
Kafka Connect Nedir?
 (No Ratings Yet)
(No Ratings Yet)Kafka Connect, Apache Kafka’nın tamamlayıcı bir parçasıdır ve diğer sistemleri Kafka ile entegre eder. Örneğin Kafka Connect, değişiklikleri bir veritabanından (source) Kafka’ya aktarmak ve buradan başka bir veri depolama sistemine (sink) yazmak için kullanılabilir, böylelikle diğer uygulamaların/servislerin (örneğin dashboard) gerçek zamanlı veriye erişimini sağlar.
Kafka Connect, içinde Kafka’nın da vazgeçilmez bir parçası olduğu sağlam data pipelines oluşturmak ve çalıştırmak için bir runtime ve framework sağlar. Kafka Connect şimdiye dek bir çok zorlu koşulda denendi ve büyük ölçekte dayanıklı olduğunu kanıtladı. Kafka Connect bir JSON dosyasında data pipeline tanımlamanızı ve hiç kod yazmadan data pipelines başlatmanızı sağlar.
Kafka Connect’te pipelines ikiye ayrılır:
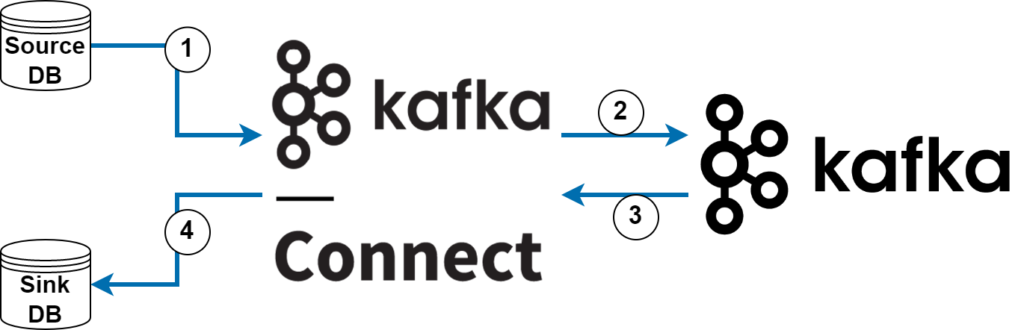
- Source pipelines: Dış sistemlerden Kafka’ya verinin getirilmesi (Şekil-1, 1 ve 2)
- Sink pipelines: Kafka’dan dış sistemlere verinin taşınması (Şekil-1, 3 ve 4)
Bu iki farklı pipeline için mutlaka bir taraf Kafka olmak zorundadır; source için bitiş, sink için başlangıç.
Kafka Connect Özellikleri
Kafka Connect’i data pipelines oluşturmak ve sistemleri entegre etmek için çok popüler bir platform haline getiren özelliklere daha yakından bakalım.
1. Pluggable Architecture
Kafka Connect, harici sistemlerden veriyi Kafka’ya esnek bir şekilde almak ve çıkarmak için temel bir mantık ve ortak bir API sağlar. Böylece bu temel mantık ve API üzerinde bir çok eklenti ile çalışabilir. Kafka topluluğu veritabanları, depolama sistemleri ve çeşitli ortak protokollerle etkileşim kurmak için yüzlerce eklenti oluşturmuştur. Bu, karmaşık işlere bile başlamayı hızlı ve kolay hale getirir. Mevcut eklentilerden hiçbiri ihtiyaçlarınızı karşılamıyorsa kendi eklentinizi bile yazabilirsiniz. Kafka Connect, bu eklentileri birleştirerek karmaşık pipelines oluşturmanıza olanak tanır. Pipeline tanımlamak için kullanılan eklentilere Konektör eklentileri (connector plug-ins) denir. Konektör eklentilerinin farklı türleri vardır:
• Source connectors: Harici sistemlerden Kafka’ya veri taşıma
• Sink connectors: Kafka’dan harici sistemlere veri taşıma
• Converters: Kafka ile harici sistemler arasında veri değiştirme (convert)
• Transformations: Kafka Connect içinden akan veriyi dönüştürme (transform)
• Predicates: Dönüştürme işlemini bir koşula bağlı olarak uygulama
Bir pipeline, tek bir konektör ve converter’dan oluşur ve opsiyonel transformations ve predicates eklenebilir. Aşağıda Şekil-2’de basit bir ETL pipeline görülmektedir. Bir tane source connector, bir transformation (a record filter) ve converter.

Connector plug-ins yanı sıra Kafka Connect’in kendisini özelleştirmek için kullanılan başka bir eklenti grubu daha vardır. Bunlara worker plug-ins denir:
• REST Extensions: REST API’yi özelleştirmek için.
