R ile Tek Yönlü Varyans Analizi
 (No Ratings Yet)
(No Ratings Yet)One Way ANalysis Of VAriance, Türkçe söylemek gerekirse Tek Yönlü Varyans Çözümlemesi ya da Tek Yönlü ANOVA diyebiliriz. Hangi durumlarda yapabiliriz peki bu çözümlemeyi?
En az 3 bağımsız örneklem olduğu durumlarda yaparız bu çözümlemeyi ve sözü daha fazla uzatmadan hemen R’da bu çözümlemeyi nasıl yapabiliriz ona geçelim.
Hipotezimizi kurmadan olmaz. Hemen hipotezimizi kuralım.
H0: μapollo = μbridgestone = μCEAT = μFALKEN
H1: En az bir μ diğerlerinden farklıdır.
Daha sonra verileri yüklüyoruz. Verilere buradan ulaşabilirsiniz.
Verileri yükledikten sonra attach() komutunu kullanarak kontrol ediyoruz.
attach(tyre)
Herhangi bir şey yapmadan önce, değişken tipini kontrol etmeliyiz, kategorik bağımsız değişkene ihtiyacımız var (burada faktör değişkenimiz “Brand”). Bunun için aşağıdaki kodu kullanabiliriz.
is.factor(Brands)
Çıktı:
TRUE
Cevabını aldığımızdan dolayı “Brand” değişkenimizin kategorik bir değişken olduğunu söyleyebiliriz.
Diğer modellerde olduğu gibi ANOVA’da da aykırı durumların varlığını kontrol etmeliyiz. Çalışmamızda 4 değişken olduğu için her biri için ayrı bir kutu grafiği (boxplot) kullanmalıyız. Bunu aşağıdaki komut ile yapabiliriz :
boxplot(Mileage ~ Brands, main=" Dört Lastik Markasının Kilometre Boxplot Grafiği", col=rainbow(4))
Çıkan Grafik:

Bu kodla hem grafiğimizin başlığını isimlendirdik (main””) hem de her markanın farklı renklerle olmasını sağladık(col=rainbow(4)).
Eğer daha gelişmiş bir grafik kullanmak istersek ggplot2 kütüphanesini tercih edebiliriz. Bunun için aşağıdaki kodu kullanabiliriz:
library(ggplot2) ggplot(tyre, aes(Brands,Mileage))+geom_boxplot(aes(col=Brands))+labs(title=" Dört Lastik Markasının Kilometre Boxplot Grafiği")
Çıkan Grafik:
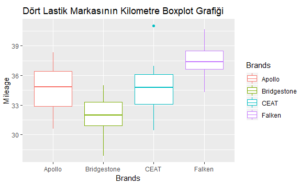
Yukarıdaki grafikte CEAT markasında bir aykırı gözlem olduğunu gözlemekteyiz. Aykırı değeri veya değerleri bulmak için aşağıdaki komutu kullanabiliriz:
boxplot.stats(Mileage[Brands=="CEAT"])
Çıktı:
$`stats` [1] 30.42748 33.11079 34.78336 36.12533 36.97277 $n[1] 15 $conf[1] 33.55356 36.01316 $out[1] 41.05[/code]
Yukarıdaki çıktıyı yorumlamak istersek şöyle yorumlayabiliriz:
Aykırı değerimiz 41.05 olan gözlemdir. Güven aralığımız (33.55 -36.01) olup, “CEAT” değişkeninin minimum ve maksimum değerlerinin sırasıyla 30.43 ve 41.05 olduğunu söyleyebiliriz. Tüm bu noktaları göz önünde bulundurduğumuzda, aykırı değeri görmezden gelip analizi yapabiliriz. Daha sonraki aşamalarda, bu görmezden gelme olayı başımıza iş açacağını tespit edersek bu görmezden gelme olayını yapmayacağız.
Modelin Değerlendirilmesi(Tahmini)
R’da ANOVA modelini kurmak için aov() fonksiyonunu kullanıyoruz.
model1 <- aov(Mileage ~ Brands)
Tek Yönlü ANOVA’nın sonucunu görmek için aşağıdaki fonksiyonu kullanabiliriz:
summary(model1)
Çıktı:
Df Sum Sq Mean Sq F value Pr(>F) Brands 3 256.3 85.43 17.94 2.78e-08 *** Residuals 56 266.6 4.76 ---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Yukarıdaki sonuçlardan, F-istatistik değerinin 17.94 olduğu ve karşılık gelen p-değerinin, anlamlılık seviyesinden (% 1 veya 0.01) çok daha az olması nedeniyle, oldukça anlamlı olduğu gözlenmiştir. Bu nedenle, tüm lastik markalarında ortalama kilometre performans değerinin H0 hipotezini reddetmek akıllıca olacaktır. Diğer bir deyişle, dört lastik markasının ortalama performansı eşit değildir.
