Python ile Tidy Data
 (No Ratings Yet)
(No Ratings Yet)Veri bilimci olarak, veri setlerini standartlaştırılmış bir yapı halinde kullanmaya alışmamız lazım. Veri temizleme, veri bilimideki en sık yapılan iştir. İstediğiniz veri ile uğraşın yada istediğiniz analizi yapın, eninde sonunda veriyi temizlediğiniz bir noktaya varıcaksınız. Verinizi standart bir biçimde düzenlemek işlerinizi daha da kolaylaştıracaktır.
Düzenli Veri (Tidy Data) Nedir?
“Tidy Data” kavramını 2014 yılında Hadley Wickham yazdığı makalesinde tanıtmıştır. Tidy Data kavramını 3 maddede açıklıyoruz:
- Her sütun bir değişkeni temsil eder.
- Her satır bir gözlemi temsil eder.
- Her bir gözlem birimi bir tablo oluşturur.
Dağınık veriye örnek vericek olursak:

Düzenli veriye örnek vericek olursak:

Dağınık Veri Setini Düzenlemek
Artık veri setini düzenlemeye başlayabiliriz. Burdaki amacımız veriyi analiz etmek değil, veriyi analiz etmek için standart bir hale getirmektir. Bu yazıda uğraşacağımız 5 tane dağınık veri seti tipi vardır:
- Sütun başlıkları değişken ismi değildir, birer değerdir.
- Birden çok değişken bir sütunda saklanmıştır.
- Değişkenler hem sütun hem satırda depolanmıştır.
- Birden çok gözlem birimi türü aynı tabloda saklanmıştır.
- Tek bir gözlem birimi birden fazla tabloda saklanmıştır.
Sütun başlıkları değişken ismi değildir, birer değerdir
Bu problemde ilk olarak Pew Research Center veri setini kullanacağız. Bu veri seti gelir ile din arasındaki ilişkiyi inceler. Veri setinin problemi ise sütun başlıkları olası gelir değerlerinden oluşmaktadır.
Öncelikle kullancağımız kütüphaneleri çalışma ortamımıza ekliyoruz.
import pandas as pd
import datetime
from os import listdir
from os.path import isfile, join
import glob
import reArtık veri setimizi yükleyebiliriz.
df = pd.read_csv("pew-raw.csv")
df.head()Bu verimizin düzenli halinde gelir değerleri sütun başlıkları olmak yerine income sütunu altında birer değer olmalıdır.
dformatted_df = pd.melt(df,
["religion"],
var_name="income",
value_name="freq")
formatted_df = formatted_df.sort_values(by=["religion"])
formatted_df.head(10)Veri setimizin düzenli halinin çıktısı aşağıdaki gibidir
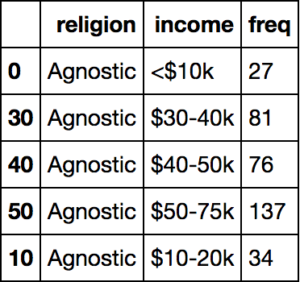
Bu problemde ikinci olarak Billboard Top 100 veri setini kullancağız. Bu veri seti bize Billboard Top 100 girdikten sonraki 75 hafta boyunca şarkıların haftalık sıralamasını veriyor. Veri setinin problemi ise sütun başlıkları olası hafta numaralarından oluşmaktadır. Ayrıca eğer bir şarkı 75 haftadan daha az sürede Billboard Top 100’e girmişse, geri kalan haftalar eksik değerler ile dolmuştur.
Verimizi yükleyelim
df = pd.read_csv("billboard.csv", encoding="mac_latin2")
df.head(10)
Bu veri setinin düzenli halinde hafta numaraları birer sütun başlığı olmak yerine tek bir sütun altında değer olarak toplanmalıdır. Bunu yapmak için, bütün hafta sütunlarını pandas kütüphanesi içindeki melt fonksiyonunu kullanarak date isimli bir sütuna toplamalıyız. Her bir kayıt için hafta başına bir satır oluşturacağız.