• Configuration Providers: Konfigürasyonları çalışma zamanında dinamik olarak ayarlamak için.
• Connector Client Config Override Policies: Kullanıcıların konektör tarafından kullanılan Kafka client konfigürasyonlarından bazılarını değiştirebilmesini sağlar.
2. Scalability and Reliability
Kafka Connect ayrı bir cluster olarak Kafka cluster haricinde farklı sunucular üzerinde çalışır. Böylelikle Kafka’dan bağımsız olarak ölçeklenebilir. Connect cluster içindeki her bir sunucuya worker denir. Connect çalışırken yeni worker ekleyebilir veya çıkarabilirsiniz. Böylelikle yüke göre dinamik olarak kaynak dengelemesi yapabilirsiniz. Cluster içindeki worker’lar işbirliği yapar ve her biri iş yükünün bir kısmını üstlenirler. Bu, Kafka Connect’i çok güvenilir ve hatalara karşı dayanıklı (reliable and resilient) kılar çünkü bir worker çökerse diğerleri onun iş yükünü üstlenebilir.
3. Declarative Pipeline Definition
Kafka Connect, pipeline’ı bildirimsel (declerative) olarak tanımlamanıza olanak tanır. Bu, konektör eklentilerini kullanarak herhangi bir kod yazmadan olur. Pipelines, kullanılacak eklentileri ve bunların konfigürasyonlarını açıklayan JSON dosyalarıyla tanımlanır. Bu, veri mühendislerinin binlerce satır kod yazmadan karmaşık pipelines tasarlamalarını mümkün kılar. Daha sonra tanımlanan bu JSON dosyaları Connect’e REST API ile gönderilerek pipeline başlatılır. Elbette API ile sadece başlatma işi değil durdurma, duraklatma, durum inceleme, konfigürasyon değiştirme gibi operasyonlar da yapılır.
4. Connect Apache Kafka’nın Bir Parçasıdır
Connect kurup kullanmak için ayrıca bir binary indirmek zorunda değilsiniz. Kafka binary içinde Connect hazır gelir. Aynı dosyalarla Kafka da başlatabilirsiniz Connect de. Ancak Connect çalışmak için mutlaka bir Kafka’ya ihtiyaç duyar. Connect Kafka ekosisteminin oldukça güzel tamamlayıcı ve önemli bileşenlerinden biridir. Kafka ile beraber geliştiriliyor olmasının bir avantajı da Kafka’nın çok dinamik ve güçlü bir topluluğu var bu avantaj Connect’in de kısa sürede oldukça iyi bir duruma gelmesini sağlamıştır. Kafka’yı bilen geliştiriciler ve yöneten adminler Connect’e çok yabancılık çekmezler. Kafka bilenler için Connect’e geçişte pozitif bir transfer söz konusudur, öğrenmeyi kolaylaştırır. Ayrıca Connect Kafka’yı bir veri tabanı gibi kullanır bu yüzden Kafka haricinde durum bilgilerini saklamak için ilave bir depolama (örn RDBMS, Postgresql gibi) ihtiyacı duymaz.
5. Connect Use Cases
Kafka Connect, Kafka’ya veri almayı veya Kafka’dan dışarı veri çıkarmayı içeren çok çeşitli durumlar için kullanılabilir.
5.1. Veri tabanı değişikliklerini yakalama (Change Data Capture – CDC)
Operasyonel veri tabanlarındaki değişikliklerin yakalanıp anlık olarak başka bir yere aktarılması genel bir ihtiyaç. Bu yakalama olayına Change Data Capture (CDC) deniyor. CDC’yi iki türlü yapabilirsiniz. İlki; sürekli sorgulayarak ki bu veri tabanına ilave yük bindirir. İkincisi; change loglarını okuyarak. Bu yöntem daha güvenilirdir ve veri tabanına ilave yükü olmaz. Debezium gibi bazı eklentiler ikinci yöntemi kullanmaya olanak tanır.
• 5.2. Kafka clusterlarını yansıtma (mirror)
Felaketten kurtulma (disaster recovery) ortamları kurma, Kafka cluster göçü (migrating clusters) ya da farklı coğrafi bir bölgeye replikasyon yapma (geo-replication) gibi sebeplerle Kafka clusterlar yansıtılır (mirroring). Yazma yoğun cluster ile okuma yoğun cluster ayrıştırmak istenebilir.