Ama Tek Yönlü ANOVA Çözümlemesi bize hangi farklı olan lastik türünü vermiyor. Farklı olan lastik türünün tespiti için Tukey testi yapabiliriz. R’da, Tukey testinin uygulama kodu :
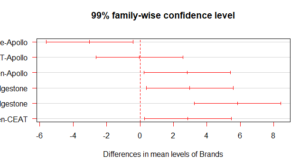
TukeyHSD(model1, conf.level = 0.99)
Çıktı:
Tukey multiple comparisons of means 99% family-wise confidence level Fit: aov(formula = Mileage ~ Brands)
$`Brands` diff lwr upr p adj
Bridgestone-Apollo -3.01900000 -5.6155816 -0.4224184 0.0020527
CEAT-Apollo -0.03792661 -2.6345082 2.5586550 0.9999608
Falken-Apollo 2.82553333 0.2289517 5.4221149 0.0043198
CEAT-Bridgestone 2.98107339 0.3844918 5.5776550 0.0023806
Falken-Bridgestone 5.84453333 3.2479517 8.4411149 0.0000000
Falken-CEAT 2.86345994 0.2668783 5.4600415 0.0037424 TukeyHSD komutu, dört marka lastiğin kilometre performansının anlamlılık farkını% 1 seviyesinde gösterir. Burada, “diff” sütunu ortalama farklılıklar sağlar. “Lwr” ve “upr” sütunları, sırasıyla% 99’luk alt ve üst güvenlik sınırları sağlar. Son olarak, “p adj” sütunu, yapılan karşılaştırmaların sayısı için ayarlanmış p-değerlerini sağlar. Dört marka olduğu için altı olası ikili karşılaştırma elde edilir( (k-1)! ). Sonuçlar, tüm kilometre performanslarının, CEAT-Apollo çifti hariç, Tukey Testi’ne göre istatistiksel olarak anlamlı ölçüde farklı olduğunu göstermektedir. Daha spesifik olarak, Bridgestone-Apollo arasındaki çift-fark, -3.019 olarak bulunmuştur, bu da Apollon’un Bridgestone’dan daha yüksek bir kilometre taşı olduğu anlamına gelir ve bu istatistiksel olarak önemlidir. Benzer şekilde, diğer çift karşılaştırmaları yapabilirsiniz.
Ayrıca, Tukey’in HSD karşılaştırmasının sonuçlarını, grafik şeklinde aşağıdaki kodu kullanarak da çizebiliriz:
plot(TukeyHSD(model1,conf.level = 0.99),las=1, col="red")
Grafik görselleştirmenin bir diğer yolu da, gplots kütüphanesinin yardımıyla yapabiliriz. Ayrıca güven aralıkları da dahil olmak üzere tek değişkenler için ortalamaları görebiliriz. Bunun için aşağıdaki kodu kullanabiliriz:
library(gplots)
plotmeans(Mileage~Brands, main=" %95 Güven Aralığı ve Ortalama Grafiği", ylab = "Mileage run ('000 miles)", xlab = "Brands of Tyre")Grafik Çıktısı:

Teşhis Koyma (Tanı Denetimi):
ANOVA modelini hesapladıktan sonra ve olası farklılık çiftlerini bulduktan sonra, model varsayımlarına göre farklı tanı denetimlerine geçmenin zamanı geldi. Bu kullanacağımız kodla dört tanısal grafik oluşturacağız. Kodunu aşağıda bulabilirsiniz:
par(mfrow=c(2,2)) plot(model1)

Şekil 5’de sol üst köşedeki grafik Artık ve uygun değerleri, model artıklarına karşı çizilen tiz değerleri gösterir. Artıklar diyagonal(çaprazlama) bir çizgi gibi herhangi bir belirli deseni takip ederse, modelde henüz geliştiremeyen başka belirleyiciler de olabilir.
Şekil 5’de sağ üst köşedeki grafik ise Normallik Grafiğini göstermekte eğer şekle daha yakından baktığımızda normal olduğunu görürüz sadece bir tane aykırı değer var gibi duruyor. Bu durum bizim başımıza dertte açabilir diyerekten böyle sade bir yorum yapabiliriz.
