
Hadoop HDFS Nedir?
 (No Ratings Yet)
(No Ratings Yet)HDFS Hadoop projesinin en temelinde bulunan çok büyük hacimli verileri depolamak için tasarlanmış java tabanlı dağıtık bir dosya sistemidir.
Hatalara karşı dayanıklıdır.
Ölçeklenebilir.
Düşük maliyetlidir.
Büyük veriler için idealdir.
HDFS Öne Çıkan Özellikler
Bir kez yaz defalarca oku
Özel bir donanım istemez, marka bağımsız
Anında cevap beklenen uygulamalar için ideal değil
Büyük verileri makul bir cevap süresinde işleme
Çok sayıda küçük boyutlu dosyayı sevmez. Namespace sınırı var.
Aşağıda günümüzde hala veri saklamada en büyük yükü çeken ve yıllardır boyunca kapasiteleri artsa da temel teknolojisi değişmeyen mekanik bir diskin içini görüyoruz. Namenode bu diskte gösterilen blok numaralarını ve içinde saklı olan dosya dizin isimlerini kendi ana belleğinde saklamaktadır.

HDFS Disk Blokları
Blok büyüklüğü 128/256 MB
Klasik dosya sisteminden farklı olarak bir bloğa 8 MB yazılsa 120 MB’lik alan boş görünür.
Blok büyüklüğünün büyük olmasının sebebi okuyucu kafanın izi ve blok başını bulma zamanını (seek time) azaltmaktır. Seek time okuyucu kafanın bloğun bulunduğu ize ve izdeki blok başlangıcına gelmesi için geçen zamandır. Bloklar ne kadar küçük ve farklı izlerde olursa erişim zamanı o kadar artacaktır. Küçük dosyalarda seek time okuma zamanından fazla olabilmektedir.
Dosya genişliği diskten büyük olabilir çünkü tüm dosya tek bir diske sığmak zorunda değil.
Blok mantığı replikasyonu, hataya dayanıklılığı ve veri yönetimini kolaylaştırır.
Namenode ve Datanode
Namenode: İsim alanını tutar, master node, üzerinde fiziksel veri saklamaz ancak nerede ne saklanır hepsini bilir.
Datanode: Veriyi saklar, köledir, işin bizzat icracısıdır. Düzenli olarak Namenode’a blok listesi gönderir.
Namenode olmadan dosyası sistemi çalışmaz. Bu sepeple onu korumak önemli. Bunun da iki yolu var: Dosya sisteminin yedeklelerini Namenode’un diskinden almak. Secondary Namenode: Genelde farklı bir fiziksel sunucuda çalışır. Çünkü yoğun işlemci ve bellek kullanımına ihtiyacı vardır. Periyodik olarak namespace imajı ile edit loğlarını birleştirerek diske yazar ki edit log ları aşırı büyümesin. Birleştirilmiş namespase imajını saklar. Aşağıdaki çizimde HDFS çalışma mantığı ve temel bileşenleri basit bir şekilde gösterilmeye çalışılmıştır.

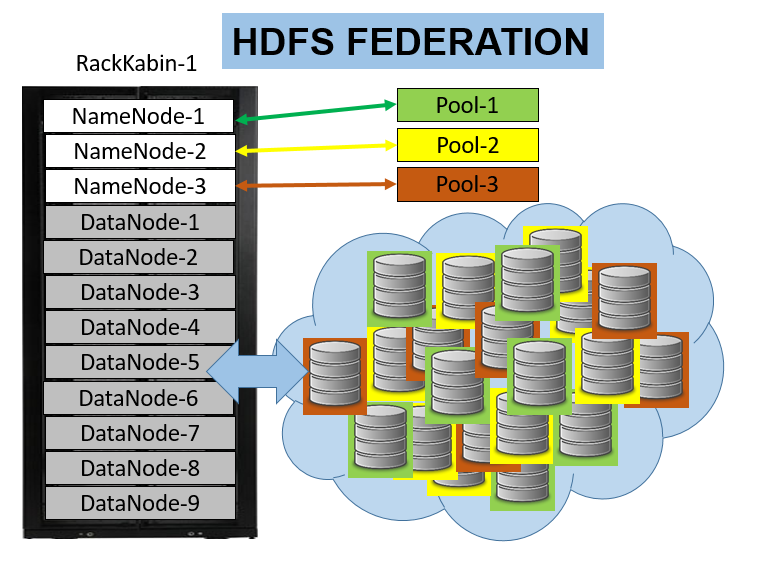
HDFS Federation
Namenode dosya sistemindeki her bir dosya ve dizin için ana bellekte bir referans tutar. Bu sebeple cluster büyüdükçe ve dosya/dizin sayısı çoğaldıkça cluster büyüklüğü Namenode ana belleği tarafından sınırlanır. Hadoop 2.X ile beraber bu sınıra bir özüm gelmiştir: İlave Namenode’lar eklenir ve her bir nemenode namespace ağacının belirli yerlerini saklar. Örneğin Namenode1 /user diznini tutarken Namenode2 kalan dizinleri tutabilir. Böylelikle her bir namenode farklı bir isim alanını ve bu alanla ilgili metadata ve blok havuzlarını (block pool) yönetir. Bir namenode arızalansa bile diğer namenode ların alanları ve dizin/dosyaları çalşmaya devam eder. HDFS’e ulaşmak isteyen clientlar hangi dizinin hangi namenode tarafından yönetildiğini client-side mount tables sayesinde bilirler.
HDFS High Availability
Secondary Namenode kullanmak veri kaybını engellese bile namenode hizmetinin sürekliliğini tam sağlayamaz. Namenode arızalandığında çalışan bütün işler duracağı gibi tekrar namenode hizmetinin aktif hale gelmesi yarım saat belki daha da fazla bir zaman alabilir. Çünkü cluster yöneticisi yeni bir namenode a metadatayı aktaracak ve datanode lara işte yeni namenodu’nuz budur diye bildirmek zorunda kalacaktır. Arıza olmasa bile bakım için yeni bir namenode hazırlamak sııntılı olabilir. Hadoop2.X bu sorunu yüksek erişilebilirlik (High Availability) ile çözmüştür. Bu çözümde active-standby durumunda bekleyen iki tane namenode bulunur. Aktif olan arızıalndığında standby durumunda olan derhal onun görevini üstlenir ve böylelikle hizmet aksamaz. Bu modde secondary namenode görevi (periyodik checkpoint) standby namenode tarafından yürütülür.
Quorum Journal Manager (QJM) edit logların yüksek erişilebilirlikte olmasını sağlayan sistemdir. QJM ZooKeeper’a benzer bir mantıkla çalışır. Bu durum Zookeeper’a olan ihtiyacı ortadan kaldırmaz. Zookeper HA modunda hangi sunucunun aktif namenode olduğunun güncel durum bilgisini tutar.


