R ile Metin Madenciliği | Bölüm 5/6
 (No Ratings Yet)
(No Ratings Yet)5. Bölüm – Düzenli Olmayan Veri Formatını Dönüştürme
Önceki bölümlerde, unnest_tokens işlevi tarafından düzenli metin formatına getirilmiş metinleri analiz ettik. Ayrıca metin verilerini keşfetmek ve görselleştirmek için dplyr, tidyr ve ggplot2 gibi araçlar ile analizlerimizi zenginleştirdik.

Yukarıdaki şema tipik bir metin analizinin akış şemasıdır. Bu bölümde döküman-terim matrisleri ve düzenli veri setleri arasında dönüştürme ve bir Corpus nesnesinden bir metin veri çerçevesine dönüştürme işleminin nasıl yapıldığını gösterir.
Şema analizin düzenli ve düzenli olmayan veri yapıları ve araçları arasında nasıl değişebileceğini göstermektedir. Bu bölümde döküman-terim matrislerini toplama sürecinin yanı sıra bir veri çerçevesini seyrek bir matrise dönüştürme üzerinde durulacaktır.
5.1. Döküman-Terim Matrisini Düzenli Hale Getirme
Metin madenciliği paketlerinin birlikte kullanıldığı en yaygın yapılardan biri döküman-terim matrisidir (Document-Term Matrix, DTM).
- Her bir satır kitap veya makale gibi bir belgeyi temsil eder.
- Her bir sütun bir terimi temsil eder ve
- Her bir değer bir belgedeki bir terimin görüntülenme sayısını içerir.
Çoğu döküman-terim çifti meydana gelmediğinden, DTM’ler genellikle seyrek matrisler olarak işlenir. Bu nesneler matrisler gibi ele alınabilir, ancak daha verimli bir biçimde saklanırlar.
Bu bölümde bu matrislerin birkaç uygulaması anlatılacaktır.
DTM nesneleri doğrudan düzenli veri araçları ile kullanılamaz. Bu yüzden tidytext paketi iki format arasında dönüşüm sağlar.
- tidy() döküman-terin matrisini düzenli bir veri çerçevesine dönüştürür. Bu fonksiyon “broom” paketinin bir fonksiyonudur.
- cast() sıralı bir veri çerçevesini matris haline getirir. : tidytext matris dönüştürmede üç farklı varyasyona sahiptir. “Matrix” paketinden cast_sparse() fonksiyonu ile matrisi seyrek matrise dönüştürür. cast_dtm() ise “tm” paketi ile Document-Term Matrix nesnesine dönüştürür.
5.1.1. Döküman-Terim Matrisi Nesnelerini Düzenli Hale Getirme
Muhtemelen en yaygın kullanılan DTM’lerin R’de uygulanması tm paketindeki DocumentTermMatrix fonksiyonudur. Birçok mevcut metin madenciliği veri seti bu biçimde oluşturulmuştur. topicmodels paketinde yer alan Associated Press gazetesinin makalelerini işlemek istersek;
library(tm)
data("AssociatedPress", package = "topicmodels")
AssociatedPress## <<DocumentTermMatrix (documents: 2246, terms: 10473)>>
## Non-/sparse entries: 302031/23220327
## Sparsity : 99%
## Maximal term length: 18
## Weighting : term frequency (tf)Bu veri kümesinin dökümanları ve terimleri içerdiğini görüyoruz. Buradaki DTM’nin %99’un seyrek (sparse) olduğuna dikkat etmemiz gerekir. Yani döküman-kelime çiftlerinin %99’u sıfırdır. Dökümandaki terimlere Terms() fonksiyonu ile erişebiliriz .
terms <- Terms(AssociatedPress)
head(terms)## [1] "aaron" "abandon" "abandoned" "abandoning" "abbott"
## [6] "abboud"Buradaki verileri düzenli araçlarla analiz etmek istersek broom paketindeki tidy() fonksiyonunu kullanabiliriz. tidy() düzenli olmayan nesneleri düzenli hale getirir.
