
Nokta Tahmini, Aralık Tahmini ve NGBoost Algoritması


 (6 votes, average: 2,33 out of 5)
(6 votes, average: 2,33 out of 5)Bir Veri Bilimi projesinde en önemli olan şey iş problemidir ve amacımız belirsizlik içeren iş problemini çözümleyebilmektir.
Projeye başlamadan sorulması gereken bazı soruların, analist arkadaşlar tarafından mutlaka sorulması gerekir.
- Problem nedir? Hangi belirsizliği ortadan kaldırmak istiyorum?
- Problem bir Makine Öğrenmesi problemi midir?
- Problemin çözümü neye hizmet edecektir? Hangi iş biriminin operasyonel yükü hafifletecektir?
- Bağımlı (Hedef) değişkenim nedir? Neyi tahmin edeceğim?
- Nasıl bir çıktı üreteceğim?
- Hangi veriler bu problemi çözümlemede kullanılabilir?
- Hangi yetkili kişiler iş problemini ve verileri açıklayabilir?
- Problem hangi Makine Öğrenmesi türüne girer? Gözetimli, Gözetimsiz, Yarı Gözetimli öğrenme türünden hangi konu problemime uygun?
- Regresyon, Sınıflandırma, Zaman Serisi ve Kümeleme yöntemlerinden hangi analizi türü uygulanacak?
Doğru soruların sorulduğunu ve cevapların alındığı bir regresyon problemini düşünelim. Tüm Veri Bilimi süreçlerini teker teker hallettikten sonra en başarılı model tercih edilir ve bu model kullanılarak tahminler elde edilir. Fakat elde edilen tahminler bir nokta tahmini midir yani bir ortalama mıdır yoksa bir aralık tahmini olup iki aralık arasındaki herhangi bir değeri alabilen değerler midir?
Regresyon modellerinin çoğu nokta tahminler üretmektedir. Fakat bazı problemler için nokta tahmini yapmak doğru değildir, bu problemleri bir ortalama değer ile açıklamak yerine alabileceği değerler ile açıklamak gerekir. Özellikle bilinmezliğin yüksek olduğu ve önemli konularda nokta tahmini yapmak ve kararları ortalama değerler ile almak yanlış bir tercih olacaktır. Bu gibi durumlarda model tercihini değiştirmeli ve aralık tahminleri üreten modellere eğilim gösterilmelidir.
NGBoost algoritması olasılıksal tahminler üretmektedir ve tahmin aralıkları oluşturmaktadır. Aralık tahminine ihtiyacımız olduğunda NGBoost algoritması kullanabileceğimiz algoritmalardan bir tanesidir.
NGBoost algoritmasının dokümantasyonundaki veri setini kullanarak farklı alfa değerlerine göre aralık tahminleri oluşturulacaktır. Ayrıca modelin görselleştirilmesi ve optimizasyonu üzerine de uygulamalar yapılacaktır.
1. Kütüphaneler
Çalışma içerisinde kullanılan tüm Python kütüphanelerini aşağıda görebilirsiniz.
# Base
# -------------------------------------------
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# NGBoost
# -------------------------------------------
#!pip install ngboost
from ngboost import NGBRegressor
# Sklearn
# -------------------------------------------
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, r2_score
from sklearn.tree import DecisionTreeRegressor
from sklearn.model_selection import GridSearchCV, RandomizedSearchCV
# Multiprocessing
# -------------------------------------------
import itertools
import multiprocessing as mp
from multiprocessing import Pool as ThreadPool
# Configuration
# ----------------------------------------
import warnings
warnings.filterwarnings("ignore")
warnings.simplefilter(action='ignore', category=FutureWarning)
pd.set_option('display.max_columns'2. Veri
Çalışmada kullanılan veri seti NGBoost dokümantasyonunda yer alan veri setidir. 506 gözlem ve 14 değişkenden oluşmaktadır. sklearn.datasets içerisinden kolaylıkla veri setine ulaşılabilir.
