
Apache Spark ile LightGBM Kullanarak Sınıflandırma Yapmak
 (2 votes, average: 5,00 out of 5)
(2 votes, average: 5,00 out of 5)Merhabalar. LightGBM’in ününü duymuşsunuzdur. Ancak bunu Spark ile kullanmak istediğinizde maalesef bu algoritma Spark ML’de bulunmuyor. Bu yazımızda LightGBM’i Spark içinde nasıl kullanacağımızı PySpark ile uygulamalı olarak göreceğiz.
Bildiğimiz gibi Apache Spark büyük veri dünyasında makine öğrenmesi çalışmalarının vazgeçilmez bir aracı. Küçük veri dünyasında scikit-learn ile yaptığımız işleri büyük veri tarafında genelde Spark ile yaparız. Ancak Spark’ın makine öğrenmesi kütüphanesi küçük veri dünyasında kullanılan kütphanelere kıyasla oldukça fakir. Bu sebeple Spark’ın ML framework’ü ile uyumlu çalışabilen harici kütüphaneler geliştiriliyor. Bunlardan birisi de LightGBM. Bu yazımızda LightGBM örneğini kullanarak Spark için dışarıdan geliştirilen bir algoritma ile nasıl model geliştireceğimizi ele alacağız. LighGBM ile ilgili ilave bilgiyi yazarımız Emre Rıdvan Murat‘ın bu yazında bulabilirsiniz. LightGBM’in dokümantasyonuna da buradan erişebilirsiniz. Kullanacağımız LightGBM ise Microsoft Machine Learning for Apache Spark projesi kapsamında geliştirilmiştir.
Bu yazıda kullandığım kodlara ait ortam bilgileri şu şekildedir:
- İşletim Sistemi: Linux CentOS7
- IDE: Jupyter Notebook
- Dil: Python 3.6
- Spark: 2.4.7
- Cluster Manager: YARN (3.1.2)
- Storage: HDFS (3.1.2)
Aşağıdaki problem telekom sektöründe sık rastlanan churn prediction problemidir. Kullanılan veri setine buradan ulaşabilirsiniz. Bu yazının amacı harici bir kütüphaneyi Spark ile kullanmak olduğu için veri hazırlığı gibi detaylara fazla yer vermeyeceğim.
1. Kütüphaneler
import findspark
findspark.init("/opt/manual/spark2")
from pyspark.sql import SparkSession, functions as F
import pandas as pd2. SparkSession Oluşturma
spark = (SparkSession.builder
.appName("Churn Prediction with LightGBM on Spark")
.master("yarn")
.config("spark.memory.fraction","0.7")
.config("spark.memory.storageFraction","0.3")
.config("spark.executor.cores","2") # lightgbm requires at least 2 cores per task
.config("spark.jars.packages","com.microsoft.ml.spark:mmlspark_2.11:0.18.1")
.enableHiveSupport()
.getOrCreate())Yuarıda dikkat etmemiz gereken bazı püf noktalar var. .config("spark.executor.cores","2") bu satırda her bir executor için en az iki çekirdek olmasını sağlıyoruz. .config("spark.jars.packages","com.microsoft.ml.spark:mmlspark_2.11:0.18.1") burada ise Microsoft’un projesini SparkSession’a dahil ediyoruz. Buradaki maven koordinatlarını kendi ortamınıza uyarlayarak kullanmak zorundasınız. Bu yazı yazıldığında Spark 3 ile çalışmadığı için ben Spark2 kullanmak zorunda kaldım. Ayrıca kendi dokümanlarında belirtilen son sürüm ile hata aldığım için 0.18.1 sürümünü kullandım.
3. Veri Okuma ve Veri Keşfi
HDFS’te bulunan veri setini okuyalım.
df1 = spark.read.format("parquet") \
.load("hdfs://localhost:9000/user/train/datasets/churn-telecom/cell2celltrain_clean_parquet")Veri setine bir göz atalım. Sütun sayısı çok fazla olduğu için sadece bir kısmına bakıyoruz. Ayrıca daha güzel bir görünüm için pandas dataframe’e çevirip bakıyoruz. Buradaki püf nokta pandas’a çevirmeden önce mutlaka limit kullanmak gerektiği. Aksi halde Spark driver’a aşırı veri çağırmış oluruz ve bu driver kaynaklarını mahvedebilir.