library(dplyr)
library(tidytext)
ap_td <- tidy(AssociatedPress)
ap_td## # A tibble: 302,031 x 3
## document term count
## <int> <chr> <dbl>
## 1 1 adding 1
## 2 1 adult 2
## 3 1 ago 1
## 4 1 alcohol 1
## 5 1 allegedly 1
## 6 1 allen 1
## 7 1 apparently 2
## 8 1 appeared 1
## 9 1 arrested 1
## 10 1 assault 1
## # ... with 302,021 more rowsÇıktının sıfır olmayan değerleri içerdiğine dikkat edelim.“adding” ve “adult” gibi terimleri karşımızda görüyoruz, ancak yukarıdaki terms çıktısındaki “aaron” veya “abondon” ifadelerini göremiyoruz. Bu da, düzenli formatın satırlarında sıfır olan değerler içermediği anlamına gelir.
Daha önceki bölümlerde de gördüğümüz gibi, elde ettiğimiz elde ettiğimiz bu form dplyr, tidytext ve ggplot2 paketleri ile analiz için uygundur. Şimdi duygu analizi yapmak istersek,
ap_sentiments <- ap_td %>%
inner_join(get_sentiments("bing"), by = c(term = "word"))
ap_sentiments## # A tibble: 30,094 x 4
## document term count sentiment
## <int> <chr> <dbl> <chr>
## 1 1 assault 1 negative
## 2 1 complex 1 negative
## 3 1 death 1 negative
## 4 1 died 1 negative
## 5 1 good 2 positive
## 6 1 illness 1 negative
## 7 1 killed 2 negative
## 8 1 like 2 positive
## 9 1 liked 1 positive
## 10 1 miracle 1 positive
## # ... with 30,084 more rowsAssociated Press’deki kelimelerden hangilerinin olumlu ya da olumsuz duygulara katkıda bulunduğunu aşağıda görselleştirelim.
library(ggplot2)
ap_sentiments %>%
count(sentiment, term, wt = count) %>%
ungroup() %>%
filter(n >= 200) %>%
mutate(n = ifelse(sentiment == "negative", -n, n)) %>%
mutate(term = reorder(term, n)) %>%
ggplot(aes(term, n, fill = sentiment)) +
geom_bar(stat = "identity") +
ylab("Contribution to sentiment") +
coord_flip()
Bing duygu sözlüğü ile en çok kullanılan olumlu kelimelerin “like”, “work”, “support” ve “good” olduğunu, en olumsuz kelimelerin ise “killed”, “death” ve “vice” olduğunu görüyoruz.
5.1.2. Döküman-Özellik Matrisi (DFM – Document-Feature Matrix) Nesnelerini Düzenli Hale Getirme
Diğer bir metin madenciliği paketi olan “quanteda” paketi alternatif bir döküman-terim matrisi uygulaması olarak döküman-özellik matrisini (document-feature matrix – dfm) sunar.
quanteda paketi dfm ile ABD başkanlık meclis açılış konuşmalarını analiz edeim.
data("data_corpus_inaugural", package = "quanteda")
inaug_dfm <- quanteda::dfm(data_corpus_inaugural, verbose = FALSE)
inaug_dfm## Document-feature matrix of: 58 documents, 9,405 features (91.8% sparse).tidy() fonksiyonu döküman-özellik matrisi ile de çalışır.
inaug_td <- tidy(inaug_dfm)
inaug_td## # A tibble: 44,895 x 3
## document term count
## <chr> <chr> <dbl>
## 1 1789-Washington fellow-citizens 1
## 2 1797-Adams fellow-citizens 3
## 3 1801-Jefferson fellow-citizens 2
## 4 1809-Madison fellow-citizens 1
## 5 1813-Madison fellow-citizens 1
## 6 1817-Monroe fellow-citizens 5
## 7 1821-Monroe fellow-citizens 1
## 8 1841-Harrison fellow-citizens 11
## 9 1845-Polk fellow-citizens 1
## 10 1849-Taylor fellow-citizens 1
## # ... with 44,885 more rowsAçılış konuşmalarının her birine özgü kelimeleri bulmak ilgimizi çekebilir. Bunu da bind_tf_idf() ile tf-idf’in hesaplanmasıyla ölçülebilir .
