K En Yakın Komşu (K-Nearest Nighbor) Sınıflandırma: R ile Örnek Uygulama
 (No Ratings Yet)
(No Ratings Yet)Sınıflandırma notları serimize devam ediyoruz. Sınıflandırma ve k en yakın komşu teorisinden daha önce bahsetmiştik. Özet olarak tekrar bir üzerinden geçelim. Sınıflandırmada bildiğimiz gibi eğittiğimiz bir model kullanarak hedef niteliğini bilmediğimiz ancak elimizde özellikleri olan bir nesnenin hangi sınıfa dahil olacağını tahmin ediyoruz. Sınıflandırma algoritmalarından k en yakın komşu en yaygın olarak kullanılan algoritmadır. Mantık kabaca şöyle; k sayısı belirlenir, nesnenin hangi sınıfa dahil olacağını belirlemek için kendisine en yakın olan kaç komşu kullanılacağına dair bir sayı. Bu komşulara olan mesafe bir yöntemle hesaplanır (örn. öklid) Daha sonra bu k sayısı içinde en fazla hangi sınıfa yakınlık var ise bilinmeyen nesnenin de o sınıfa dahil olduğuna hükmedilir. Bu yazımızda R ile uygulama yapacağız.
Çalışma Dizinini Ayarlama, Veri Setini İndirme
setwd('Calisma_Dizininiz')
dataset = read.csv('SosyalMedyaReklamKampanyası.csv', encoding = 'UTF-8')Veri Seti Görünüm

Veriyi Anlamak
Yukarıda gördüğümüz veri seti beş nitelikten oluşuyor. Veri seti bir sosyal medya kayıtlarından derlenmiş durumda. KullaniciID müşteriyi belirleyen eşsiz rakam, Cinsiyet, Yaş, Tahmini Gelir yıllık tahmin edilen gelir, SatinAldiMi ise belirli bir ürünü satın almış olup olmadığı, hadi lüks araba diyelim. Bu veri setinde kolayca anlaşılabileceği gibi hedef değişkenimiz SatinAldiMi’dir. Diğer dört nitelik ise bağımsız niteliklerdir. Bu bağımsız niteliklerle bağımlı nitelik (satın alma davranışının gerçekleşip gerçekleşmeyeceği) tahmin edilecek.
Bağımsız değişkenlerin hepsini analizde kullanmayacağız. Analiz için kullanacağımız nitelikleri seçelim:
dataset = dataset[3:5]
3,4 ve 5’inci nitelikleri alacağımız için parantez içine 3:5 dedik. Yeni veri setimizi de görelim:

Hedef niteliğimiz SatinAldiMi niteliğini factor yapalım.
dataset\$SatinAldiMi = factor(dataset\$SatinAldiMi, levels = c(0, 1))
Veri Setini Eğitim ve Test Olarak Ayırmak
Aynı sonuçları almak için random değeri belirlemek için bir sayı belirliyoruz. 123. split fonksiyonu ile hangi kayıtların eğitim hangi kayıtların test grubunda kalacağını damgalıyoruz. Sonra bu damgalara göre ana veri setinden yeni eğitim ve test setlerini oluşturuyoruz.
library(caTools) set.seed(123) split = sample.split(dataset\$SatinAldiMi, SplitRatio = 0.75) training_set = subset(dataset, split == TRUE) test_set = subset(dataset, split == FALSE)
Yaş ile maaş aynı ölçekte olmadığı için bu nitelikleri normalizasyona tabi tutuyoruz.