Bu çalışmanın temel amacı nokta tahmini ve aralık tahmini vurgusudur. NGBoost olasılıksal tahminleme ile aralık tahmininde bulunma olanağı sunduğundan bu aralık tahminin nasıl oluşturulduğunu ve görselleştirilmesini inceleyeceğiz.
NGBoost algoritması hakkında detaylı bilgiye sahip olmak isterseniz. Stanford ML Group tarafından oluşturulan kaynaklara bakmanızı tavsiye ederim.
Stanford ML Group: https://stanfordmlgroup.github.io/projects/ngboost/
NGBoost Makalesi: https://arxiv.org/abs/1910.03225https://arxiv.org/abs/1910.03225
Github: https://github.com/stanfordmlgroup/ngboost
Dokümantasyon: https://stanfordmlgroup.github.io/ngboost/intro.html
Türkçe kaynak olarak Veri Bilimi Okulu yazarlarından Utku Kubilay Çınar’ın yazısına aşağıdaki linkten ulaşabilirsiniz. https://www.veribilimiokulu.com/ngboost-algoritmasi/
X, Y = load_boston(True) X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2) X_train.shape, X_test.shape
((404, 13), (102, 13))
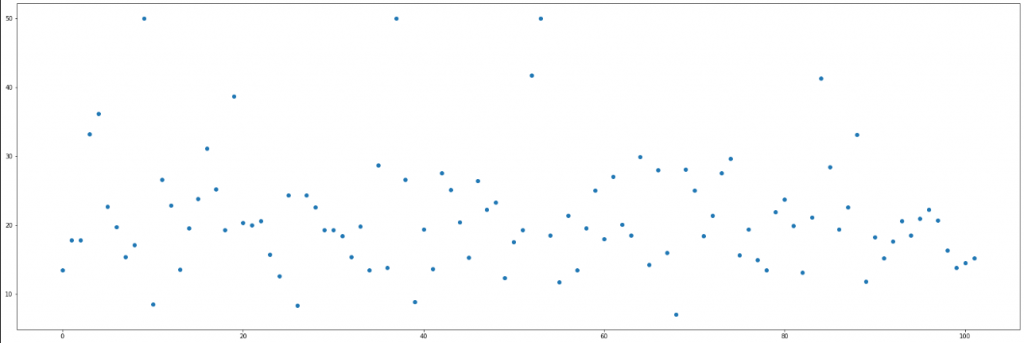
Train Test ayrımından sonra aşağıdaki görselleştirme kodu test verisi ile Y (Bağımlı veya Hedef Değişken) değerlerinin yapısını görebilirsiniz. Eğiteceğimiz model ile bu gözlemlere tahminler üreteceğiz ve tahmin aralıklarını oluşturacağız.
fig, ax = plt.subplots(figsize = (30,10)) ax.scatter(range(0,len(X_test)),Y_test, label = "Test Actual")
3. NGBoost Modeli

NGBoost algoritmasının üç bileşeni vardır. Base Learners, Distribution ve Scoring Rule. Paylaştığım dokümantasyonlarda bu bileşenlerin detayları yer aldığından teorik detaylarda boğulma kısmına girmiyorum. Sadece algoritma içerisinde bir Base parametresi olduğunu ve bu Base parametresinin bir algoritma olduğunu bilmemiz şu an için yeterlidir.
NGBoost algoritması herhangi bir sklearn regressor algoritmasını base learner olarak kullanabilirler ve base learner algoritma içerisinde Base argümanı içerisine tanımlanır. Base Learner’ın varsayılan hali 3 derinliğe (max_depth = 3) sahip regresyon ağacıdır.
Aşağıdaki model varsayılan parametreler ile oluşturulmuş bir modeldir. NGBRegressor() ve Base Learner için de DecisionTreeRegressor() tercih edildiğinde aşağıdaki parametreler ortaya çıkar.