# Since there are many columns we'd better explore part by part df1.select(df1.columns[40:]) \ .limit(5).toPandas()
Dataframe şemasına göz atalım:
root |-- CustomerID: integer (nullable = true) |-- Churn: string (nullable = true) |-- MonthlyRevenue: double (nullable = true) |-- MonthlyMinutes: double (nullable = true) |-- TotalRecurringCharge: double (nullable = true) |-- DirectorAssistedCalls: double (nullable = true) |-- OverageMinutes: double (nullable = true) |-- RoamingCalls: double (nullable = true) |-- PercChangeMinutes: double (nullable = true) |-- PercChangeRevenues: double (nullable = true) |-- DroppedCalls: double (nullable = true) |-- BlockedCalls: double (nullable = true) |-- UnansweredCalls: double (nullable = true) |-- CustomerCareCalls: double (nullable = true) |-- ThreewayCalls: double (nullable = true) |-- ReceivedCalls: double (nullable = true) |-- OutboundCalls: double (nullable = true) |-- InboundCalls: double (nullable = true) |-- PeakCallsInOut: double (nullable = true) |-- OffPeakCallsInOut: double (nullable = true) |-- DroppedBlockedCalls: double (nullable = true) |-- CallForwardingCalls: double (nullable = true) |-- CallWaitingCalls: double (nullable = true) |-- MonthsInService: float (nullable = true) |-- UniqueSubs: float (nullable = true) |-- ActiveSubs: float (nullable = true) |-- ServiceArea: string (nullable = true) |-- Handsets: float (nullable = true) |-- HandsetModels: float (nullable = true) |-- CurrentEquipmentDays: float (nullable = true) |-- AgeHH1: double (nullable = true) |-- AgeHH2: double (nullable = true) |-- ChildrenInHH: string (nullable = true) |-- HandsetRefurbished: string (nullable = true) |-- HandsetWebCapable: string (nullable = true) |-- TruckOwner: string (nullable = true) |-- RVOwner: string (nullable = true) |-- Homeownership: string (nullable = true) |-- BuysViaMailOrder: string (nullable = true) |-- RespondsToMailOffers: string (nullable = true) |-- OptOutMailings: string (nullable = true) |-- NonUSTravel: string (nullable = true) |-- OwnsComputer: string (nullable = true) |-- HasCreditCard: string (nullable = true) |-- RetentionCalls: float (nullable = true) |-- RetentionOffersAccepted: float (nullable = true) |-- NewCellphoneUser: string (nullable = true) |-- NotNewCellphoneUser: string (nullable = true) |-- ReferralsMadeBySubscriber: float (nullable = true) |-- IncomeGroup: float (nullable = true) |-- OwnsMotorcycle: string (nullable = true) |-- AdjustmentsToCreditRating: float (nullable = true) |-- HandsetPrice: double (nullable = true) |-- MadeCallToRetentionTeam: string (nullable = true) |-- CreditRating: string (nullable = true) |-- PrizmCode: string (nullable = true) |-- Occupation: string (nullable = true) |-- MaritalStatus: string (nullable = true)
Yukarıdan veri setinde ne gibi sütunlar var, veri türleri nedir bilgi edinebiliriz.
Boşluk kontrolü yapalım. Null değer taşıyan bir hücreyi modele göndermek istemeyiz. Benim bildiğim spark apisinde tek haraketle null değer içeren sütunları belirleyen bir şey yok. Bu sebeple for döngüsü ile tüm sütunları dolaşıp bakacağım.
col_name, col_type) in zip(df1.columns, df1.dtypes):
null_count = df1.filter( (F.col(col_name).isNull()) | (F.col(col_name) == "")).count()
if( null_count > 0 ):
print("{} {} type has {} null values".format(col_name, col_type[1], null_count))Eğer herhangi bir çıktı görmediysek null yok demektir.
