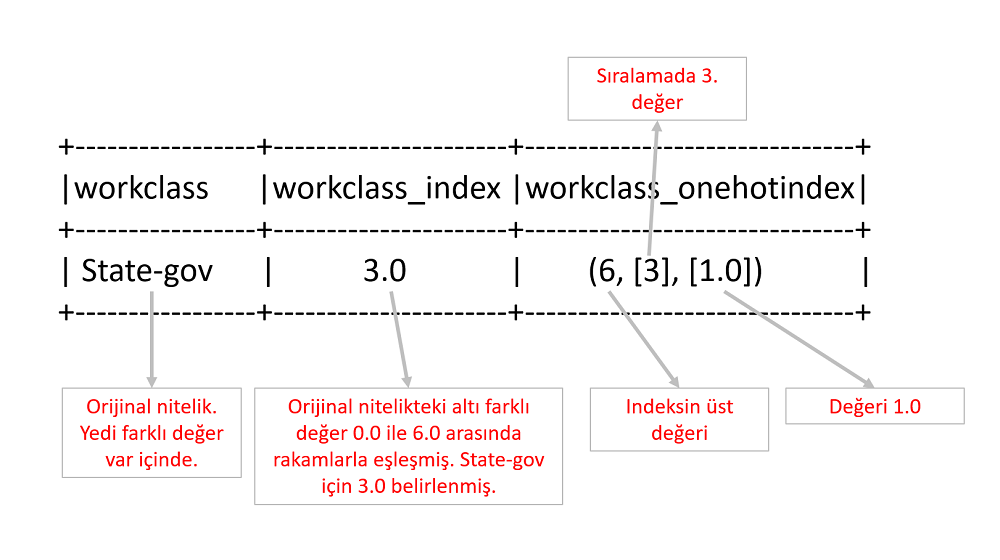
Şema yazdırarak workclass_onehotindex niteliğinin türünün vector olduğunu görelim.
oneHotEncodedDF.select("workclass","workclass_index","workclass_onehotindex").printSchema()
root
|-- workclass: string (nullable = true)
|-- workclass_index: double (nullable = true)
|-- workclass_onehotindex: vector (nullable = true)Gördüğümüz gibi workclass_onehotindex sütununun türü vector.
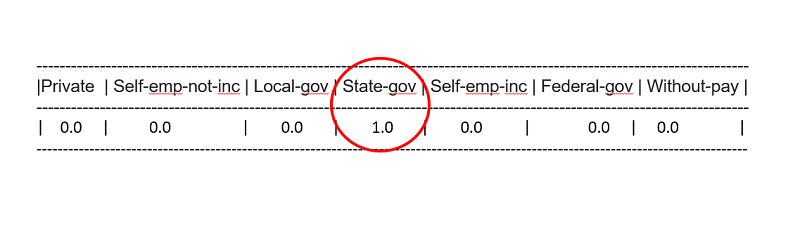
Şayet bu işi normal niteliklerle yapsaydık aşağıdaki şekle benzer yedi tane daha ilave nitelik (workclass'daki farklı değer sayısınca) koyacak ve her bir satırda sadece biri 1.0 olacak diğerleri ise 0.0 olacaktı. Yani seyrek matris oluşturmak zorunda kalacaktık. İşte vector türü tüm nitelikleri rakamlarla ve tek bir sütun içinde ifade etmemize olanak sağlıyor. one hot denmesinin sebebi de sadece bir tanesinin sıcak olması yani 1.0 değeri almasıdır.
