
Ensemble Yöntemler (Topluluk Öğrenmesi): Basit Teorik Anlatım ve Python Uygulama

 (2 votes, average: 4,50 out of 5)
(2 votes, average: 4,50 out of 5)1. Enseble Yöntemler Nedir? Bir Benzetme
Sınıflandırma algoritmaları ile bir nesnenin hangi sınıfa dahil olacağını tahmin etmeye çalışırız. Birçok sınıflandırma yöntemi arasından probleme uygun olanı seçer, gerekli optimizasyonları yapar ve yüksek doğruluk oranlarını yakalamaya çalışırız. Peki bu işi 3-5 tane sınıflandırıcı ile yapsak veya aynı sınıflandırıcıyı aynı eğitim setinin farklı alt kümeleri ile eğitsek ve her birine sen ne diyorsun kardeşim diye sorsak nasıl olur? Daha iyi olmaz mı? İşte Ensemble yöntemler (sınıflandırıcı topluluklar/topluluk öğrenme) bu işi yapıyor, aynı sınıflandırma görevinde birden fazla sınıflandırıcı kullanılıyor, bir nevi ortak akıl anlayacağımız. Bu yöntemde farklı doğruluk skorlarına sahip sınıflandırıcıların sonuçları farklı yöntemlerle (oylama, ortalama vb.) birleştiriliyor. Böylelikle tek bir sınıflandırıcıdan daha iyi sonuçlar elde etme imkanı bulunuyor. Bu yazımızda ensemble yöntemleri kavramaya yönelik teorik bilgilere değinecek, ensemble yöntemlerden bahsedecek ve Python ile küçük bir örnek yapacağız.
Konuyu daha iyi anlayabilmek için bir benzetme ile başlayalım:
Yıllardır pasaport gişesinde görev yapan memurlar artık pasaport kontrolü için gişeye yaklaşan insanların hal, hareket ve tavırlarından pasaport ile ilgili herhangi bir sıkıntısı olup olmadığını anlar olmuşlar. Kendilerince bir deney yapmışlar. Her memur gişeye yaklaşan yolcunun pasaport sıkıntısı olup olmadığını tahmin etmiş, sonra da bireysel tahminler grup tahminleri ile karşılaştırılmış. Sonuçta grup tahminlerinin birey tahminlerinden daha iyi olduğunu farketmişler. Şimdi analojimizi ensemble yönteme uyarlayalım. Birinci memur Karar Ağacı, ikinci memur Support Vector Machines (destek vektör makineleri) ve üçüncü memur da Lojistik Regresyon olsun. Yaklaşan bir yolcu için;
Birinci memur (Karar Ağacı): SIKINTILI
İkinci memur (Support Vector Machine): SIKINTI YOK
Üçüncü memur (Lojistik Regresyon): SIKINTILI
kararı veriyor. Çoğunluk SIKINTILI kararı verdiği için sonuç SIKINTILI kabul edilir ve yaklaşan yolcu pasaport kontrolü yönünden SIKINTILI olarak sınıflandırılır.
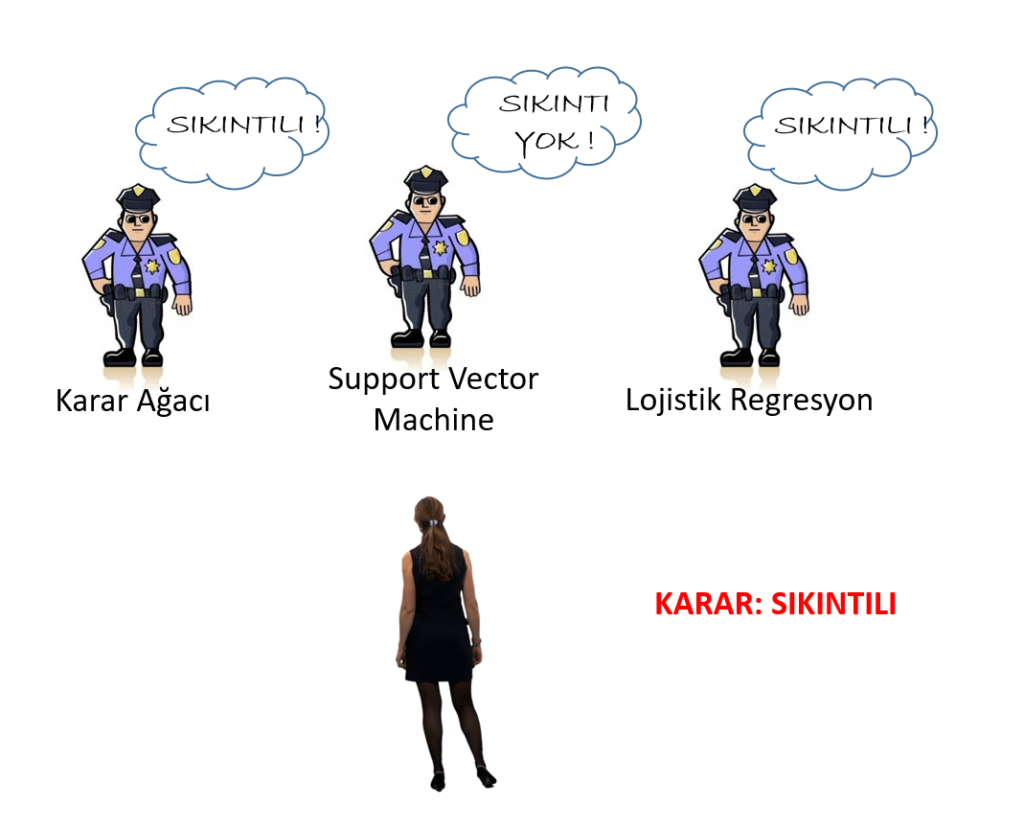
