Knime ve Zemberek NLP ile Türkçe Döküman Sınıflandırma
 (1 votes, average: 5,00 out of 5)
(1 votes, average: 5,00 out of 5)Merhaba VBO okurları, VBO ailesine yeni katılmış bir yazar olarak ilgi çekici olduğunu düşündüğüm bir konu ile başlangıç yapmak istedim. Knime platformunun kullanımı, Knime içerisinde Python ve Python içerisinde Knime kullanımı, oluşturduğumuz makine öğrenimi modellerinin REST API olarak Python ile deploy edilmesi gibi konuları ele alacağım Knime serisine başlamadan önce bu yazımda uçtan uca bir Türkçe metin sınıflandırma uygulamasının Knime ile yapılışını basitçe anlatacağım.
Knime uygulamasının işletim sisteminize uyumlu sürümünü bu linkten indirebilirsiniz.
Yapacağımız uygulamada kullanacağımız örnek veriyi bu linkten indirebilirsiniz.
Öncelikle Knime nedir ondan bahsedelim. Knime ya da Knime Analytics Platform, uçtan uca birbirine bağlanmış fonksiyonel düğümler ile veri manipülasyonları, hesaplamalar ve görselleştirmeler yapabileceğimiz görsel arayüze sahip bir platformdur. Knime kullanıcı arayüzü hakkında öncelikle en çok işinize yarayacak dört bölümden bahsetmek istiyorum. Bunlar:
1. Node Repository (Düğüm Deposu)
Pencerenin sol alt tarafında yer alan bu bölüm içerisinde çeşitli fonksiyonlara sahip düğümler yer alıyor. Buradaki düğümleri ihtiyacınıza göre sürükleyip bırakarak kullanabiliyorsunuz.
2. Description (Açıklama)

Pencerenin sağ üst köşesinde yer alan bu kısımda, üzerine bir kere tıkladığınız düğümlerin ne işe yaradığı, giriş ve çıkışlarının ne anlama geldiği ve parametrelerinin ne anlama geldiğini yani düğüm deposundaki düğümler hakkında bilmeniz gereken her şeyi size açıklayan bir döküman bulunuyor. Başlangıçta çok işinize yarayacak.
3. Workflow (İş Akışı)

İşte bu düğümleri yerleştirdiğimiz çalışma alanımız burası. Kullanmak istediğimiz düğümleri bu alana sürükleyeceğiz ve bu alanda birbiri ile bağlayıp akışımızı oluşturacağız.
4. Console (Konsol)
Son olarak sağ altta yer alan bir konsolumuz bulunmakta. Düğümleri çalıştırdığımızda alabileceğimiz hataları bu konsolda göreceğimiz için bu da en çok kullanacağımız bölümlerden biri.
Uygulama
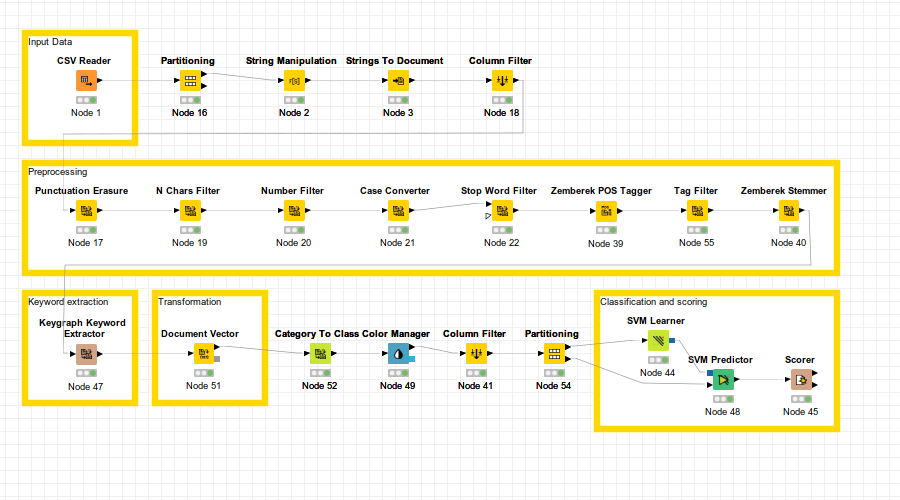
Bu uygulamada sonuç olarak oluşturacağımız Knime iş akışı aşağıdaki gibi görünecektir. Bu iş akışını kendi bilgisayarınıza bu linkten indirebilirsiniz.
Şimdi tüm bu akış içerisindeki her bir düğümü açıklayacağım.
 Node 1: CSV Reader
Node 1: CSV Reader
 Node 1: CSV Reader
Node 1: CSV ReaderVerimizi indirdikten sonra Knime iş akışına getirmek için, veri bir csv dosyası olduğu için, CSV Reader düğümünü kullanacağız. Düğümü depodan bulup iş akışına sürükledikten sonra üzerine çift tıklayarak yapılandırma penceresini açabilirsiniz. Burada ayarlar sekmesinde karşımıza iki bölüm çıkıyor bunlardan ilki olan Input location kısmından dosyamızı bulup seçiyoruz. İkinci bölüm olan Reader options kısmında ise karşımızda farklı durumlarda işimize yarayacak seçenekler çıkıyor. Bu seçeneklerden en önemlilerinin Has Column Header (Sütun Başlığı Var) ve Has Row Header (Satır Başlığı Var) olduğunu söyleyebilirim. Çoğu zaman satır başlığı olmadığından bu seçenekte hep seçimi kaldırmanız gerekebilir. Yoksa ilk sütunu satır başlığı olarak kabul edecektir. Genelde çoğu veride sütun başlığı olduğundan bu seçeneği ise değiştirmeden bırakırız ama bu veri içerisinde sütun başlığı yok yani eğer seçimi kaldırmazsanız ilk satırı sütun başlığı olarak kabul edecektir. OK ile seçenekleri kabul edip yapılandırmadan çıkalım.