Şekil 5’de sol alt köşedeki grafikse Ölçek- Yer grafiğini göstermektedir. Çizilen veya tahmin edilen değerlere karşı çizilen mutlak standartlaştırılmış artıkların karekökünü gösterir. Bunun düşük seviyedeki çizgisi, oldukça fazla olduğu için, tahminlerdeki yayılmanın tahmin çizgisi boyunca hemen hemen aynı olduğunu ve bu da değişen varyanslılığın varsayımını karşılamadaki başarısızlık ihtimalinin daha az olduğunu göstermektedir. Bu, bazı istatistiksel testlerle daha da doğrulanacaktır. ANOVA durumunda, dört lastik markası arasında varyansların homojenliği varsayımını kontrol edebiliriz.
Son olarak Şekil 5’de sağ alt köşedeki grafik ise her noktanın standart denklemlere karşı genel denklem üzerindeki etkisinin bir ölçüsünü gösterir. Hiçbir nokta paketten uzak durmadığından, modelin üzerinde aşırı etkisi olmayan aykırı değerler olduğunu varsayabiliriz.
Bu nedenle, modelin uygunluğunun grafiksel olarak teşhis edilmesi, ANOVA modelinin varsayım gereksinimlerinin oldukça yerine getirildiğini göstermektedir. Bununla birlikte, normallik varsayımı ve homojenliğinin, uygun istatistiksel testlerle doğrulanmamız gerekir.
Normallik varsayımının yerine getirilmesi ile ilgili olarak, gözlem sayılarının daha az olduğu durumlarda, ayrı bir grup için kontrol etmek yerine, modelin genel artıkları için normalliği test etmek akıllıca olacaktır. R’de modelin artıkları aşağıdaki gibi gösterilir:
uhat <- resid(model1)
Bundan sonra Shapiro-Wilk testini normallik testi için kullanabiliriz. ANOVA’nın gerekliliklerinden biri Normallik varsayımının sağlanmasıdır.Modeldeki artıkları uhat’a atıyoruz.
Hipotezimizi kuralım:
H0 : Gözlemimiz normal dağılıyor.
H1: Gözlemimiz normal dağılmıyor.
Normallik testi için aşağıdaki kodu kullanabilliriz:
shapiro.test(uhat)
Çıktı:
Shapiro-Wilk normality test data:
uhatW = 0.9872, p-value = 0.7826p değerimiz önem düzeyinden daha yüksek çıktığından dolayı H0 hipotezimizi reddemeyiz (diğer bir deyişle H0 kabul) yani gözlemimizin normal dağıldığını söyleyebiliriz.
ANOVA’nın diğer gereksinimi ise Varyansların Homojenliğidir. Bunu Bartlett Testi ile test edebiliriz. Her iki testte de yokluk (sıfır) hipotezimizi gözlemler için varyanslar homojendir şeklinde kurmamız lazım.
Hipotezimizi kuralım:
H0: Gözlemimiz için varyanslar homojendir.
H1: Gözlemimiz için varyanslar homojen değildir.
Bartlett Testi için aşağıdaki kodu kullanabiliriz:
bartlett.test(Mileage~Brands)
Çıktı:
Bartlett test of homogeneity of variances data:
Mileage by BrandsBartlett's K-squared = 2.1496, df = 3, p-value = 0.5419p değerimiz önem düzeyinden daha yüksek çıktığından dolayı H0 hipotezimizi reddemeyiz (diğer bir deyişle H0 kabul) yani gözlemimiz için varyansların homojen olduğunu söyleyebiliriz.
SONUÇ:
Dört lastik markasının ortalama kilometre performans değerlerinin farklı olduğunun kanısına varabiliriz. Tüm kilometre performans çiftlerinin CEAT-Apollo çifti hariç, Tukey Testi’ne göre istatistiksel olarak anlamlı ölçüde farklı olduğunu göstermektedir. Daha spesifik olursak Bridgestone-Apollo arasındaki fark -3.019 çıkmıştır ve bu da bize Apollo’nun Bridgestone’dan daha yüksek kilometre performansı olduğu anlamına gelir ve bu istatistiksel olarak önemlidir.
Bu yazım kaynakta belirttiğim siteden derlediğim bir yazıdır. Daha sonraki yazılarımda R veya Python ile başka analizler yapmaya devam edeceğim. Takipte kalmanızı önemle rica ediyorum kendinize iyi bakınız efendim. 😊
Kaynak:
- https://datascienceplus.com/one-way-anova-in-r/