inaug_tf_idf <- inaug_td %>%
bind_tf_idf(term, document, count) %>%
arrange(desc(tf_idf))
inaug_tf_idf## # A tibble: 44,895 x 6
## document term count tf idf tf_idf
## <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 1793-Washington arrive 1 0.00680 4.06 0.0276
## 2 1793-Washington upbraidings 1 0.00680 4.06 0.0276
## 3 1793-Washington violated 1 0.00680 3.37 0.0229
## 4 1793-Washington willingly 1 0.00680 3.37 0.0229
## 5 1793-Washington incurring 1 0.00680 3.37 0.0229
## 6 1793-Washington previous 1 0.00680 2.96 0.0201
## 7 1793-Washington knowingly 1 0.00680 2.96 0.0201
## 8 1793-Washington injunctions 1 0.00680 2.96 0.0201
## 9 1793-Washington witnesses 1 0.00680 2.96 0.0201
## 10 1793-Washington besides 1 0.00680 2.67 0.0182
## # ... with 44,885 more rowsBu veriden ABD Başkanları Lincoln, Roosevelt, Kennedy ve Obama’yı karşılaştırmak iiçn görselleştirme yapalım.
ABD Başkanlarının konuşmalarındaki en yüksek tf-idf’ye sahip kelimeler,
inaug_tf_idf %>% filter(document %in% c("1861-Lincoln","1933-Roosevelt","1961-Kennedy","2009-Obama")) %>%
arrange(desc(tf_idf)) %>%
mutate(term = factor(term, levels = rev(unique(term)))) %>%
group_by(document) %>%
top_n(15) %>%
ungroup %>%
ggplot(aes(term, tf_idf, fill = document)) +
geom_col(show.legend = FALSE) +
labs(x = NULL, y = "tf-idf") +
facet_wrap(~document, ncol = 2, scales = "free") +
coord_flip()## Selecting by tf_idf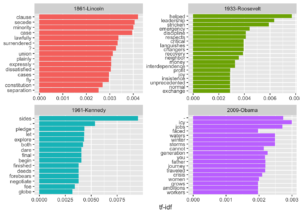
Düzenli verilerle mümkün olan bir görselleştirme örneği daha yapalım. Her bir belgenin yıllara göre ayrılmasıyla, hey yıl içerisindeki toplam kelime sayısını gösterelim.
Tidyr’in complete() fonksiyonunu, veri setindeki sıfırları (yani bir kelimenin bir dökümanda görünmediği durumlar) içerecek şekilde kullandığımızı unutmayalım.
library(tidyr)
year_term_counts <- inaug_td %>%
extract(document, "year", "(\\d+)", convert = TRUE) %>%
complete(year, term, fill = list(count = 0)) %>%
group_by(year) %>%
mutate(year_total = sum(count))Bu da kelimeleri seçmemize ve aşağıdaki grafikteki gibi zaman içinde frekansların nasıl değiştiklerini görselleştimemize olanak tanır. Zaman içinde Amerikan Başanlarının ülkeye “Union” yani “Birlik” olarak gönderme yapma ihtimalinin düşük olduğunu ve “America” için gönderme yapma olasılıklarının daha yüksek olduğunu görebiliriz. Ayrıca “constitution” (“anayasa”) ve “foreign” (“yabancı”) ülkeler hakkında ve “fredom” (“özgürlük”) ve “God” (“Tanrı”) ’dan söz etme olasılıklarının daha düşük olduğu da görülüyor.
year_term_counts %>%
filter(term %in% c("god", "america", "foreign", "union", "constitution", "freedom")) %>%
ggplot(aes(year, count / year_total)) +
geom_point() +
geom_smooth() +
facet_wrap(~ term, scales = "free_y") +
scale_y_continuous(labels = scales::percent_format()) +
ylab("% frequency of word in inaugural address")## `geom_smooth()` using method = 'loess' and formula 'y ~ x'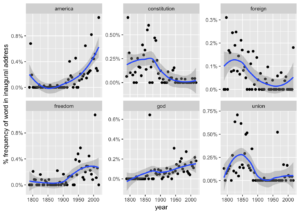
Yukarıdaki grafik ABD Başkanlık açılış konuşmalarında zaman içinde kullanılan kelime sıklığındaki değişikliklerdir.