Öncelikle birleştirmek istemediğimiz sütunları bir liste içine kaydedelim.
id_vars = ["year",
"artist.inverted",
"track",
"time",
"genre",
"date.entered",
"date.peaked"]Şimdi ise ‘melt’ fonksiyonunu kullanarak birleştirme işlemini yapabiliriz.
df = pd.melt(frame=df,id_vars=id_vars, var_name="week", value_name="rank")melt fonksiyonundaki var_name argümanı ile birleştirdiğimiz sütunları aktaracağımız yeni sütunun adını, value_name argümanı ile ise bu yeni sütunun değerlerini saklayan sütunun adını atamamıza yarıyor.
Yukarıda veri setinin çıktısında gördüğümüz gibi hafta sütunlarının adı sadece haftanın numarasında oluşmuyor. Örneğin 1. haftayı ifade eden sütunun adı x1st.week tir. Bizim her bir hafta sütununun içinden numaraları yakalayıp kullanmamız lazım. Ayrıca rank sütunumuzun değerleri tam sayıya çevirmemiz lazım. Bu işlemleri yapmak için;
df["week"] = df['week'].str.extract('(\d+)', expand=False).astype(int)
df["rank"] = df["rank"].astype(int)kodlarını yazmamız lazım. str.extract metodu ile karakter ifadenin içindeki istediğimiz şablonu çıkartabiliriz. astype metodu ile sütun içindeki değerleri istediğimiz tipe çevirebiliyoruz.
Bu işlemden sonra eksik değer içeren gözlemleri df = df.dropna() komutu ile siliyoruz.
Şimdi ise date sütununu oluşturalım.
df['date'] = pd.to_datetime(df['date.entered']) + pd.to_timedelta(df['week'], unit='w') - pd.DateOffset(weeks=1)pd.to_datetime fonksiyonu ile karakter olan date.entered sütununu tarih formatına çeviriyoruz. pd.to_timedelta fonksiyonu ile week sütunundaki değerlerinin gün bazındaki karşılığına çeviriyoruz. Örnek vermek gerekirse 13 haftayı 91 güne çeviriyoruz. Bu fonksiyonun içindeki unit argümanı ile sadece gün değil, diğer zaman birimlerini de yazarak çevirme işlemi yapabiliriz. pd.DateOffset fonksiyonu ile de yukarıdaki tarih toplama işleminde 1 haftalık bir süre çıkartıyoruz.
Artık date sütunumuzu da oluşturduğumuza göre tablomuzun son haline bakabiliriz.
df = df[["year",
"artist.inverted",
"track",
"time",
"genre",
"week",
"rank",
"date"]]
df = df.sort_values(ascending=True, by=["year","artist.inverted","track","week","rank"])
Görüldüğü gibi veri setinin daha düzenlenmiş hali yukarıdaki gibidir. Ancak yinede Hadley Wickham tanımlarına tam olarak uymamaktadır. Aynı şarkının çok fazla tekrarlanmış olduğunu görüyoruz. Bir sonraki problemimizde bu sorunlar üzerine değineceğiz.
Birden çok gözlem birimi türü aynı tabloda saklanmıştır
En son Billboard tablosunda bahsettiğimiz problem, bir tablo içinde birden çok gözlem birimi bulunmaktadır.
Öncelikle songs adında her bir şarkının detayının bulunduğu bir tablo oluşturacağız.
songs_cols = ["year", "artist.inverted", "track", "time", "genre"]
songs = billboard[songs_cols].drop_duplicates()
songs = songs.reset_index(drop=True)
songs["song_id"] = songs.index
songs.head(10)Yukarıdaki kodda ilk satırda, oluşturacağımız tablonun sütunlarını belirledik. 2. satırda ile billboard tablomuzdaki her bir şarkının tek satır olacak şekilde diğer kopyalarını siliyoruz. 3. satırda ise oluşturduğumuz songs tablosunun indeks değerlerini sıfırlıyoruz. Burda kullandığımız drop=True değeri ile eski indeks değerlerini siliyoruz. Ve son olarak tablomuza songs_id sütunu atayarak bu sütunu da indeks sütunu yapıyoruz.