4. Parçaları Pipeline ile Birleştirmek
Tüm kategorik nitelikleri dönüştürmek, bu arada yeni dataframe'in hangisi olduğunu takip etmek, oluşan yeni nitelikler hangisi isimleri neydi, eskilere ne oldu vb. işleri takip etmek gerçekten süreci karmaşık hale getiriyor. Pipeline ise bu noktada imdada yetişerek işleri kolaylaştırıyor. Veri seti yükleme ve temizliği ile ilgili fonksiyonlar aşağıdadır.
import org.apache.spark.ml.{Pipeline, PipelineStage}
import org.apache.spark.ml.feature.{OneHotEncoder, StringIndexer, VectorAssembler}
import org.apache.spark.sql.{DataFrame}
// Eğitim ve test dosyalarının HDFS adresleri
val filePathTrain = "/user/erkan/veri_setlerim/adult/adult.data"
val filePathTest = "/user/erkan/veri_setlerim/adult/adult.test"
// Orijinal veri seti nitelik/sütun isimleri
val initialFeatureNames = Seq("age", "workclass","fnlwgt","education",
"education_num","marital_status","occupation",
"relationship","race","sex","capital_gain",
"capital_loss","hours_per_week","native_country","salary")
def cleanDataFrame(df:DataFrame):DataFrame = {
val listOfColumns = List("workclass","occupation","native_country")
val pattern ="?"
val cleanedDF = listOfColumns.foldRight(df)((columnName,df) => {
df.filter(s"trim(${columnName})" + " <> '" + pattern +"'")
})
cleanedDF
}
// csv formatındaki veri setini yüklemek için fonksiyon. Dosya yolunu parametre alır ve dataframe döndürür.
// Bu arada veri yüklerken cleanDataFrame() fonksiyonunu çağırarak içinde ? işareti olan satırları veri setinden çıkarır.
def loadCsvData(path:String):DataFrame = {
cleanDataFrame(spark.read
.option("inferSchema","true")
.csv(path).toDF(initialFeatureNames:_*))
}
Şimdi sıra kategorik nitelikleri vector türüne dönüştürme işlemleri
// Kategorik nitelik için sütun ismi alır ve StringIndexer ve oneHotEncoder oluşan bir Array döndürür
def buildOneHotPipeLine(colName:String):Array[PipelineStage] = {
val stringIndexer = new StringIndexer()
.setInputCol(s"$colName")
.setOutputCol(s"${colName}_index")
val oneHotEncoder = new OneHotEncoder()
.setInputCol(s"${colName}_index")
.setOutputCol(s"${colName}_onehotindex")
Array(stringIndexer,oneHotEncoder)
}
// Yukarıdaki buildOneHotPipeLine() fonksiyonunu kullanarak tüm kategorik nitelikleri dönüştürür ve sonuçları bir Array içinde birleştirerek döndürür.
def buildPipeLineForFeaturePreparation():Array[PipelineStage] = {
val workClassPipeLineStages = buildOneHotPipeLine("workclass")
val educationPipelineStages = buildOneHotPipeLine("education")
val occupationPipelineStages = buildOneHotPipeLine("occupation")
val martialSatusStages = buildOneHotPipeLine("marital_status")
val relationshipStages = buildOneHotPipeLine("relationship")
val sexStages = buildOneHotPipeLine("sex")
Array.concat(workClassPipeLineStages,educationPipelineStages,martialSatusStages,
occupationPipelineStages,relationshipStages,sexStages)
}
// Yukarıdaki buildPipeLineForFeaturePreparation() fonksiyonu ile bütün kategorik niteliklerin dönüştürülmüş nesne ve sütun isimlerinin bulunduğu Array'i bir değişkene atar
// VectorAssembler nesnesi oluşturur ve özelliklerini atar.
def buildDataPrepPipeLine():Array[PipelineStage] = {
val pipelineStagesforFeatures = buildPipeLineForFeaturePreparation()
// VectorAssembler nesnesi oluştur ve vector türüne dönmüş kategorik niteliklerle zaten nümerik olan
// nitelikleri vector türünde features ismi altında tek sütunda toplayacak nesne.
