
Keras Derin Öğrenme Kütüphanesi ile Sınıflandırma: Iris Veri Seti Üzerinde Uygulama
 (1 votes, average: 5,00 out of 5)
(1 votes, average: 5,00 out of 5)Merhaba. Bu yazımızda son yıllarda çok popüler bir konu olan derin öğrenme ile basit bir sınıflandırma uygulaması yapacağız. Derin öğrenmenin temelinde yapay sinir ağları bulunmaktadır. Uygulamamızda veri seti olarak Iris veri setini, sınıflandırıcı olarak da yapay sinir ağını kullanacağız. Programlama dilimiz Python, temel kütüphenelerimiz scikit-learn, tensorflow, keras olacaktır. Iris veri setini bu yazı ile daha yakından tanıyabilirsiniz. Veri setini buradan indirebilirsiniz. Yazının temel amacı yapay sinir ağlarına temel düzeyde uygulamalı giriş yapmaktır. Bu sebeple kodlarda yer alan bazı fonksiyon ve parametrelerin niçin kullanıldığı ve alternatiflerinin neler olduğuna detaylı olarak değinilmemiştir.
Kütüphaneleri İndirme ve Veriyi Yükleme
# Temel Kütüphaneler
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# Iris veri seti
dataset = pd.read_csv("D:\\Datasets\\iris.csv")
# Aynı sonuçlar için random seed
seed = 7
np.random.seed(seed)
Veri Seti Keşfi
# veri setine bakış dataset.head() #Sonuç 5.1 3.5 1.4 0.2 Iris-setosa 0 4.9 3.0 1.4 0.2 Iris-setosa 1 4.7 3.2 1.3 0.2 Iris-setosa 2 4.6 3.1 1.5 0.2 Iris-setosa 3 5.0 3.6 1.4 0.2 Iris-setosa 4 5.4 3.9 1.7 0.4 Iris-setosa
Veri setinde sütun isimleri yokmuş. Hadi ekleyelim.
iris_cols = ['sepal-length', 'sepal-with', 'pedal-length','pedal-width','label'] dataset.columns = iris_cols # Doğru eklemiş miyiz bakalım: dataset.head() #Sonuç sepal-length sepal-with pedal-length pedal-width label 0 4.9 3.0 1.4 0.2 Iris-setosa 1 4.7 3.2 1.3 0.2 Iris-setosa 2 4.6 3.1 1.5 0.2 Iris-setosa 3 5.0 3.6 1.4 0.2 Iris-setosa 4 5.4 3.9 1.7 0.4 Iris-setosa
Bağımlı ve Bağımsız Değişkenleri Ayırma
Python’da sütunların indeks değeri 0’dan başladığından ve veri setinde 5 sütun olduğundan ilk niteliğin indeksi 0, son niteliğin 4 olacaktır. iloc[] ile sütun seçerken ilk değer dahil ikinci değer hariçtir. Bu sebeple nitelikler matrisini (X) seçerken 0’ı dahil, 4’ü hariç tutacağız. Çünkü son indeks değeri label yani hedef değişkene aittir. iloc[] içindeki İlk iki nokta (:) tüm satırları ifade ederken virgül sonrası, sütunlardan seçilecek filtreyi ifade eder. 0:4 demek 0 dahil 4 hariç indeksli sütunları seç demek, yani 0,1,2,3.
X = dataset.iloc[:,0:4].values # Hedef niteliğimiz 4. indekste idi. O sebeple : ile tüm satırları "," den sonra 4 ile hedef niteliğin indeksini seçiyoruz. y = dataset.iloc[:,4].values
iloc[] ile seçim yaptıktan sonra values eklemeyi unutmayınız aksi halde X pandas.Dataframe y ise pandas.Series türünde kalır.
Kategorik Nitelikleri Dönüştürmek
Veri setimizin nitelikleri tamamen nümerik. Ancak hedef değişkenimiz kategorik. Onu nümerik hale getirmeliyiz. Hatta gölge değişken oluşturmalıyız.
from sklearn.preprocessing import LabelEncoder from keras.utils import np_utils # Kategorik olan hedef değişkeni nümerik yap encoder = LabelEncoder() y= encoder.fit_transform(y) # Nümerik hedef değişkenden gölge değişkenler yarat y = np_utils.to_categorical(y)
Veri Setini Eğitim ve Test Seti olarak Ayırmak
Veri setini eğitim ve test olarak ayırmanın bazı yolları var. Biz burada scikit learn kütüphanesimodel_selection modülünden basit olan train_test_split fonksiyonunu kullanacağız.
from sklearn.model_selection import train_test_split #Sıralamaya dikkat. Aynı sonuçlar için random_state değeri aynı olmalıdır. X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=0)
Feature Scaling
Yapay Sinir Ağı girdi olarak niteliklerin standardize edilmiş hallerini istiyor. Bunun için nitelikler matrisini (X), scikit learn kütüphanesi preprocessing modülü StandardScaler sınıfını kullanarak standardize edeceğiz. Aslında niteliklerin hepsi aynı türden (cm) alındığı için yapay sinir ağı veri setini standardize etmeden de çalışır ancak bu başarı oranı daha düşük sonuçlar elde ederiz. Ben denedim, arasında ciddi bir fark var.
from sklearn.preprocessing import StandardScaler scaler = StandardScaler() X_train = scaler.fit_transform(X_train) X_test = scaler.transform(X_test)
Yapay Sinir Ağı Başlangıç
Not: Bu aşamadan sonraki uygulamalar için theano, tensorflow ve keras kütüphaneleri bilgisayarınıza kurulmuş olmalıdır. Eğer bilgisayarınızda pip yüklü ise pip install keras gibi basit komutlarla kurabilirsiniz.
