

![]()
Merhabalar bu yazımızda Python Pandas ile pratik bilgiler ve komutları paylaşıyor olacağım.
- Pandas dataframe tarih (date) filtreleme
- Dataframe içinde takrarlanan sütunları elde etmek
- Bir sütunda birden fazla değer içinde arayarak filtrelemek: where a_column in ()
- Pandas ile zip dosyasından veri okumak
- Python Pandas head Sütun Truncate Önleme – pandas truncate column
- Pandas dataframe sütunlarını tek bir sütun içinde virgülle ayrılmış olarak toplamak
- Pandas dataframe içinde for döngüsü ile dolaşmak – for loop in pandas dataframe
- Pandas dataframe bir sütun içindeki en uzun string – Find length of longest string in Pandas dataframe column
- Pandas ile iki tarih aralığında zaman değeri üretmek
- Pandas dataframe bazı sütunları hariç tutarak seçmek – exclude columns
- Pandas dataframe s3 üzerindeki dosyaların adını nasıl değiştiririz? rename s3 keys
- Python ile zip dosyasını indirip açmak
1. Pandas dataframe tarih (date) filtreleme
Pandas tarihe dayalı filtrelemeler diğer veri türlerinden biraz farklı. Örneğin tarih (date) içeren bir sütunu ekrana bastırdığınızda gördüğünüz bir string gibi ancak bunu kullanarak çeşitli filtrelemeler yapmak istediğinizde hata alıyorsunuz.
df[['date']].head()
| date | |
|---|---|
| 0 | 2019-11-05 |
| 1 | 2019-11-05 |
| 2 | 2019-11-05 |
| 3 | 2019-11-05 |
| 4 | 2019-11-05 |
Diyelim ki 2019-11-05 tarihine eşit olan satırları filtrelemek istiyoruz. İlk aklınıza gelen kod herhalde aşağıdaki olurdu. Ancak bu iş görmeyecektir.
df.loc[df['date'] == '2019-11-05'].head()

Şekil-1’de gördüğümüz gibi sonuç boş. Niçin? Çünkü df[‘date’] sütununda ‘2019-11-05’ değeri yok. Var gibi duruyor ama yok. Çözüm:
df.loc[df['date'] == pd.to_datetime("2019-11-05"), :].head()2. Dataframe içinde takrarlanan sütunları elde etmek
duplicate_rows_df = df[ df.duplicated() ] duplicate_rows_df.head()
3. Bir sütunda birden fazla değer içinde arayarak filtrelemek: where a_column in ()
Aşağıda örneği bulunan filitrelemede şehir sütununda ‘Ankara’,’Bursa’,’Çankırı’ şehirleri filitrelenecektir.
(df['sehir'].isin(['Ankara','Bursa','Çankırı']))
4. Pandas ile zip dosyasından veri okumak
Normal csv dosyası okumaktan hiçbir farkı yok.
import pandas as pd
df = pd.read_csv("/file/to/filename.zip")5. Python Pandas head Sütun Truncate Önleme – pandas truncate column
Pandas; Python dilinde veri manipülasyonu, keşfi ve ön hazırlığı konusunda oldukça popüle bir kütüphanedir. Pandas ile okunan veri setinden sonra genellikle df.head() metodu ile veriye genel bir bakış atarız. Ancak bazı sütun içeriği geniş olduğundan sütun içine sığmaz ve hepsini göremeyiz, kırpılır, özellikle de Jupyter Notebook’ta. Sütun içini kırpmadan hepsini görmek istiyorsak aşağıdaki komutu çalıştırmalıyız:
pd.set_option('display.max_colwidth', None)Örnek:
import pandas as pd
my_dict = {'sno':[1,2],
'aciklama': ['Lorem Ipsum, dizgi ve baskı endüstrisinde kullanılan mıgır metinlerdir.',
'Lorem Ipsum']}
df = pd.DataFrame(my_dict)
df.head()| sno | aciklama | |
|---|---|---|
| 0 | 1 | Lorem Ipsum, dizgi ve baskı endüstrisinde kullanılan mıgır metinlerdir. |
| 1 | 2 | Lorem Ipsum |
Pandas dataframe tüm sütunları seç – göster (select all columns)
# Show all columns
pd.set_option("display.max_columns", None)6. Pandas dataframe sütunlarını tek bir sütun içinde virgülle ayrılmış olarak toplamak
Kafka’ya pandas dataframe sütunlarını mesaj olarak göndermek istediğimde karşıma çıktı. Epey uğraştım. Çözümü paylaşıyorum.
import pandas as pd
df = pd.read_csv("D:/Datasets/iris.csv")
# Her bir satırı sütunları virgülle ayrılmış şekilde bir listenin elemanları yapalım
x = df.to_string(header=False,
index=False,
index_names=False).split('\n')
vals = [','.join(ele.split()) for ele in x]
# Elde ettiğimiz listeyi dataframe'e value sütunü olarak takalım
df['value'] = vals
# Sonucu görelim
df.head()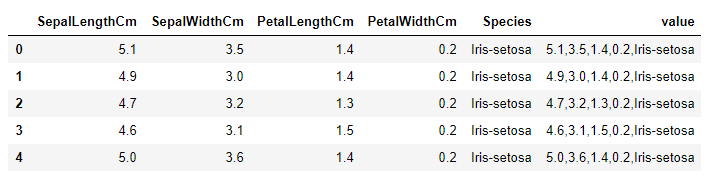
7. Pandas dataframe içinde for döngüsü ile dolaşmak – for loop in pandas dataframe
İçinde dolaşacağımız örnek dataframe:

Bir pandas dataframe içinde dolaşmak için dataframe’e ait .iterrows() metodunu kullanabiliriz. iterrows() iki iterasyon değişkeni kullanarak dataframe’in her bir satırında dolaşır. Birincisi index diğeri ise payload diyeceğimiz asıl veriyi oluşturan kısımdır. Eğer veri kısmında belirgin bir sütun üzerinde işlem yapmak istiyorsak satır indeksi ile o sütuna erişebiliriz.
stopper = 0
interval = []
for index, line in runorwalk.iterrows():
print(index, line)
stopper += 1
if stopper >= 2:
breakYukarıda stopper falan kullanmamızın nedeni 2 satır dolaşıp for içinden çıkmaktır. Yukarıdaki kodun çıktısı şu şekilde olacaktır:
0 date 2017-6-30 time 13:51:15:847724020 username viktor wrist 0 activity 0 acceleration_x 0.265 acceleration_y -0.7814 acceleration_z -0.0076 gyro_x -0.059 gyro_y 0.0325 gyro_z -2.9296 Name: 0, dtype: object 1 date 2017-6-30 time 13:51:16:246945023 username viktor wrist 0 activity 0 acceleration_x 0.6722 acceleration_y -1.1233 acceleration_z -0.2344 gyro_x -0.1757 gyro_y 0.0208 gyro_z 0.1269 Name: 1, dtype: object
Eğer örneğin sadece gyro_z sütununu görmek vaya bunun üzerinde birşey yapmak istersem kodumda küçük bir değişiklik yaparak bunu başarabiliriz. line[-1] yazmamız fazlasıyla yeterli olacaktır. Komut ve çıktısı aşağıdaki gibidir.
stopper = 0
interval = []
for index, line in runorwalk.iterrows():
print(index, line[-1])
stopper += 1
if stopper >= 2:
break
Çıktı:
0 -2.9296
1 0.12698. Pandas dataframe bir sütun içindeki en uzun string – Find length of longest string in Pandas dataframe column
df.col1.str.len().max()
9. Pandas ile iki tarih aralığında zaman değeri üretmek
Belli bir zaman aralığındaki saatler, günler, saniyelerin listesini mi elde etmek istiyorsunuz. date_range() size göre. Aşağıda iki tarih arasındaki saatleri yyyymmddHH formatında üreten kodları göreceksiniz.
import pandas as pd
hours_list = pd.date_range(start='2021/07/13', end='2021/8/19', freq='H').strftime("%Y%m%d%H").tolist()10. Pandas dataframe bazı sütunları hariç tutarak seçmek – exclude columns
df.loc[:, ~df.columns.isin(['col1', 'col2', ...])]
11. Pandas dataframe s3 üzerindeki dosyaların adını nasıl değiştiririz? rename s3 keys
Diyelim ki S3’de bulunan dosyalarınızın adını değiştirmek istiyorsunuz ne yaparsınız? Aşağıdaki örnekte Pandas ve boto3 ile bunun ne kadar kolay olacağınız göreceksiniz. Bir sütuna eski key (s3 dosya adresi) bir sütuna da yeni key koydunuz mu aşağıdaki fonksiyon işinizi tıkır tıkır görecektir.
# change keys
def change_s3_keys(df, bucket, old_key, new_key):
for index, row in df[[old_key, new_key]].iterrows():
# Get boto3 s3 resource
s3_res = get_s3_resource()
try:
s3_res.Object(bucket,row[new_key]).copy_from(CopySource=bucket+'/'+row[old_key])
except KeyError:
print(f'{row[old_key]} doesnt exist.')
s3_res.Object(bucket, row[old_key]).delete()
change_s3_keys(df=df_merged, bucket=bucket, old_key='webpages_s3_key', new_key='candidate_s3_key')12. Python ile zip dosyasını indirip açmak
import requests, zipfile
from io import BytesIO
import os
zip_file_url = 'https://github.com/erkansirin78/datasets/raw/master/IOT-temp.csv.zip'
r = requests.get(zip_file_url, stream=True)
z = zipfile.ZipFile(BytesIO(r.content))
z.extractall("/home/train/datasets")
print(os.listdir("/home/train/datasets"))