Şimdi ise sadece song_id, date ve rank değerlerini içeren ranks adında bir tablo oluşturacağız.
ranks = pd.merge(billboard, songs, on=["year","artist.inverted", "track", "time", "genre"])
ranks = ranks[["song_id", "date","rank"]]
ranks.head(10)
Birden çok değişken bir sütunda saklanmıştır
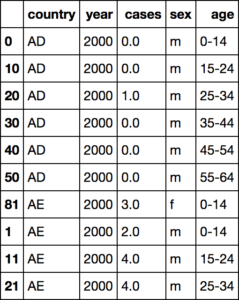
Bu problemde Tubercolosis Records from World Health Organization veri seti ile çalışacağız. Bu veri setinde onaylanmış tüberküloz vakalarının ülke, yıl, yaş ve cinsiyet bazında verisi bulunmaktadır. Burdaki problemimiz ise bazı sütunlar birden çok değişken içeriyor. Ayrıca çok fazla sıfır ve eksik değer vardır. Bu problem veri toplama sürecinden kaynaklanmaktadır ve bu veri seti için bu problemin çözülmesi önem taşımaktadır.
Önce verimize bakalım
df = pd.read_csv("tb-raw.csv")
df
Bu veriyi düzenli hale getirmek için sütun isimlerindeki farklı isimleri silip, bunları tek bir sütuna indirmemiz gerekiyor. İlk önce bu sütunları melt fonksiyonu ile sex_and_age adlı sütun altına alıp ardından bu sütunu sex, age_lower ve age_upper olarak 3 sütuna bölmemiz gerekiyor. Bu adımlardan sonra düzenli verimizi tam olarak oluşturabiliriz.
df = pd.melt(df, id_vars=["country","year"], value_name="cases", var_name="sex_and_age")
tmp_df = df["sex_and_age"].str.extract("(\D)(\d+)(\d{2})")
tmp_df.columns = ["sex", "age_lower", "age_upper"]
tmp_df["age"] = tmp_df["age_lower"] + "-" + tmp_df["age_upper"]
df = pd.concat([df, tmp_df], axis=1)
df = df.drop(['sex_and_age',"age_lower","age_upper"], axis=1)
df = df.dropna()
df = df.sort(ascending=True,columns=["country", "year", "sex", "age"])
df.head(10)Bu işlemlerin sonucunda tablomuz;
Değişkenler hem sütun hem satırda depolanmıştır
Bu problemde Global Historical Climatology Network veri seti ile çalışacağız. Bu veri setinde 2010 yılında 5 aylık süre zarfında Meksika’daki hava istasyonunda (MX17004) kaydedilen günlük hava kayıtları bulunmaktadır. Variables are stored in both rows (tmin, tmax) and columns (days). Bu verideki problem ise değişkenler hem satırda (tmin, tmax) hemde sütunda (days) saklanmıştır.
Öncelikle veriyi inceleyelim.