val assembler = new VectorAssembler()
.setInputCols(Array("workclass_onehotindex", "occupation_onehotindex", "relationship_onehotindex",
"marital_status_onehotindex","sex_onehotindex","age","education_num","hours_per_week"))
.setOutputCol("features")
// Hedef değişkeni indeksleyerek 0 ve 1 yapar. Gerçek değerler küçük 50 büyük 50 idi.
val labelIndexer = new StringIndexer()
labelIndexer.setInputCol("salary")
labelIndexer.setOutputCol("label")
// Hepsini bir pipeline altında topla
val pipelineStagesWithAssembler = pipelineStagesforFeatures.toList ::: List(assembler,labelIndexer)
// Olşturulan pipeline Array'e çevrilerek döndürülür.
pipelineStagesWithAssembler.toArray
}
Lojistik Regresyon modelini oluşturup eğitelim, test edelim ve değerlendirelim:
import org.apache.spark.ml.Pipeline
import org.apache.spark.ml.classification.LogisticRegression
import org.apache.spark.ml.evaluation.BinaryClassificationEvaluator
import org.apache.spark.ml.param.ParamMap
// Lojistik Regresyon modelini oluşturan ve eğiten fonksiyon. Birşey döndürmez, parametre almaz.
def lRTraining() {
// Yukarıda hazırladığımız fonksiyon ile veri setini yükleyip salaryDF ile tutuyoruz.
val trainDF = loadCsvData(filePathTrain)
val testDF = loadCsvData(filePathTest)
//Tüm pipeline safhaları Array halinde (şimdiye kadar hazırlanan tüm nesneler burada) bir değişkenle tutuluyor.
val pipelineStagesWithAssembler = buildDataPrepPipeLine()
// Array'ı kullanarak Pipeline nesnesi oluştur
val pipeline = new Pipeline().setStages(pipelineStagesWithAssembler)
// pipeline nesnesine ham dataframe'i verelim sonuç olarak bize lojistik regresyon modeline sokacak yeni dataframe döndürsün
val featurisedDFTrain = pipeline.fit(trainDF).transform(trainDF)
val featurisedDFTest = pipeline.fit(testDF).transform(testDF)
// Boş lojistik regresyon modeli oluştur ve iki parametresini ata.
val lr = new LogisticRegression()
.setMaxIter(10)
.setRegParam(0.01)
// Eğitim verisi ile boş modeli eğitelim
val model = lr.fit(featurisedDFTrain)
//Eğitilen modele test verisini sunalım bakalım tahmin yapsın.
val testPredictions = model.transform(featurisedDFTest)
// Aynı tahmini eğitildiği veri setiyle de yapsın. bakalım belki aşırı öğrenme vardır.
val trainingPredictions = model.transform(featurisedDFTrain)
// Area under ROC as a metriğiyle modeli değerlendirelim
val evaluator = new BinaryClassificationEvaluator()
val evaluatorParamMap = ParamMap(evaluator.metricName -> "areaUnderROC")
val aucTraining = evaluator.evaluate(trainingPredictions, evaluatorParamMap)
println("AUC Training: " + aucTraining)
val aucTest = evaluator.evaluate(testPredictions, evaluatorParamMap)
println("AUC Test: " + aucTest)
}
// Çıktılar
AUC Training: 0.879454096554986
AUC Test: 0.8695312737913873
Türkçe için güzel bir kaynak olmuş.
Merhaba,
AUC tam olarak ne oluyor. Örneğin ben tek bir satır veri göndermek istiyorum. Bu eğitilmiş veriye bakarak workclass’ nı belirlemek istiyorum. Cevap verirseniz müteşşekkir olurum.
Selam AUC Area Under Curve demek. Model performans ölçümü için bir kriter. Bu değer ne kadar büyükse model o kadar başarılı sınıflandırma yapıyor anlamına gelir. Sınıf tahmini için eğitilmiş modelde yeni veri setini predict edeceksiniz. Bunu zaten test verisi ile yapıyoruz. Aynı şekilde yapabilirsiniz.