Hedef değişken olan Churn sütununun sınıf dağılımına göz atalım:
df1.select("Churn").groupBy("Churn").count().show()
+-----+-----+
|Churn|count|
+-----+-----+
| No|36335|
| Yes|14711|
+-----+-----+Sınıf dağılımına bir de grafikle bakalım.
df1.select("Churn").groupBy("Churn").count().toPandas().plot(kind='bar')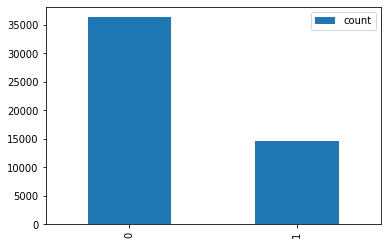
4. Modele Yönelik Veri Hazırlığı
Öncelikle nitelikleri 4 farklı gruba (python listesi) ayırıyorum. Kategorikler(1), nümerikler(2), hedef değişken(3) ve modele dahil etmeyeceklerim(4). Modele dahil olmayacakları yukarıda kısa kestiğim keşifçi veri analizi aşamasında tespit ettim.
categoric_cols = [] numeric_cols = [] discarted_cols = ['CustomerID', 'ServiceArea'] label_col = ['Churn']
Bir for döngüsünde tüm sütunları dolaşayım ve eğer bir sütun hedef değişken ve modele girmeyecekler arasında değil, aynı zamanda string türündeyse bu sütunu kategoriklere, değilse numeriklere ekleyeyim.
for col_name in df1.dtypes:
if (col_name[0] not in discarted_cols+label_col):
if (col_name[1] == 'string'):
categoric_cols.append(col_name[0])
else: numeric_cols.append(col_name[0])5. OneHotEncoder Hazırlığı
Bu aşamada odak noktam kategorikler. Bir sürü kategorik nitelik var ve bunların bir çoğu da binary. Binary olan nitelikleri sadece StringIndexer ile rakamlara kodlayacağım (1 ve 0) ikiden fazla kategoriye sahip kategorik değişkenleri ise OneHotEncoder ile işleyeceğim (gölge değişkenler). Bu işi yapan kodlar:
# Here we count the distinct categories in categoric columns. If there is more than two,
# we will add those to to_be_onehotencoded_cols list If there is just 2 we don't need to use onehotencoder
# So if distinct category gt 2 we have to add it to_be_onehotencoded_cols list
to_be_onehotencoded_cols = []
for col_name in categoric_cols:
count = df1.select(col_name).distinct().count()
if count > 2:
to_be_onehotencoded_cols.append(col_name)
print("{} has {} distinct category.".format(col_name, count))Yukarıdaki kodun çıktısı:
ChildrenInHH has 2 distinct category. HandsetRefurbished has 2 distinct category. HandsetWebCapable has 2 distinct category. TruckOwner has 2 distinct category. RVOwner has 2 distinct category. Homeownership has 2 distinct category. BuysViaMailOrder has 2 distinct category. RespondsToMailOffers has 2 distinct category. OptOutMailings has 2 distinct category. NonUSTravel has 2 distinct category. OwnsComputer has 2 distinct category. HasCreditCard has 2 distinct category. NewCellphoneUser has 2 distinct category. NotNewCellphoneUser has 2 distinct category. OwnsMotorcycle has 2 distinct category. MadeCallToRetentionTeam has 2 distinct category. CreditRating has 7 distinct category. PrizmCode has 4 distinct category. Occupation has 8 distinct category. MaritalStatus has 3 distinct category.
Şu aşamada OneHotEncoder’a girecekleri bir listede topladım. Onları bir görelim.
print(to_be_onehotencoded_cols) Çıktısı: ['CreditRating', 'PrizmCode', 'Occupation', 'MaritalStatus']
6. StringIndexer
Şimdi hem binary olan kategorikleri hem olmayanları StringIndexer ile kodlayalım. Kodların içinde gerekli açıklamarı yazıyorum.
from pyspark.ml.feature import StringIndexer
# Sözlük kullanmamızın sebebi dinamik olarak obje ve string listesini oluşturmak.
my_dict = {}
# Bu liste StringIndexer objelerini toplayacak
string_indexer_objs = []
# Bu liste StringIndexer'a girecek orijinal sütun isimlerini toplayacak (yukarıda zaten ayırdığımız tüm kategorikler)
string_indexer_output_names = []
# Hazır kategorik nitelikler üzerinde for ile dönecek iken OneHot'a girecek 4 niteliğinde input ve output sütun isimlerini toplayalım
ohe_col_input_names = []
ohe_col_output_names = []
