

![]()
Active Learning Sampling Stratejileri ve Query Yöntemleri
Birinci bölümde etiketleme süreci üzerine odaklanmıştık. Bu bölümde etiketleyicinin, etiketleyeceği verileri ortaya çıkaran yöntemler üzerine gidilecek. Etiketlenecek görseller üzerinde çeşitliliğe dayanan, belirsizliğe dayanan veya hibrit kullanımlara dayanan stratijler bulunmaktadır. 3 başlık üzerinden yöntemleri inceleyeceğiz. Bu 3 başlığın altında bahsedilen yöntemlerle birlikte bahsedilmeyen birçok yöntem daha mevcuttur.
1) Uncertainty Sampling
Belirsizliğe dayalı bir hesaplama yaklaşımıdır. Modeli tahmin olasılıkları üzerinden belirsizliğin hesaplanması için farklı yaklaşımlar bulunmaktadır.
A) Least Confidence
%100 güvenilirlik ile sınıflara yapılan tahminler arasından en güvenilir (confident) olanın farkı hesaplanır. Yukarıdaki tablo görsele bakıldığında, X1 için 1-(0.9) değerindedir. X2 içinse 1-(0.87) değerindedir. Diğer hesaplama çalışmaları için de örnek Görsel-3’deki tablo takip edilebilir.
![]()
B) Margin Confidence
Görsele dair en yüksek tahmin değerini taşıyan 2 sınıfın tahmin değerleri birbirinden çıkarılır.
![]()
C) Entropy
En yüksek düzensizliği arar.
![]()
2) Diversity Sampling
Çeşitliliğe dayalı bir yaklaşımdır. Örneklerin dağılımı, yoğunluğu ve temsilciliği gibi özellikler göz önünde bulundurulur.
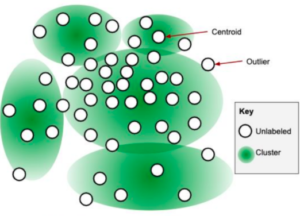
Görsel-1 Cluster-based Sampling [1]
Küme bazlı bir örnekleme yöntemi seçilmiştir. Farklı özelliklerden örnekler seçmek için küme ayrışımları ve aykırı değerler ortaya çıkarılmıştır. Bu ayrışımlar sayesinde çeşitlilik karakterize edilmiştir ve üzerinden seçimler yapılabilir.
3) Uncertainty & Diversity Sampling
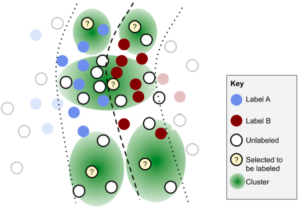
Görsel-2 Uncertainty & Diversity Sampling [2]
Farklı kümelerden örnekler ile çeşitliliğe dayanan ve sınır üzerindeki örneğin seçimiyle de belirsizliğe dayanan örnek seçimi yapılmış ve hibrit bir yaklaşım elde edilmiştir.

Görsel-3: 3 Yaklaşımın Uygulanışı Üzerine Bir Örnek [3]
Etiketlenecek Verileri İşleme Alma Yaklaşımları
Sorgu yöntemleriyle birlikte etiketlenecek verilerin nasıl işleme alınacağı konusunda 2 tip yaklaşım vardır.
1) Pool-based
Sorgu yöntemi depolanan bir veri kümesi üzerine uygulanır ve seçimler yapılır.
2) Streaming-based
Sorgu yöntemi akıştan gelen veriler üzerine uygulanır.
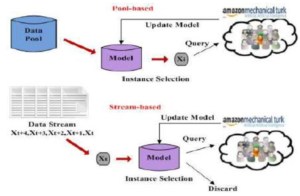
Görsel-4 Pool-based ve Streaming-based Active Learning [4]
NOTLAR
Uncertainty Sampling yöntemi ile adım adım bir örnek üzerinden ilerlemek için [5] linkindeki video’nun 20.06 sonrasını takip edebilirsiniz.
Algoritmaları kod ile pratize etmek yapmak faydalı olabilir. İlgili Cloud ürünleri için AWS MechanicalTurk, Google Vertex AI örnek verilebilir. Python dilinde birçok açık kaynaklı kütüphane de mevcuttur. Bu hizmeti sunan çeşitli firmalar ve ürünleri de incelenebilir.
SONUÇ
Birinci bölümde Active Learning ve Veri Etiketlemedeki Rolü’nün süreci üzerine odaklanılırken bu bölümdeyse yöntemler ve hesaplanabilirlikleri değerlendirilmiştir.
KAYNAKLAR
[1] https://robertmunro.com/Diversity_Sampling_Cheatsheet.pdf
[2] https://livebook.manning.com/book/human-in-the-loop-machine-learning/chapter-5/v-5/
[3] https://livebook.manning.com/book/human-in-the-loop-machine-learning/chapter-1/v-11/
[4] https://www.researchgate.net/figure/Stream-based-active-learning-vs-pool-based-active-learning_fig1_259237240
[5] https://www.youtube.com/watch?v=_EbpQiMoXvQ&ab_channel=BilkentCYBERPARK