Sanırım sınıflandırıcı toplulukların/ensemble yöntemlerin ana fikri anlaşılmıştır. Sınıflandırıcı topluluklar sadece doğruluğu yükseltmekle kalmıyor aynı zamanda ezber bozuyor, sapma (bias) ve varyans hatasını azaltıyor. Konuyu biraz daha pekiştirmek için Random Forest’i örnek verebiliriz. Random Forest, aslında karar ağacının ensemble modelidir. Karar Ağacı sadece bir ağaç kullanılırken, Random Forest birden çok ağaç kullanır. Şunu da unutmamak gerekir; ensemble yöntem kullanıldığında sonuç tek bir sınıflandırıcıdan daha iyi olmalıdır aksi halde ensemble yöntem kullanmanın anlamı kalmaz. Çünkü tek bir sınıflandırıcıya göre ensemble yöntemin hesaplama maliyeti daha yüksektir.
Özetle söyleyecek olursak ensemble yöntemler; tek bir modele kıyasla daha güçlü ve genellenebilir sonuçlar elde etmek amacıyla birden fazla baz modelin tahmin sonuçlarını birleştirir. Bu yöntemlerin başarısı iki ölçüte göre olur; temel öğrenicilerin (base learner) öğrenme başarısı ve birbirlerinden farklılıklarıdır.
2. Ensemble Yöntemler Hangi Hallerde Kullanılır?
Tek bir algoritma ezbere başvurduğunda.
Elde edilecek sonuç ilave hesaplama yapmaya değecek kadar yüksekse.
3. Ensemble Yöntemler Nelerdir?
Başka yöntemlerde olmakla beraber yaygın olarak kullanılan yöntemler aşağıda listelenmiştir.
- Bagging
- Random Subsample
- Boosting
3.1. Bagging (Bootstrap Aggregating)
Bu yöntemde, temel öğrenicilerin (base learner) herbiri, eğitim setinin rastgele seçilen farklı alt kümeleriyle eğitilir. Veri, önce eğitim ve test olarak ayrılır. Daha sonra eğitim için ayrılan veri setinden rastgele seçim yapılır ve her bir öğrenicinin çantasına konur. Torbadan çekilen topun torbaya tekrar konması gibi seçilenler tekrar seçilebilecek şekilde eğitim kümesinde kalmaya devam eder. Seçilen miktar eğitim için ayrılandan fazla değildir (genelde %60). Farklı eğitim setlerinin seçilmesindeki amaç karar farklılıkları (model farklı eğitim setiyle oluşunca doğal olarak kararlarda da bir miktar farklılık oluşacaktır) elde ederek başarıyı yükseltmektir. Kararlar ağırlıklı oylama ile birleştirilir.
3.2. Random Subsample (Rastgele altuzaylar)
Bu yöntemde örneklerin seçimiyle ilgili bir kısıtlama yoktur. Burada her öğreniciye nitelikler kümesinin değişik alt kümeleriyle öğrenme yaptırılır. Yani eğitim esnasında bazı sütunlar seçilir bazıları seçilmez. Genelde niteliklerin yarısı seçilir. Yukarıda öğrenicilerin verdiği kararların birbirinden farklı olması gerektiğini söylemiştik. Rastgele altuzaylar için bu farklılık farklı niteliklerin seçimiyle sağlanıyor. Her öğrenicinin niteliklerin yarısı ile eğitildiği düşünülürse iki eğiticinin aynı nitelikleri kullanma olasılığı sadece dörtte bir olur. Kararlar ortalama ile alınır. Aynı sınıflandırıcı seçilebileceği gibi farklı sınıflandırıcılar da seçilebilir.