Ayrıca fit fonksiyonu validasyon veri setlerini de almaktadır. Veri setini üçe böldüğümüz durumlarda validasyon verilerini model eğitimi sırasında rahatlıkla kullanabiliyoruz.
ngb = NGBRegressor(
Base=DecisionTreeRegressor(
ccp_alpha=0.0, criterion='friedman_mse',
max_depth=3, max_features=None,
max_leaf_nodes=None,
min_impurity_decrease=0.0,
min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0,
presort='deprecated',
random_state=None,
splitter='best'),
learning_rate=0.01,
minibatch_frac=1.0,
n_estimators=500,
natural_gradient=True,
random_state=None,
tol=0.0001,
verbose=True,
verbose_eval=100
)
ngb.fit(X_train, Y_train,
X_val = None, Y_val = None,
sample_weight=None,
val_sample_weight=None,
train_loss_monitor=None,
val_loss_monitor=None,
early_stopping_rounds=None
)Model eğitildikten sonra nokta tahminleri ile RMSE değerlerine bakılır ve modelin başarısı ölçülür.
print("Train RMSE:", np.sqrt(mean_squared_error(ngb.predict(X_train), Y_train)).round(4))
print("Test RMSE:", np.sqrt(mean_squared_error(ngb.predict(X_test), Y_test)).round(4))Train RMSE: 1.4904 Test RMSE: 2.8141
NGBoost algoritmasının nokta tahmini ve aralık tahmini verdiği bilgisini artık biliyoruz. predict() fonksiyonu bize nokta tahminini, pred_dist() fonksiyonu da bizi aralık tahminine bir tık daha yaklaştırmaktadır.
# Nokta Tahmini Y_preds = ngb.predict(X_test) # Tahmin Aralığı Y_dists = ngb.pred_dist(X_test)
pred_dist() fonksiyonu tahmin edilen ortalama ve standart sapmayı verir. Bu değerlere ulaşmak için Y_dists nesnesi içerisinden params kullanılır. loc değerleri tahmin edilen ortalamayı, scale değerleri ise standart sapmayı verir. Bu değerler kullanılarak aralık tahminleri oluşturulur.
Y_dists[0:5].params
{'loc': array([12.06203252, 15.22796674, 18.08542041, 35.34487703, 34.69158578]),
'scale': array([1.6462 , 1.50882268, 1.93313014, 0.99427897, 1.90316202])}Tahmin edilen ortalama ve standart sapma değerlerine ayrıca da ulaşılabilir.
Y_dists.loc[:5] array([12.06203252, 15.22796674, 18.08542041, 35.34487703, 34.69158578]) Y_dists.scale[:5] array([1.6462 , 1.50882268, 1.93313014, 0.99427897, 1.90316202])
Aralık tahmini oluşturulmak istenildiğinde bu iki şekilde gerçekleştirilebilir.
İlk olarak formülasyona girmeden pred_dist() fonksiyonu ile oluşturulan Y_dists nesnesi ie dist.interval() fonksiyonu içerisine 0-1 arasında istenilen alfa değeri girildiğinde aralık tahminlerine ulaşılmış olur.
İkinci yöntem olarak loc ve scale değerlerini güven aralığı formülü ile kullandığımızda aynı sonuçları elde ederiz.