# Keras kütüphanelerini indirme import keras from keras.models import Sequential from keras.layers import Dense
Yapay Sinir Ağı Nesnesi Oluşturma
Yapay sinir ağı iki farklı şekilde başlatılabilir: 1. Katmanlar dizilimi (Sequantial layers) olarak. 2. Graph olarak. Bu yazıda ilk yöntem kullanılacaktır. Bu yöntem için sadece yukarıda indirilen Sequantial sınıfından nesne yaratılır. Bu nesne, Karar ağacı, SVM gibi bir Sınıflardan çok da farklı olmayan bir nesne aslında.
classifier = Sequential()
Bir Sinir Ağını Stochastic Gradient Descent ile Eğitmenin Aşamaları
- Sıfıra yakın rastgele değerler ile ağırlık katsayılarını (W) belirle.
- Girdi katmanına (Input Layer) ilk gözlemi(bir satır) her bir düğüme bir nitelik (nitelikler matrisi sütün sayısı kadar) düşecek şekilde ver.
- Ağı çalıştır ve ilk tahmin y değerini üret.
- Üretilen y ile gerçek y arasındaki hatayı hesapla.
- Hesaplanan hatayı geri besleme olarak ağa gönder ve her bir ağırlık katsayısını (W) güncelle.
- 1 ve 5 arasını ya her bir satırdan sonra veya belli bir satır sayısından (batch) sonra tekrarla.
- Tüm veri setinin bir tur çalışması bir epoch demektir. Bunu defalarca tekrarla.
Yapay Sinir Ağına Girdi ve Gizli Katman Ekleme
classifier nesnesinin add() metodu içine Dense sınıfını nesne yaratarak parametre veriyoruz. Dense içindeki ilk parametre kernel_initializer (eski init): Başlangıç ağırlıklarını belirler. Tensor’ları oluşturmak/başlatmak için uniform dağılımını temsilen uniform parametresini kullanıyoruz. input_dim: Yapay sinir ağı nesnesine ilk katman ekleme işlemi yapılırken mutlaka girdi katmanında kaç düğüm olacağı bildirilir. Aksi halde ilk gizli katman kendisine kaç düğümden bağlantı olacağını bilemez. Bu rakam nitelikler matrisindeki sütun sayısıdır, bu örnekte 4. units (eski:output_dim): Bu sayının nasıl verileceğine dair sağlam bir kural yok. Biraz sanatkarlık ve tecrübe gerektiriyor. Örneğin; girdi ve çıktı düğüm sayısının ortalamasını verebilirsiniz. Bu örnekte (4+3=7/2=3,5 ~ 4). Ya da parametre tuning tekniklerini kullanabilirsiniz. activation: Gizli düğümler için rectifier, çıktı düğüm için softmax olsun. Rectifier aktivasyonu kütüphanede relu olarak tanımlıdır. Daha fazla bilgi için keras sitesine bakabilirsiniz.
classifier.add(Dense(kernel_initializer = 'uniform', input_dim = 4, units = 4, activation = 'relu'))
Çıktı Katmanı (Output Layer) Ekleme
Bu katmanın bir öncekinden farkı düğüm sayısı ve activasyon fonksiyonu olacak. Hedef değişken üç farklı değer aldığı için units=3 veriyoruz.
classifier.add(Dense(kernel_initializer = 'uniform', units = 3, activation = 'softmax'))
Ağımızın yapısı aşağıdaki şekilde gibidir.