3.3. Boosting
Bagging yönteminin farklı bir versiyonudur. Fark; öğrenme sonuçlarının mütekip öğrenici için kullanılıyor olmasıdır. Diğer yöntemlere göre daha yaygındır, hızlı çalışır az bellek kullanır. Eğitim için ayrılan veri setinden bir temel öğrenici için rastgele seçim yapılır. Öğrenme gerçekleşir, model test edilir. Sonuçlardan yanlış sınıflandırılan örnekler belirlenir. Bunlar bir sonraki öğrenici için örnek seçiminde önceliklendirilir (seçilme olasılıkları arttırılır). Her seferinde bu bilgi güncellenir. Bagging yönteminde her bir örneğin seçilme şansı eşittir.
4. Python ile Örnek Uygulama
Python örnek uygulamamızda önce karar ağacı ile tek bir sınıflandırıcıyı kullanacağız. Daha sonra tek sınıflandırıcı ile ensemble yöntemlerin farklarını kıyaslamak için aynı veri seti ile Random Forest ve Bagging uygulaması yapacağız. Yazıya ait kodları GitHub depomuzdan bulabilirsiniz.
4.1. Karar Ağacı için Kütüphaneleri İndirme, Çalışma Dizinini Ayarlama, Veri Setini İndirme
import numpy as np import matplotlib.pyplot as plt import pandas as pd import os
Çalışma diznini ayarlayalım:
os.chdir('Sizin_Kendi_Dizniniz')
Pandas ile veri setini dosyadan okuyalım: Veri setini buradan indirebilirsiniz:SosyalMedyaReklamKampanyası
data = pd.read_csv('SosyalMedyaReklamKampanyasi.csv')

Veri setimizdeki 400 satırın 21 satırı yuklarıdaki resimde bulunmaktadır. Veri seti bir sosyal medya kayıtlarından derlenmiş durumda ve beş nitelikten oluşuyor. KullaniciID müşteriyi belirleyen eşsiz rakam, Cinsiyet, Yaş, Tahmini Gelir yıllık tahmin edilen gelir, SatinAldiMi ise belirli bir ürünü satın almış olup olmadığı, hadi lüks araba diyelim. Hedef nitelik (bağımlı değişken): SatinAldiMi’dir. Diğer dört nitelik ise bağımsız niteliklerdir (bağımsız değişkenler). Herhangi bir sınıflandırma modeli bağımsız nitelikleri kullanarak, bağımlı nitelik (satın alma davranışının gerçekleşip gerçekleşmeyeceği) tahmin edecektir.
4.2. Veri Setini Bağımlı ve Bağımsız Niteliklere Ayırmak
Yukarıda gördüğümüz niteliklerden bağımsız değişken olarak sadece yaş ve tahmini maaşı kullanacağız. SatinAldimi sütun indeks değeri 4 ve bunu y değişkenine (numpyArray) atıyoruz. Aynı şekilde yaş ve TahminiMaas sütun indeksleri 2 ve 3 bunu da X değişkenine(numpyArray) atıyoruz.
X = data.iloc[:, [2,3]].values y = data.iloc[:, 4].values

4.3. Veri Setini Test ve Eğitim Olarak Ayırma
Adet olduğu üzere veri setimizin bir kısmını modelimizi eğitmek için kullanacağız. Kalan kısmını ise eğitilen modelin testinde kullanacağız. Veriyi eğitim ve test olarak ayırmak için scikit-learn kütüphanesi cross_validation modülü içindeki train_test_split fonksiyonunu dahil edelim.
from sklearn.cross_validation import train_test_split
Yukarıda veri setimizi X ve y olarak niteliklerden (sütun bazlı bölme) ayırmıştık. Şimdi hem X hem de y’i satır bazlı ikiye bölelim. Satırların % 80’i eğitim, % 20’si test için ayıralım (test_size = 0.20 buna işaret ediyor). Aşağıdaki kodlarla X’ten rastgele seçilecek %80 satırı X_train‘e; kalan %20 ise X_test‘e atanır. Aynı şekilde y’den rastgele seçilecek %80 satırı y_train‘e; kalan %20 ise y_test‘e atanır. Yalnız bu seçim işlemi hepsinde aynı satırlar seçilecek şekilde yapılır. Örneğin X_train‘nin 5. satırı seçilmişse diğerlerinde de 5. satır seçilir. Başka bir deyişle her dört veri parçasındaki indeksler aynı müşteriye işaret etmektedir.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.20, random_state = 0)
4.4. Karar Ağacı Modelini Eğitme
Sınıflandırma için karar ağacı kullanılacak. Karar Ağacı modeli için scikit-learn kütüphanesi tree modülünden DecisionTreeClassifier sınıfını dahil edelim.