pd.DataFrame({
"CI Formula Lower 0.95": (Y_dists.loc - 1.96 * Y_dists.scale).round(4),
"NGB Interval Lower 0.95": Y_dists.dist.interval(alpha = 0.95)[0].round(4),
"CI Formula Upper 0.95": (Y_dists.loc + 1.96 * Y_dists.scale).round(4),
"NGB Interval Upper 0.95": Y_dists.dist.interval(alpha = 0.95)[1].round(4)
}).head()| CI Formula Lower 0.95 | NGB Interval Lower 0.95 | CI Formula Upper 0.95 | NGB Interval Upper 0.95 | |
|---|---|---|---|---|
| 0 | 8.8355 | 8.8355 | 15.2886 | 15.2885 |
| 1 | 12.2707 | 12.2707 | 18.1853 | 18.1852 |
| 2 | 14.2965 | 14.2966 | 21.8744 | 21.8743 |
| 3 | 33.3961 | 33.3961 | 37.2937 | 37.2936 |
| 4 | 30.9614 | 30.9615 | 38.4218 | 38.4217 |
Farklı alfa değerleri dist.interval() fonksiyonuna tanımlandığında istenilen aralık tahminleri elde edilir.
res = pd.DataFrame({
"Actual":Y_test,
"NGB Point Estimation":Y_preds,
"NGB Interval Lower 0.80": Y_dists.dist.interval(alpha = 0.80)[0],
"NGB Interval Upper 0.80": Y_dists.dist.interval(alpha = 0.80)[1],
"NGB Interval Lower 0.90": Y_dists.dist.interval(alpha = 0.90)[0],
"NGB Interval Upper 0.90": Y_dists.dist.interval(alpha = 0.90)[1],
"NGB Interval Lower 0.95": Y_dists.dist.interval(alpha = 0.95)[0],
"NGB Interval Upper 0.95": Y_dists.dist.interval(alpha = 0.95)[1],
})
res.head()| Actual | NGB Poınt Estımatıon | NGB Interval Lower 0.80 | NGB Interval Upper 0.80 | NGB Interval Lower 0.90 | NGB Interval Upper 0.90 | NGB Interval Lower 0.95 | NGB Interval Upper 0.95 | |
|---|---|---|---|---|---|---|---|---|
| 0 | 13.4 | 12.062033 | 9.952342 | 14.171723 | 9.354274 | 14.769791 | 8.835540 | 15.288525 |
| 1 | 17.8 | 15.227967 | 13.294333 | 17.161601 | 12.746174 | 17.709759 | 12.270729 | 18.185205 |
| 2 | 17.8 | 18.085420 | 15.608014 | 20.562826 | 14.905704 | 21.265137 | 14.296555 | 21.874286 |
| 3 | 33.2 | 35.344877 | 34.070657 | 36.619097 | 33.709434 | 36.980320 | 33.396126 | 37.293628 |
| 4 | 36.2 | 34.691586 | 32.252586 | 37.130586 | 31.561163 | 37.822009 | 30.961457 | 38.421715 |