Bu örnekler ile veri kaynakları düzenli bir biçimde olmasa bile veri kaynaklarını analiz etmek için tidytext’i ve ilgili diğer düzenleme araçları (tidy tools) nasıl kullanabileceğinizi göstermektedir.
5.2. Düzenli Metni Bir Matrise Aktarmak
Bazı metin madenciliği paketleri, örnek veri veya çıktı olarak doküman-terim matrisleri sağladığından, bazı algoritmalar bu matrisleri girdi olarak bekler. Bu nedenle, cast_ ile tidytext düzenli bir formdan bu matrislere dönüştürmek için işlevler sağlar .
Örneğin, düzenli hale getirilmiş Associated Press veri kümesini ele alıp, cast_dtm() fonksiyonu ile doküman-terim matrisine geri gönderebiliriz .
ap_td %>%
cast_dtm(document, term, count)## Warning: Trying to compute distinct() for variables not found in the data:
## - `row_col`, `column_col`
## This is an error, but only a warning is raised for compatibility reasons.
## The operation will return the input unchanged.## <<DocumentTermMatrix (documents: 2246, terms: 10473)>>
## Non-/sparse entries: 302031/23220327
## Sparsity : 99%
## Maximal term length: 18
## Weighting : term frequency (tf)Benzer bir şekilde, veriyi cast_dfm() fonksiyonu ile bir dfm nesnesine dönüştürbiliiz.
ap_td %>%
cast_dfm(document, term, count)## Warning: Trying to compute distinct() for variables not found in the data:
## - `row_col`, `column_col`
## This is an error, but only a warning is raised for compatibility reasons.
## The operation will return the input unchanged.## Document-feature matrix of: 2,246 documents, 10,473 features (98.7% sparse).Bazı yöntemler için sadece seyrek (sparse) bir matris gerekir.
library(Matrix)
# Matris nesnesine aktarma
m <- ap_td %>%
cast_sparse(document, term, count)## Warning: Trying to compute distinct() for variables not found in the data:
## - `row_col`, `column_col`
## This is an error, but only a warning is raised for compatibility reasons.
## The operation will return the input unchanged.class(m)## [1] "dgCMatrix"
## attr(,"package")
## [1] "Matrix"dim(m)## [1] 2246 10473Bu tür dönüşümler, şuana kadar kullandığımız düzenli metin yapılarından kolayca yapılabilir. Örneğin, Jane Austen’in kitaplarının sadece birkaç satırında bir DTM oluşturmak istersek;
library(janeaustenr)
austen_dtm <- austen_books() %>%
unnest_tokens(word, text) %>%
count(book, word) %>%
cast_dtm(book, word, n)## Warning: Trying to compute distinct() for variables not found in the data:
## - `row_col`, `column_col`
## This is an error, but only a warning is raised for compatibility reasons.
## The operation will return the input unchanged.austen_dtm## <<DocumentTermMatrix (documents: 6, terms: 14520)>>
## Non-/sparse entries: 40379/46741
## Sparsity : 54%
## Maximal term length: 19
## Weighting : term frequency (tf)cast süreci dplyr ve diğer tidy tools (düzenli araçlar) ile veri üzerinde tarama, filtreleme ve işleme yapılmasına izin verir. Bu işlemlerden sonra, veriler, makine öğrenimi uygulamaları için bir doküman-terim matrisine dönüştürülebilir. 6. Bölümde, düzenli metin veri setini işlemek için bir Document-Term Matrix’e dönüştürülmesi gereken bazı örnekleri inceleyeceğiz.
5.3. Meta Veri ile Korpus Nesnelerini Düzenleme
Bazı veri yapıları , genellikle “corpus” (korpus) olarak adlandırılan ve parçalara ayırmadan önce döküman koleksiyonlarını depolamak için tasarlanmıştır.
tm paketinden yaygın bir örnek olark korpus nesnelerine bakalım. İnceleyeceğimiz metin , her bir döküman için bir kimlik numarası (ID), tarih (date) / zaman (time), başlık (title) veya dil (language) içerebilen meta verileri depolar.
