
Iris Verisi ile Sınıflandırma Alıştırması (Python Scikit-Learn)
 (No Ratings Yet)
(No Ratings Yet)Meşhur iris verisinden daha önce bir yazımızda bahsetmiştik. Bu yazımızda iris veri seti ile Python scikit-learn kütüphanesini kullanarak basit bir sınıflandırma çalışması yapacağız. Bu alıştırmada iris çiçeğinin alt ve üst yaprak genişlik ve uzunluklarını kullanarak çiçeğin üç türünden hangisine ait olduğunu bulmaya (sınıflandırmaya) çalışacağız.
Gerekli Kütüphaneleri ve Veriyi İndirme
from sklearn.datasets import load_iris from sklearn.neighbors import KNeighborsClassifier iris = load_iris()
Veri seti aslında ön işlemeye tabi tutulmuş. Dikkat ederseniz veri zaten kütüphanenin bir fonksiyonu olarak indiriliyor. Birazdan keşfedici veri analizi safhasında göreceğimiz gibi hedef değişken kategorikten nümeriğe çevrilmiş, bağımlı ve bağımsız değişkenler ayrılmış durumda.
Keşfedici Veri Analizi
Veriyi daha iyi anlamak adına verimize bir göz atalım bakalım ne var ne yok, adı ne, özellikleri ne, vs? Önce niteliklerimizin (bağımsız değişkenler) isimlerini öğrenelim:
iris.feature_names ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
Gördüğümüz gibi dört niteliğimizin isimleri listelendi.
Bağımlı değişkenimizi öğrenelim:
iris.target_names array(['setosa', 'versicolor', 'virginica'], dtype='<U10')
Üç farklı sınıfımız (iris çiçek türü) listelendi. Şimdi hedef değişkenimizi görelim.
iris.target
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])Pekala hani setosa, versicolor ve virginica olmak üzere üç tür vardı nereden çıktı bu rakamlar? Başta da söylediğimiz gibi veri setinin ön işlemesi yapılmış ve yukarıdaki üç türü temsilen bir rakam atanmış. Setosa 0, versicolor 1 ve virginica 2 gibi.
Niteliklerimize bir bakalım:
iris.data
array([[ 5.1, 3.5, 1.4, 0.2],
[ 4.9, 3. , 1.4, 0.2],
[ 4.7, 3.2, 1.3, 0.2],
[ 4.6, 3.1, 1.5, 0.2],
[ 5. , 3.6, 1.4, 0.2],
[ 5.4, 3.9, 1.7, 0.4],
[ 4.6, 3.4, 1.4, 0.3],
[ 5. , 3.4, 1.5, 0.2],
[ 4.4, 2.9, 1.4, 0.2],
[ 4.9, 3.1, 1.5, 0.1],
[ 5.4, 3.7, 1.5, 0.2],
[ 4.8, 3.4, 1.6, 0.2],
[ 4.8, 3. , 1.4, 0.1],
[ 4.3, 3. , 1.1, 0.1],
[ 5.8, 4. , 1.2, 0.2],
.......
[ 6.7, 3.3, 5.7, 2.5],
[ 6.7, 3. , 5.2, 2.3],
[ 6.3, 2.5, 5. , 1.9],
[ 6.5, 3. , 5.2, 2. ],
[ 6.2, 3.4, 5.4, 2.3],
[ 5.9, 3. , 5.1, 1.8]])Her bir nitelik bir değerden oluşmuş.
Bağımlı ve Bağımsız Değişkenleri Oluşturma
Bağımsız nitelikleri X, bağımlı niteliği y değişkenine atayalım:
X = iris.data y = iris.target
Eğitim ve Test Setlerini Ayırma
from sklearn.cross_validation import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0)
Verinin % 75’i eğitim için, % 25’i ise test için ayrıldı.