# Tüm kategorik sütun isimlerinde dolaş.
for col_name in categoric_cols:
# StringIndexer objesi oluştur ve sözlüğe ekle
my_dict[col_name+"_indexobj"] = StringIndexer() \
.setHandleInvalid('skip') \
.setInputCol(col_name) \
.setOutputCol(col_name+"_indexed")
# Sözlüğe taktğımız StringIndexer objesini ilgili listeye ekleyelim.
string_indexer_objs.append(my_dict.get(col_name+"_indexobj"))
# Aynı şekilde StringIndexer output süteun isimlerini de listesine eleyelim.
string_indexer_output_names.append(col_name+"_indexed")
# Eğer kategorik sütun OneHotEncoder'a girecekse ilgili listelere ekle.
if col_name in to_be_onehotencoded_cols:
ohe_col_input_names.append(col_name+"_indexed")
ohe_col_output_names.append(col_name+"_ohe")Yukarıda oluşan listelere bir göz atalım kim nereye nasıl yerleşmiş?
print(string_indexer_objs) Çıktısı: [StringIndexer_ae4899dc030c, StringIndexer_821dc8bc55dc, StringIndexer_69e5c23854c4, StringIndexer_b23b81c39015, StringIndexer_3444b55815bf, StringIndexer_b1ae2ce18171, StringIndexer_87f9f2668751, StringIndexer_88cede68cf38, StringIndexer_998bb328f98e, StringIndexer_1ca7497bf55a, StringIndexer_2b69b5bef2a0, StringIndexer_96b6bb2e6e62, StringIndexer_70d958f11b02, StringIndexer_0e3b313e32bf, StringIndexer_7b2e6d29c2a6, StringIndexer_013729b2f102, StringIndexer_6b655a101463, StringIndexer_077460bf9e12, StringIndexer_f9cd2c3632dc, StringIndexer_eca13a55ada5] print(string_indexer_output_names) Çıktısı: ['ChildrenInHH_indexed', 'HandsetRefurbished_indexed', 'HandsetWebCapable_indexed', 'TruckOwner_indexed', 'RVOwner_indexed', 'Homeownership_indexed', 'BuysViaMailOrder_indexed', 'RespondsToMailOffers_indexed', 'OptOutMailings_indexed', 'NonUSTravel_indexed', 'OwnsComputer_indexed', 'HasCreditCard_indexed', 'NewCellphoneUser_indexed', 'NotNewCellphoneUser_indexed', 'OwnsMotorcycle_indexed', 'MadeCallToRetentionTeam_indexed', 'CreditRating_indexed', 'PrizmCode_indexed', 'Occupation_indexed', 'MaritalStatus_indexed'] print(ohe_col_input_names) Çıktısı: ['CreditRating_indexed', 'PrizmCode_indexed', 'Occupation_indexed', 'MaritalStatus_indexed'] print(ohe_col_output_names) Çıktısı: ['CreditRating_ohe', 'PrizmCode_ohe', 'Occupation_ohe', 'MaritalStatus_ohe']
7. OneHotEncoder
Yukarıda gerekli hazırlığı yaptığımız için burada rahatız.
from pyspark.ml.feature import OneHotEncoderEstimator encoder = OneHotEncoderEstimator() \ .setInputCols(ohe_col_input_names) \ .setOutputCols(ohe_col_output_names)
8. VectorAssembler
Şimdi tüm hazırladığımız sütunları (nümerik, stringindexed ve onehot) bir araya toplayalım (vektör haline getirme). Ancak öncesinde mükerrerliği önlemek için onehot’a girecekleri kategoriklerden çıkarmalıyız.