Elde edilen değerler ile model sonuçlarını görselleştirelim. İlk görsel 0.95 aralığında görselleştirilmiş. İkinci görselde de 0.80, 0.90 ve 0.95 aralıklarında tahminler görselleştirilmiştir.
fig, ax = plt.subplots(figsize = (30,10))
ax.scatter(res.index,res.Actual, label = "Test Actual")
ax.plot(res["NGB Point Estimation"], color = "g", label = "NGB Point Estimation")
# 0.95 tahmin aralığının oluşturulması
ax.fill_between(np.arange(0, len(res)), res["NGB Interval Lower 0.95"], res["NGB Interval Upper 0.95"],
label = "NGB Intervals 0.95", color = "gray", alpha = 0.5)
ax.legend(fontsize = 15)
ax.set_ylabel('Dependent Varaible')
ax.set_xlabel('Index')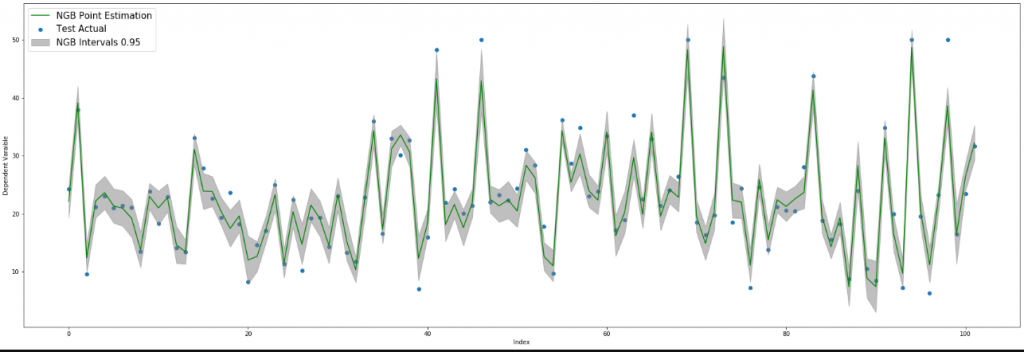
fig, ax = plt.subplots(figsize = (30,10))
ax.scatter(res.index,res.Actual, label = "Test Actual")
ax.plot(res["NGB Point Estimation"], color = "g", label = "NGB Point Estimation")
# 0.95 tahmin aralığının oluşturulması
ax.fill_between(np.arange(0, len(res)), res["NGB Interval Lower 0.95"], res["NGB Interval Upper 0.95"],
label = "NGB Intervals 0.95", color = "gray", alpha = 1)
# 0.90 tahmin aralığının oluşturulması
ax.fill_between(np.arange(0, len(res)), res["NGB Interval Lower 0.90"], res["NGB Interval Upper 0.90"],
label = "NGB Intervals 0.90", color = "lightblue",alpha = 1)
# 0.80 tahmin aralığının oluşturulması
ax.fill_between(np.arange(0, len(res)), res["NGB Interval Lower 0.80"], res["NGB Interval Upper 0.80"],
label = "NGB Intervals 0.80", color = "orange",alpha = 0.5)
ax.legend(fontsize = 15)
ax.set_ylabel('Dependent Varaible')
ax.set_xlabel('Index')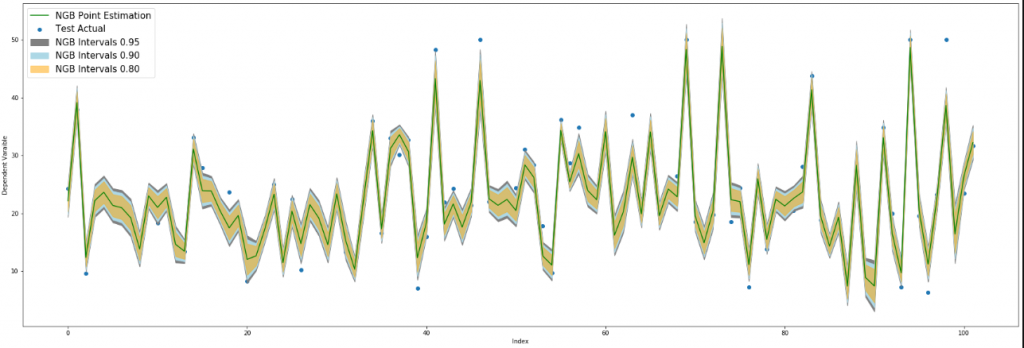
4. Model Tuning
Her modelleme çalışmasında olduğu gibi modelin optimizasyonu için hiperparametre ayarlamaları yapılmaktadır.
NGBoost modeli hiperparemetreleri iki aşamadan oluşmaktadır. İlk olarak NGBoost’un kendi parametreleri ikinci olarak tercih edilen Base Learner algoritmasının parametreleridir.
Search algoritmaları kullanılarak bu hiperparametreler bulunabilir. Base Learner parametreleri için birden fazla Base Learner’lar tanımlamak gerekmektedir. Ardından search algoritması için params içerisine Base Learner’lar liste olarak tanımlanır.