training_set[-3] = scale(training_set[-3]) test_set[-3] = scale(test_set[-3])
Eğitim Seti ile Modeli Eğitme ve Test Sonuçlarını Tahmin Etme
Kütüphaneyi yükleyelim
library(class)
Modeli oluşturalım:
y_pred = knn(train = training_set[,-3], test = test_set[,-3], cl = training_set[,3], k = 5)
Yukarıdaki kodlarla iki işi birden yaptık. İlki sınıflandırıcımızı oluşturup eğittik, ikincisi eğitilen modelde test seti kullanarak tahmin sonuçları (y_pred) ürettik. Parametrelerden ilki train eğitim setini alır. Köşeli parantez içindeki -3 üçüncü sütun hariç diğerlerini al demektir. Üçüncü sütun hedef nitelik çünkü. İkinci parametre test, test setini alır. Üçüncü parametremiz cl, eğitim setindeki hedef niteliği alır. Son parametre k ise, kaç komşuya bakarak sınıflandırma kararı verileceğini belirler. Buna da ağız alışkanlığı 5 diyelim. En iyi k seçimi nasıl olur ona girmiyorum.
Hata Matrisi Oluşturma
cm = table(test_set[, 3], y_pred) cm y_pred 0 1 0 59 5 1 6 30
Eğitim Seti İçin Grafik
library(ElemStatLearn)
set = training_set
X1 = seq(min(set[, 1]) - 1, max(set[, 1]) + 1, by = 0.01)
X2 = seq(min(set[, 2]) - 1, max(set[, 2]) + 1, by = 0.01)
grid_set = expand.grid(X1, X2)
colnames(grid_set) = c('Yas', 'TahminiMaas')
y_grid = knn(train = training_set[,-3],
test = grid_set,
cl = training_set[,3],
k = 5)
plot(set[, -3],
main = 'K En Yakın Komşu (Eğitim set)',
xlab = 'Yaş', ylab = 'Tahmini Maaş',
xlim = range(X1), ylim = range(X2))
contour(X1, X2, matrix(as.numeric(y_grid), length(X1), length(X2)), add = TRUE)
points(grid_set, pch = '.', col = ifelse(y_grid == 1, 'springgreen3', 'tomato'))
points(set, pch = 21, bg = ifelse(set[, 3] == 1, 'green4', 'red3'))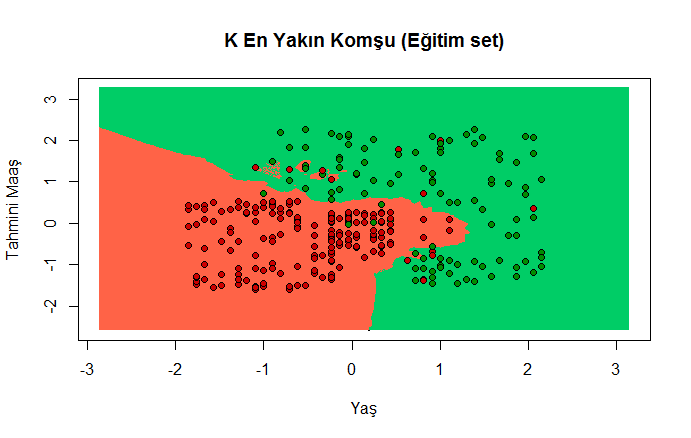
Test Seti İçin Grafik
library(ElemStatLearn)
set = test_set
X1 = seq(min(set[, 1]) - 1, max(set[, 1]) + 1, by = 0.01)
X2 = seq(min(set[, 2]) - 1, max(set[, 2]) + 1, by = 0.01)
grid_set = expand.grid(X1, X2)
colnames(grid_set) = c('Yas', 'TahminiMaas')
y_grid = knn(train = training_set[,-3],
test = grid_set,
cl = training_set[,3],
k = 5)
plot(set[, -3], main = 'K En Yakın Komşu (Test seti)',
xlab = 'Yaş', ylab = 'Tahmini Maaş',
xlim = range(X1), ylim = range(X2))
contour(X1, X2, matrix(as.numeric(y_grid), length(X1), length(X2)), add = TRUE)
points(grid_set, pch = '.', col = ifelse(y_grid == 1, 'springgreen3', 'tomato'))
points(set, pch = 21, bg = ifelse(set[, 3] == 1, 'green4', 'red3'))