from pyspark.ml.feature import VectorAssembler
# Onehot'a girecekleri çıkar
string_indexer_col_names_ohe_exluded = list(set(string_indexer_output_names).difference(set(ohe_col_input_names)))
print(string_indexer_col_names_ohe_exluded)
Çıktısı:
['NonUSTravel_indexed',
'NotNewCellphoneUser_indexed',
'ChildrenInHH_indexed',
'HasCreditCard_indexed',
'MadeCallToRetentionTeam_indexed',
'RespondsToMailOffers_indexed',
'Homeownership_indexed',
'RVOwner_indexed',
'HandsetWebCapable_indexed',
'OwnsComputer_indexed',
'HandsetRefurbished_indexed',
'TruckOwner_indexed',
'OwnsMotorcycle_indexed',
'BuysViaMailOrder_indexed',
'OptOutMailings_indexed',
'NewCellphoneUser_indexed']
# Aseembler
assembler = VectorAssembler().setHandleInvalid("skip") \
.setInputCols(numeric_cols+string_indexer_col_names_ohe_exluded+ohe_col_output_names) \
.setOutputCol('unscaled_features')9. LabelIndexer
Hedef değişkenimiz Churn, string türünde olduğu için onu rakamlarla kodlamalıyız (1,0).
label_indexer = StringIndexer().setHandleInvalid("skip") \
.setInputCol(label_col[0]) \
.setOutputCol("label")10. FeatureScaling
VectorAssembler ile bir araya topladığımız nitelikleri standardize edelim.
from pyspark.ml.feature import StandardScaler
scaler = StandardScaler().setInputCol("unscaled_features").setOutputCol("scaled_features")11. PCA
Her ne kadar PCA bu aşamada tuhaf görünse ve alışkanlıklara aykırı bir kullanım olsa da hesaplama maliyetini düşürmek için buraya ekleyebiliriz. Çünkü gölge değişkenlerle beraber nitelikler matrisi (feature matrix) epey bir genişledi. Ancak yine de siz bilirsiniz. Bunu atlayabilirsiniz.
from pyspark.ml.feature import PCA
pca = PCA().setInputCol("scaled_features").setK(10).setOutputCol("features")12. LightGBM (Estimator)
Tam burada Microsoft’un hazırladığı (hem Spark’ı hem LightGBM’i hazırlayanların elleri dert görmesin) kütüphaneyi sanki Spark ML’in orijinal kütüphanesiymiş gibi import edip kullanıyoruz. Burada bu sınıfı (LightGBMClassifier) mutlaka SparkSession esnasında olaya dahil etmeliyiz. Hatırlayın (.config("spark.jars.packages","com.microsoft.ml.spark:mmlspark_2.11:0.18.1")) satırı.
from mmlspark.lightgbm import LightGBMClassifier
estimator = LightGBMClassifier(learningRate=0.3,
numIterations=200,
numLeaves=20,
featuresCol='features',
labelCol='label',
isUnbalance=True)13. Pipeline
Şimdi buraya kadar biriktirdiğimiz boncukları (objects – estimators ve transformers) bir ipe diziyoruz. Sıra önemlidir.
from pyspark.ml import Pipeline In [46]: pipeline_obj = Pipeline().setStages(string_indexer_objs+[encoder, assembler, label_indexer, scaler, pca, estimator])
15. Veri Setini Eğitim ve Test olarak Bölme
train_df, test_df = df1.randomSplit([0.8, 0.2], seed=142) # Kontrol print(train_df.count()) print(test_df.count()) 40805 10241
16. Model Eğitimi (Train )
Burada pipeline kullanmanın faydasını görüyor ve tek satırda işi bitiriyoruz. Bu kod pipeline ile dizdiğimiz boncukların topunu birden eğitiyor/dönüştürüyor. Bunu söylüyorum çünkü fit ile akıllar genelde sınıflandırıcının eğitimine gidiyor. Hayır yanlış. Sadece sınıflandırıcı değil, estimator soyundan gelen herkesi kurutuyoruz 🙂
pipeline_model = pipeline_obj.fit(train_df)
17. Eğitilmiş Modeli Saklama
Eğittiğimiz modeli saklayalım bir köşede dursun, yarın bir gün KPSS’ye çalışırken lazım olur 🙂
pipeline_model.stages[-1].write().overwrite().save("saved_models/lightgbm_churn_pca10")18. Modeli Test Etme (Prediction, Test)
transformed_df = pipeline_model.transform(test_df)
Yukarıda eğittiğimiz modeli kullanarak test veri setinin üzerinden geçtik ve yeni bir dataframe elde ettik. Bu dataframe test verisi ile aynı, sadece modelin ürettiği prediction gibi birkaç yeni sütun eklendi ancak satır sayısı değişmedi. Yeni sütunlara bir göz atalım.