Örnek olarak dokümantasyonda olduğu gibi aşağıdaki uygulama sayesinde bazı parametreleri arayabilirsiniz.
b1 = DecisionTreeRegressor(criterion='friedman_mse', max_depth=2)
b2 = DecisionTreeRegressor(criterion='friedman_mse', max_depth=4)
params = {
'minibatch_frac': [1.0, 0.5],
'Base': [b1, b2]
}
ngb = NGBRegressor()
grid_search = GridSearchCV(ngb, param_grid=params, cv=5)
grid_search.fit(X_train, Y_train)
print(grid_search.best_params_)NGBoost optimizasyonundaki temel sorun Base Learner parametrelerini search algoritmasına direk verememektir. Farklı Base parametreleri oluşturarak bunları search algoritmasına sokmak gerekiyor.
Benim yazdığım aşağıdaki kod ile girilen Base Learner parametrelerine göre Base kombinasyonları oluşturulmaktadır. Ardından bu kombinasyonlar NGBoost parametreleri ile birleştirilerek search algoritmalarına sokulabilir. Ancak NGBoost, LightGBM gibi hızlı çalışan bir algoritma değildir. Base kombinasyonlarının fazla oluşturulması işlem yükünü çok arttıracağından uygun parametreleri bulması çok uzun sürecektir.
# --------------------------------------
# Aranacak Hiperparametreler
# --------------------------------------
# 1. Base Learner Parametreleri
ccp_alpha = np.arange(0.0, 0.3, 0.1)
max_depth = np.arange(3, 6, 1)
min_impurity_decrease = np.arange(0.0, 0.3, 0.1)
min_impurity_split = np.arange(0.0, 0.3, 0.1)
min_samples_split = np.arange(2,5,1)
min_weight_fraction_leaf = np.arange(0.0, 0.3, 0.1)
# 2. NGBoost Parametreleri
learning_rate = [0.05, 0.1],
minibatch_frac = [1.0, 0.5],
n_estimators = [100, 200]
# --------------------------------------
# Tüm Base Learner Modellerin Oluşturulması
# --------------------------------------
def NGBoostTuning(paramlist):
Base=DecisionTreeRegressor(
ccp_alpha = paramlist[0],
max_depth = paramlist[1],
min_impurity_decrease = paramlist[2]
)
return Base
pool = ThreadPool(mp.cpu_count())
BaseLearners = pool.map(NGBoostTuning, list(itertools.product(
ccp_alpha, max_depth, min_impurity_decrease
)))
pool.close()
del pool
# --------------------------------------
# Parametrelerin Tanımlanması
# --------------------------------------
# Yukarıda oluşturulan tüm hiperparametreler aşağıya tanımlanır.
params = {
# Tüm Base Learner algoritmaları Base içerisine tanımlanır:
'Base': BaseLearners ,
# NGBoost hiperparametreleri tanımlanır:
'minibatch_frac': minibatch_frac,
'learning_rate': learning_rate,
'n_estimators': n_estimators
}
# --------------------------------------
# Search İşlemi
# --------------------------------------
ngb = NGBRegressor(verbose = False) # Çok fazla kombinasyon olduğundan verbose False yapılırsa ara çıktılar gözükmez!
grid_search = GridSearchCV(ngb, param_grid = params, cv = 5)
grid_search.fit(X_train, Y_train)
print(grid_search.best_params_)5. Sonuç
Genel itibariyle NGBoost algoritmasının nasıl kullanıldığı, nokta tahmini ve aralık tahmini oluşturma, model sonuçlarının görselleştirilmesi ve optimizasyonu konusunda bilgi vermeye çalıştım.
NGBoost algoritması yeni çıkan bir algoritma olduğu için yeni kaynaklar oluştukça ve uygulamalar arttıkça kafamızdaki soru işaretleri zaman içerisinde giderilecektir. Şu an için bakıldığında benim yorumum aralık tahmini için NGBoost algoritması işe yarayabilecek türden bir algoritmadır ve en büyük sorunu da LightGBM’e göre yavaş çalışmasıdır.
Bir sonraki yazılarda görüşmek üzere.