Örnek olarak, tm paketinden acq verisi, haber servisi Reuters’ten 50 makale içeren korpus ile birlikte gelir.
data("acq")
acq## <<VCorpus>>
## Metadata: corpus specific: 0, document level (indexed): 0
## Content: documents: 50Bir korpus nesnesi, hem metin hem de meta veri içeren bir liste gibi yapılandırılmıştır. Bu da dökümanlar için esnek bir depolama yöntemidir, ancak düzenli araçlarla işlenmesine katkıda bulunmaz.
Böylelikle tidy() fonksiyonu ile meta verileri döküman başına bir satır olarak oluşturalım.
acq_td <- tidy(acq)
acq_td## # A tibble: 50 x 16
## author datetimestamp description heading id language origin
## <chr> <dttm> <chr> <chr> <chr> <chr> <chr>
## 1 <NA> 1987-02-26 17:18:06 "" COMPUTER… 10 en Reute…
## 2 <NA> 1987-02-26 17:19:15 "" OHIO MAT… 12 en Reute…
## 3 <NA> 1987-02-26 17:49:56 "" MCLEAN'S… 44 en Reute…
## 4 By Cal… 1987-02-26 17:51:17 "" CHEMLAWN… 45 en Reute…
## 5 <NA> 1987-02-26 18:08:33 "" <COFAB I… 68 en Reute…
## 6 <NA> 1987-02-26 18:32:37 "" INVESTME… 96 en Reute…
## 7 By Pat… 1987-02-26 18:43:13 "" AMERICAN… 110 en Reute…
## 8 <NA> 1987-02-26 18:59:25 "" HONG KON… 125 en Reute…
## 9 <NA> 1987-02-26 19:01:28 "" LIEBERT … 128 en Reute…
## 10 <NA> 1987-02-26 19:08:27 "" GULF APP… 134 en Reute…
## # ... with 40 more rows, and 9 more variables: topics <chr>,
## # lewissplit <chr>, cgisplit <chr>, oldid <chr>, places <list>,
## # people <lgl>, orgs <lgl>, exchanges <lgl>, text <chr>Bundan sonra unnest_tokens() ile 50 Reuters makalesindeki veya her makaledeki özgü olanlarda en yaygın kelimeleri bulalım.
acq_tokens <- acq_td %>%
select(-places) %>%
unnest_tokens(word, text) %>%
anti_join(stop_words, by = "word")
# en yaygın kelimeler
acq_tokens %>%
count(word, sort = TRUE)## # A tibble: 1,566 x 2
## word n
## <chr> <int>
## 1 dlrs 100
## 2 pct 70
## 3 mln 65
## 4 company 63
## 5 shares 52
## 6 reuter 50
## 7 stock 46
## 8 offer 34
## 9 share 34
## 10 american 28
## # ... with 1,556 more rows# tf-idf
acq_tokens %>%
count(id, word) %>%
bind_tf_idf(word, id, n) %>%
arrange(desc(tf_idf))## # A tibble: 2,853 x 6
## id word n tf idf tf_idf
## <chr> <chr> <int> <dbl> <dbl> <dbl>
## 1 186 groupe 2 0.133 3.91 0.522
## 2 128 liebert 3 0.130 3.91 0.510
## 3 474 esselte 5 0.109 3.91 0.425
## 4 371 burdett 6 0.103 3.91 0.405
## 5 442 hazleton 4 0.103 3.91 0.401
## 6 199 circuit 5 0.102 3.91 0.399
## 7 162 suffield 2 0.1 3.91 0.391
## 8 498 west 3 0.1 3.91 0.391
## 9 441 rmj 8 0.121 3.22 0.390
## 10 467 nursery 3 0.0968 3.91 0.379
## # ... with 2,843 more rows5.4. Özet
Metin analizinde çoğunlukla düzenli bir yapıda olmayan verileri, çeşitli araçlarla düzenli hale getirmeyi amaçlanır. Bu bölümde, düzenli bir metin veri çerçevesi ve seyrek döküman-terim matrisleri arasında nasıl dönüştürüleceğini ve döküman meta verilerini içeren bir korpus nesnesinin nasıl düzenli hale getirileceği anlatılmıştır.
Bir sonraki bölüm, bahsi geçen dönüştürme araçlarının metin analizinin önemli bir parçası olduğunu anlayacağımız bir bölüm olacak.