transformed_df.select('label','prediction','probability','rawPrediction').show(truncate=False)
+-----+----------+-----------------------------------------+------------------------------------------+
|label|prediction|probability |rawPrediction |
+-----+----------+-----------------------------------------+------------------------------------------+
|0.0 |1.0 |[0.4562176701118613,0.5437823298881387] |[-0.5437823298881387,0.5437823298881387] |
|0.0 |0.0 |[2.102333003227442,-1.1023330032274423] |[1.1023330032274423,-1.1023330032274423] |
|0.0 |1.0 |[0.7632705594919944,0.2367294405080056] |[-0.2367294405080056,0.2367294405080056] |
|0.0 |0.0 |[1.8093703165253254,-0.8093703165253253] |[0.8093703165253253,-0.8093703165253253] |
|0.0 |1.0 |[0.6734445596582923,0.32655544034170764] |[-0.32655544034170764,0.32655544034170764]|
|0.0 |0.0 |[1.7771846873326411,-0.7771846873326412] |[0.7771846873326412,-0.7771846873326412] |
|1.0 |0.0 |[3.4090835887151716,-2.4090835887151716] |[2.4090835887151716,-2.4090835887151716] |
|0.0 |0.0 |[3.586670241831012,-2.586670241831012] |[2.586670241831012,-2.586670241831012] |
|1.0 |1.0 |[0.24713914491528488,0.7528608550847151] |[-0.7528608550847151,0.7528608550847151] |
|0.0 |1.0 |[0.7618951265152561,0.23810487348474382] |[-0.23810487348474382,0.23810487348474382]|
|1.0 |1.0 |[0.5203617673022305,0.47963823269776956] |[-0.47963823269776956,0.47963823269776956]|
|0.0 |1.0 |[0.8025987625990936,0.1974012374009064] |[-0.1974012374009064,0.1974012374009064] |
|0.0 |0.0 |[3.666977164621044,-2.666977164621044] |[2.666977164621044,-2.666977164621044] |
|0.0 |0.0 |[1.8178808236023443,-0.8178808236023443] |[0.8178808236023443,-0.8178808236023443] |
|0.0 |0.0 |[2.016703363178061,-1.016703363178061] |[1.016703363178061,-1.016703363178061] |
|0.0 |0.0 |[1.0515267308199159,-0.05152673081991593]|[0.05152673081991593,-0.05152673081991593]|
|0.0 |0.0 |[1.657668999702923,-0.657668999702923] |[0.657668999702923,-0.657668999702923] |
|1.0 |1.0 |[0.06666519017669004,0.93333480982331] |[-0.93333480982331,0.93333480982331] |
|0.0 |0.0 |[1.3882935144440172,-0.38829351444401716]|[0.38829351444401716,-0.38829351444401716]|
|0.0 |0.0 |[2.9811306429627957,-1.9811306429627957] |[1.9811306429627957,-1.9811306429627957] |
+-----+----------+-----------------------------------------+------------------------------------------+19. Modeli Değerlendirme (Evaluate the model)
Model değerlendirmek için Spark’ta bulunan sınıfları kullanalım. Binary sınıflandırma için özel bir sınıf var: BinaryClassificationEvaluator. Burada belirtmek isterimki binary sınıflandırmada accuracy hesaplamak isterseniz MulticlassClassificationEvaluator‘u kullanın. Binary sadece areaUnderROC hesaplıyor.
from pyspark.ml.evaluation import BinaryClassificationEvaluator evaluator = BinaryClassificationEvaluator() print(evaluator.evaluate(transformed_df)) 0.5710878139549131 print(evaluator.getMetricName()) 'areaUnderROC'
Sonucu yeterli bulmayabilirsiniz. Burada ona odaklanmadık. Ana odağımız harici bir sınıflandırıcıyı Spark içinde kullanmaktı. Elbette uğraşılırsa biraz daha başarı arttırılabilir. Administrator, engineer başarıyı da arttırırsa datascientist’e ne iş kalacak? Onu da o arttırsın 🙂
Böylelikle Spark’a yönelik yazılmış SparkML dışı bir sınıflandırıcıyı nasıl kullanacağımızın bir örneğini hep beraber görmüş olduk. İlgili notebook bu repoda mevcuttur.
Başka bir yazıda görüşmek dileğiyle esen kalın…