Model Kurma
Model için k en yakın komşu algoritmasını ve bununla ilgili scikit-learn sınıfını kullanalım.
enyakin_komsu = KNeighborsClassifier()
Sınıfımızın bir çok parametresi var. Bunlara kısaca değinelim:
n_neighbors : kaç tane komşu kullanacağımıza dair k değeridir. Varsayılan 5
metric : Komşuya uzaklık hesaplanırken kullanılacak mesafe metriği. Varsayılan minkowski
p : metric için minkowski kullanıldığında kullanılan power parametre. Varsayılan 2
yukarıdaki örnekte hiçbir parametre girmediğimiz için varsayılanlar geçerli oldu. Görelim:
enyakin_komsu = KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski', metric_params=None, n_jobs=1, n_neighbors=1, p=2, weights='uniform')
Modeli Eğitme
enyakin_komsu.fit(X_train,y_train)
Test Seti ile Hedef sınıfları tahmin etme
y_pred = enyakin_komsu.predict(X_test)
Tahmin Sonuçlarını Test Sonuçları ile Karşılaştırma
Hata matrisi (confusion matrix) kullanarak modelin başarısını ölçelim:
from sklearn.metrics import confusion_matrix
hata_matrisi = confusion_matrix(y_test, y_pred)
print(hata_matrisi)
array([[13, 0, 0],
[ 0, 15, 1],
[ 0, 0, 9]])Hata Matrisini Yorumlama
Şimdi yukarıdaki rakamlar da neyin nesi? Hatırlarsanız veri setimiz 150 kayıtlı idi. Biz bunun %75’ini (112) eğitim, %25’i (38) test eğitim seti olarak ayırmıştık. Modelimizi 112 kayıt ile eğittik. Ayırdığımız 38 kayıta ait nitelikleri (X_test) eğittiğimiz bu modeli kullanarak tahminde bulunduk (y_pred). Sonra elimizde zaten 38 test kaydına ait gerçek sonuçlar (y_test) vardı. Bunları tahmin sonuçları ile karşılaştırdık ve yukarıdaki matrisi elde ettik. Matristeki rakamları toplar isek 38 olduğunu göreceğiz. Aşağıdaki şekil ile biraz daha işi anlaşılır kılalım:
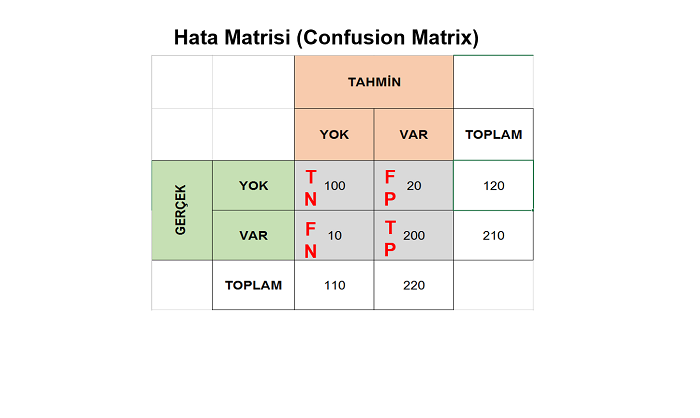
38 tane test kaydında Setosa sınıfına ait 13 tane kayıt varmış ve hepsi doğru tahmin edilmiş. 16 tane versicolor varmış bunlardan 15 tanesi doğru 1 tanesi yanlış (virginica) tahmin edilmiş. 9 tane virginica varmış ve hepsi de başarıyla virginica olarak tahmin edilmiş.

Hocam merhaba bişey sormak istiyorum ;
iris veri setini , karar ağaçları, diskriminant analizi, küme analizi, yapay sinir ağları ile incelersek hangi yöntem sınıflandırma için daha uygun ve başarılıdır ? Bu konuda fikirlerinizi öğrenmek istiyorum ?
Merhaba. Şu algoritma daha iyidir ve başarılıdır şeklinde bir genelleme yapmak doğru olmaz. Deneyip öyle karar vermenizi tavsiye ederim.