df = pd.read_csv("weather-raw.csv")
df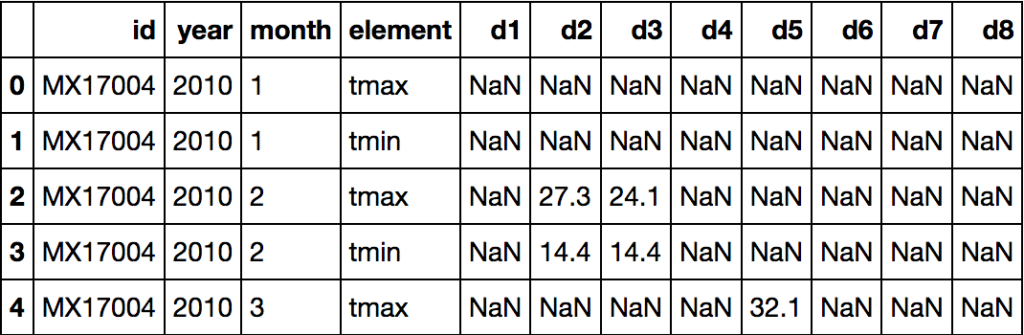
Bu veriyi düzenli hale getirmek için yanlış yerleştirilmiş 3 değişkeni (tmin, tmax, days) alıp 3 ayrı değişken (tmin, tmax, date) olarak düzenlemeliyiz.
df["day"] = df["day_raw"].str.extract("d(\d+)", expand=False)
df["id"] = "MX17004"
df[["year","month","day"]] = df[["year","month","day"]].apply(lambda x: pd.to_numeric(x, errors='ignore'))
def create_date_from_year_month_day(row):
return datetime.datetime(year=row["year"], month=int(row["month"]), day=row["day"])
df["date"] = df.apply(lambda row: create_date_from_year_month_day(row), axis=1)
df = df.drop(['year',"month","day", "day_raw"], axis=1)
df = df.dropna()
df = df.pivot_table(index=["id","date"], columns="element", values="value")
df.reset_index(drop=False, inplace=True)Yukarıdaki kodda ilk olarak günleri sayı olarak gün sütunlarından çıkartıyoruz ve bu değerleri day adında yeni bir sütuna atıyoruz. Daha sonra year, month ve day sütunlarını sayısal değerlere çeviriyoruz. Bu işlemden sonra year, month ve day değerlerini kullanarak date sütunu oluşturuyoruz. Son olarak element sütununun içindeki tmin ve tmax değerlerini sütun haline getiriyoruz.

Tek bir gözlem birimi birden fazla tabloda saklanmıştır
Bu problemde veri setimiz ise 2014/2015 yılları arasında Illinois eyaletinde doğan çocukların isimlerini veriyor. Burdaki problem ise veri, birden fazla tabloya bölünmüştür. Ayrıca Year değişkeni belge isminin içindedir.
Öncelikle yıl değerini belge isminden çıkarmak için bir fonksiyon yazıyoruz.
def extract_year(string):
match = re.match("(\d{4})", string)
if match != None: return match.group(1)Elimizde 2 tane tablo var; bir tanesi 2014 yılında doğan bebekler, ikincisi ise 2015 yılında doğan bebekler. İki tablonunda isim olarak tek farkları yıl değerleridir. Doğal olarak iki tablonun ismi de 201*-baby-names-illinois.csv şeklinde eşleşiyor. Bu eşleşmeyi kullanarak iki tabloyu da
allFiles = glob.glob("201*-baby-names-illinois.csv")kodu ile allFiles değişkenine atadık. glob.glob fonksiyonu ile istediğiniz şablondaki karakterleri aratabilirsiniz.
Bu işlemden sonra boş bir DataFrame oluşturup bunun içine iki tablomuzuda ekleyip, tabloların sütun isimlerini küçük harfe çevirdikten sonra year sütununa tabloların yıl değerlerini ekliyoruz.
frame = pd.DataFrame()
df_list= []
df = pd.read_csv(file_,index_col=None, header=0)
df.columns = map(str.lower, df.columns)
df["year"] = extract_year(file_)
df_list.append(df)
df = pd.concat(df_list)
Ve böylece Python ile Tidy Data yazımızında sonuna geldik. Düzenli veri hakkında daha fazla bilgi almak istiyorsanız Hadley Wickham’ın makalesini okuyabilirsiniz. Bu makalenin linkini kaynakçada bulabilirsiniz.
Kaynakça:
http://www.jeannicholashould.com/tidy-data-in-python.html
https://www.jstatsoft.org/article/view/v059i10