• 5.3. Veri gölü inşa etmenin bir parçası olma
Veriyi bir veri gölüne kopyalamak veya Amazon S3 gibi uygun maliyetli depolamaya arşivlemek için Kafka Connect’i kullanabilirsiniz. Connect’in veri depolama özelliği yoktur, Kafka’nın ise sınırlı ve kısa sürelidir bu nedenle büyük miktarda veriyi bir yere yazmanız veya uzun süre saklamanız gerekiyorsa (örneğin denetim amacıyla) Connect ile S3’e veri yazabilirsiniz. Veriye gelecekte tekrar ihtiyaç duyulursa, Kafka Connect ile verileri istediğiniz zaman geri aktarabilirsiniz.
• 5.4. Log Toplama (Log Aggregations)
Tüm uygulamalarınızdaki loglar, metrikler ve olaylar (events) gibi verileri depolamak ve toplamak genellikle faydalıdır. Veriler tek bir yerde olduğunda analiz edilmesi çok daha kolaydır. Ayrıca bulutun, konteynerlerin ve Kubernetes’in yükselişiyle birlikte altyapının iş yüklerinizi tamamen kaldırmasını ve bir hata tespit etmesi durumunda bunları sıfırdan yeniden oluşturmasını beklemelisiniz. Bu, loglar gibi verilerin kaybolmasını önlemek için dağınık uygulamaların lokal depoları yerine merkezi bir yerde saklanmasının önemli olduğu anlamına gelir. Kafka, büyük hacimli verileri çok düşük gecikmeyle işleyebildiğinden veri toplama için mükemmel bir seçimdir.
• 5.5. Klasik sistemlerin modernizasyonu
Modern mimariler, tek bir monolit yerine birçok küçük uygulamanın konuşlandırılmasına yönelmiştir. Bu, çok sayıda uygulamayla iletişim kurmanın getirdiği iş yükünü kaldıracak şekilde tasarlanmamış mevcut sistemlerde sorunlara neden olabilir. Ayrıca çoğu zaman gerçek zamanlı veri işlemeyi destekleyemezler. Kafka bir pub/sub mesajlaşma sistemi olduğundan, kendisine veri gönderen uygulamalar ile ondan veri okuyanlar arasında bir ayrım oluşturur. Bu, onu farklı sistemler arasında ara tampon olarak kullanmak için çok kullanışlı bir araç haline getirir. Eski verileri Kafka’da kullanılabilir hale getirmek için Kafka Connect’i kullanabilir, ardından yeni uygulamalarınızın bunun yerine Kafka’ya bağlanmasını sağlayabilirsiniz. Kafka uygulamalarının her zaman bağlı olmasına veya verileri gerçek zamanlı olarak okumasına gerek yoktur. Bu, eski uygulamaların yeniden yazma ihtiyacını ortadan kaldırarak verileri toplu olarak işlemesine olanak tanır.
Connect Alternatifleri
- Apache Camel
- Apache NiFi
- Apache Flume
- LinkedIn Hoptimator
Sonuç
Veriler genellikle birçok farklı sisteme yayılmış durumdadır. Bu durum verinin içgörü elde etmek ve müşterilere yenilikçi hizmetler sunmak için kullanmasını zorlaştırır. Kafka Connect gibi entegrasyon sistemleri, çeşitli sistemler arasında pipelines oluşturmak için kolay, ölçeklenebilir ve güvenilir mekanizmalar sağlayarak bu sorunları çözmek üzere tasarlanmıştır. Kafka Connect’i popüler kılan bazı temel özellikler:
- Kod gerektirmeden karmaşık pipelines oluşturmayı kolaylaştıran eklentili bir mimariye sahiptir.
- Operasyonu otomatize etmek için kullanışlı bir REST yönetim API’sine sahip, ölçeklenebilir ve güvenilirdir.
- Açık kaynak Apache Kafka projesinin bir parçasıdır ve gelişen Kafka topluluğunun gücünden yararlanır.
Kafka Connect, Kafka ve diğer Data Engineering konularını öğrenmek ve güzel bir eğitim almak istiyorsanız VBO Data Engineering Bootcamp‘i tavsiye ederiz.
Ayrıca uzman yardımı ve danışmanlık ihtiyacınız varsa info@datalonga.com e-posta adresinden veya +90 212 231 30 01 numaralı telefondan bilgi alabilirsiniz.
Başka bir yazıda buluşuncaya dek hoşça kalın…
Kaynaklar
- Kapak Foto: Photo by Alexas_Fotos on Unsplash
- Kafka Connect, Mickael Maison, Kate Stanley, O’Reilly, 2023.