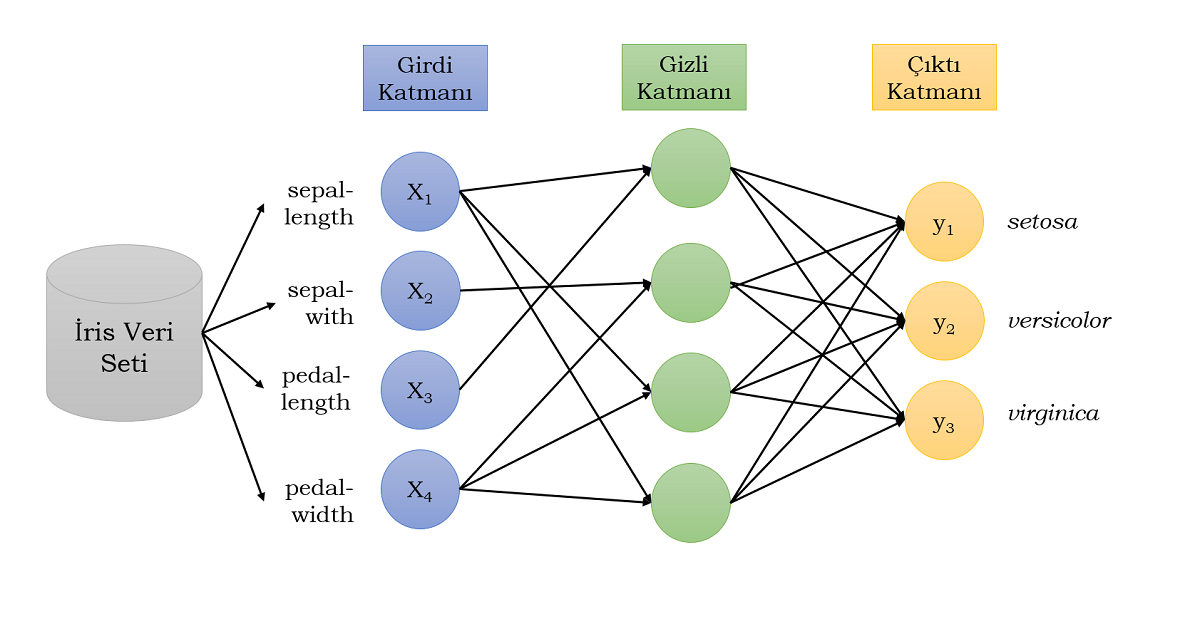
Yapay Sinir Ağını Derleme
Tüm hazırlıklar tamamlandı. Şimdi yapay sinir ağı nesnemizi (classifier) eğitebiliriz. Ancak bundan önce son olarak onu derlememiz gerekiyor. Bunun için compile() metodunu kullanacağız. Method için kullanılacak parametreleri açıklayalım: optimizer: Stochastic Gradient Descent (SGD)’i temsilen adam. loss: SGD’nin optimizasyonu için kullanılacak loss function. Tahmin y ile gerçek ye değeri arasını hesaplayıp en optimal değeri SGD’ye buldurur. Çok sınıflı bir hedef değişken olduğu için categorical_crossentropy kullanıyoruz. metrics: İlave olarak burada model değerlendirme kriterleri belirlenir. Bir liste halinde verilir. Biz şimdilik sadece accuracy kullanıyoruz.
classifier.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
Yapay Sinir Ağını Eğitme
classifier.fit(X_train, y_train, batch_size=5, epochs=100) # Çıktı Epoch 1/100 119/119 [==============================] - 0s 3ms/step - loss: 1.0985 - acc: 0.3445 Epoch 2/100 119/119 [==============================] - 0s 227us/step - loss: 1.0952 - acc: 0.3697 Epoch 3/100 119/119 [==============================] - 0s 244us/step - loss: 1.0855 - acc: 0.5966 Epoch 4/100 119/119 [==============================] - 0s 202us/step - loss: 1.0664 - acc: 0.6807 ... ... ... 119/119 [==============================] - 0s 256us/step - loss: 0.1519 - acc: 0.9580 Epoch 99/100 119/119 [==============================] - 0s 231us/step - loss: 0.1502 - acc: 0.9580 Epoch 100/100 119/119 [==============================] - 0s 219us/step - loss: 0.1476 - acc: 0.9580
Yukarıda gördüğümüz gibi % 95 bir başarı ile iris çiçeğinin yaprak uzunluklarından irisin üç türünden hangisine ait olduğunu tahmin etti. Elbette bu değer eğitim seti üzerinden elde edilen değer. Bunu ayrıca test setinde denemeliyiz.
Test Verisi ile Modeli Denemek
Eğitim verisi üzerinde accuracy başarısı % 95.80 olan modelimiz bakalım daha önce hiç görmediği test verisi üzerinde nasıl bir başarı gösterecek. Bunun için classifier nesnemizin predict() metodunu kullanıyoruz. burada elde edeceğimiz değerleri tahmin edilen anlamında y_pred değişkenine atıyoruz.
y_pred = classifier.predict(X_test)
İkiden çok etiketli sınıflarda accuracy hesaplamak için scikit learn kütüphanesi metrics modülü accuracy_score fonksiyonunu kullanıyoruz.
from sklearn.metrics import accuracy_score accuracy_score(y_test, y_pred.round(), normalize=True) # Çıktı: 0.90
Tahmin ettiğimiz gibi test seti üzerinde elde edilen accuracy değeri eğitim setinde elde edilenden düşük çıktı.
Kapak resmi kaynak: http://www.webtunix.com/deep-learning-services
Yararlanılan kaynaklar: https://www.udemy.com/deeplearning/learn/v4/overview
https://keras.io/
http://scikit-learn.org/stable/index.html
Kodlar Github:




Hocam; açık, anlaşılabilir ve verimli bir çalışma olmuş. Elinize sağlık .
Hocam çok güzel bir çalışma olmuş elinize sağlık