from sklearn.tree import DecisionTreeClassifier
Dahil ettiğimiz sınıftan bir nesne oluşturalım, sınıfın bir metodu olan fit() ile nesnemizi eğitelim (veriye uyduralım, veriyi kullanarak model oluşturalım)
decisionTreeObject = DecisionTreeClassifier() decisionTreeObject.fit(X_train,y_train)
4.5. Karar Ağacı Modelini Test Etme
Karar Ağacı modelimizi eğitim için ayırdığımız X_train ve y_train setleriyle eğittik. Şimdi test için ayırdığımız veriler ile doğruluk skorlarını hesaplayalım. Bunun için score() metodunu kullanacağız.
dt_test_sonuc = decisionTreeObject.score(X_test, y_test)
print("Karar Ağacı Doğruluk (test_seti): ",round(dt_test_sonuc,2))
Yukarıdaki kodun çıktısı:
Karar Ağacı Doğruluk (test_seti): 0.91
Doğruluk 0.91 gibi yüksek bir değer. Burnuma ezbercilik kokuları geliyor 🙂
4.6. Random Forest Modeli Oluşturma
Şimdi model oluşturma aşamasına kadar herşey aynı kalsın ve sadece modelimizi Karar Ağacı yerine Random Forest yapalım. Scikit-learn kütüphanesi, ensemble modülünden RandomForestClassifier sınıfını dahil edelim:
from sklearn.ensemble import RandomForestClassifier
Sınıf nesnemizi oluşturup, fit metodu ile nesnemizi eğitelim.
randomForestObject = RandomForestClassifier(n_estimators=10) randomForestObject.fit(X_train, y_train)
Test sonuçlarını hesaplayalım:
df_test_sonuc = randomForestObject.score(X_test, y_test)
print("Random Forest Doğruluk (test_seti): ",round(df_test_sonuc,2))
Yukarıdaki kodların çıktısı:
Random Forest Doğruluk (test_seti): 0.94
Bir ensemble yöntem temsilcisi olarak Random Forest daha yüksek doğruluk değerini yakaladı.
4.7. Ensemble Yöntemler Uygulama: Bagging
Yine model aşamasına kadar karar ağacı için kullandığımız herşeyi kullanalım. Scikit-learn kütüphanesi, ensemble modülünden BaggingClassifier sınıfını dahil edelim:
from sklearn.ensemble import BaggingClassifier
BaggingClassifier sınıfından yarattığımız modeli eğitelim.
baggingObject = BaggingClassifier(DecisionTreeClassifier(), max_samples=0.5, max_features=1.0, n_estimators=20) baggingObject.fit(X_train, y_train)
Şimdi bagging modelinin test sonuçlarına bakalım
baggingObject_sonuc = baggingObject.score(X_test, y_test)
print("Bagging Doğruluk (test_seti): ", round(baggingObject_sonuc,2))
Bagging Doğruluk (test_seti): 0.92
Evet gördüğümüz gibi Bagging sonucu(0.92) da kıl payı yüksek de olsa tek bir karar ağacından(0.91) daha yüksek çıktı. Bu yazımız da burada sona eriyor. Tekrar görüşmek dileğiyle, veriyle kalın…



“Yukarıda veri setimizi X ve y olarak niteliklerden (sütun bazlı bölme) ayırmıştık.” demişssiniz fakat yukarıda onun kodu yok. Bu nedenle x ve y oluşturamadım düzeltirseniz sevinirim teşekkürler
Merhaba. Evet doğru onu atlamışım çok iyi hatırlattınız. Şuan ekledim. Sorun olursa tekrar yazın lütfen. İlginiz için çok teşekkürler…
2 tane karar ağacı olsa ve her biri farklı sınıflandırma yapsa majority vote nolur? Yani ne şekilde bir sınıflandırma yapılır?
Merhaba. Kategorik ve sürekli yordayıcı değişkenlerden oluşan bir veri setinde (sürekli değişkenlerin değer aralıkları oldukça farklı olduğunda), bagging ve random forest algoritmalarında olduğu gibi, değişken seçim yanlılığı sorunu oluşur mu? Oluşuyorsa bu sorunu çözmek için neler yapılabilir? Teşekkürler…
Düzeltme: Az önceki sorumda, “boosting algoritmasında değişken seçim yanlılığı sorunu oluşur mu?” ifadesini eklememişim.