Şimdi de oluşturduğumuz düğüme sağ tıklayıp Execute ile düğümü çalıştıralım. Düğümün hemen altındaki üç noktayı farketmişsinizdir. Düğüm hatasız çalıştıysa bu noktalardan en sondaki yeşil olacaktır. Düğüm başarı ile çalıştıktan sonra tekrar düğüme sağ tıklayıp en alttaki File Table ile Knime a getirdiğimiz veriyi tablo olarak görüntüleyebiliriz.

Node 16: Partitioning
 Node 16: Partitioning
Node 16: PartitioningBu düğümü genelde veriyi eğitim ve test olarak ikiye ayırmak istediğimizde kullanırız. Ama benim burada kullanma amacım biraz farklı. Kullandığımız veri epey büyük olduğundan bilgisayarınızın belleği bu iş akışını çalıştırmanıza yetmeyebilir. Bu amaçla bu düğümü verinin bir kısmını almak için kullanabilirsiniz. Bunu yapmak için düğümün üstteki çıkışından verinin ne kadarlık kısmının çıkacağını Choose size of first partition kısmında Relative[%] seçeneğini işaretleyip burada yüzdelik dilimi girebilirsiniz. %10 – 15’lik bir diilm işinizi görecektir. Tabi sonuçta elde edeceğiniz doğruluk farklı olacaktır. Bu düğüm içerisinde önemli bir parametre daha var o da Stratified sampling. Bu seçeneği seçip kolon olarak ta kategoriyi içeren kolonu seçmeniz gerekiyor. Böylece böldüğünüz kısımda her kategoriden eşit miktarda döküman elde edeceksiniz.

Node 2: String Manipulation
 Node 2: String Manipulation
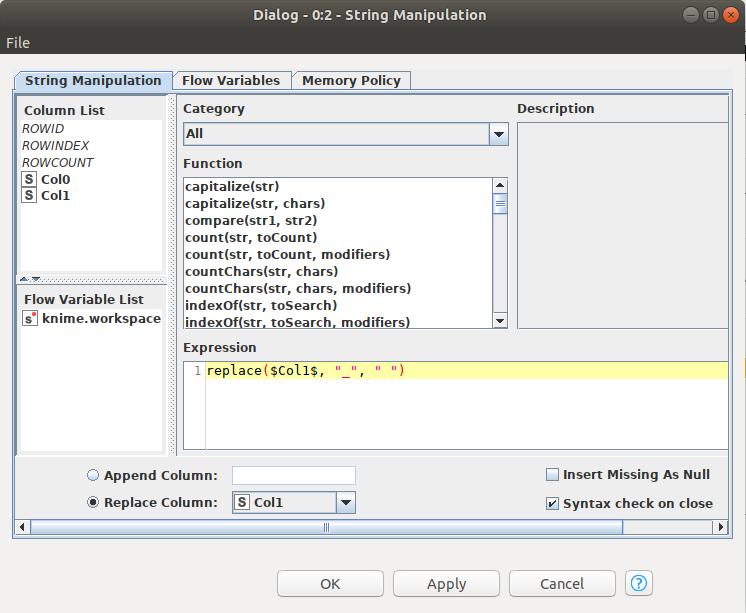
Node 2: String ManipulationElimizdeki verimiz aslında bir ön işlemeden geçmiş bir veri yani içerisinde bazı özel isimler alt tireler kullanılarak birleştirilmiş. Mesela “genel_başkan_yardımcısı” gibi ama her zaman böyle bir veri bulamayacağımızdan bu düğüm içerisindeki replace fonksiyonu ile alt tireleri boşluklara geri dönüştürdüm.
Node 3: String To Document
 Node 3: String To Document
Node 3: String To DocumentBu uygulamada metin işleme ile ilgili kullacağımız bazı özel düğümler var. Bu düğümleri kullanabilmek için Text Processing eklentisini yüklemeniz gerekiyor. Neyseki Knime eklentilerini kolayca yükleyebiliyoruz. Bunun için File sekmesi içerisinde Install Knime Extensions aracını kullanabiliriz. Burada yüklemek istediğiniz eklentinin ismini aratıp kolayca yükleyebilirsiniz. Eklenti yüklendikten sonra Knime yeniden başlatılacaktır.
Elimizdeki veri şu an karakter dizisi (string) formatında yüklediğimiz eklenti içerisindeki düğümleri kullanabilmek için bu düğümü kullanarak karakter dizisi formatında olan veriyi döküman (document) formatına dönüştürmemiz gerekiyor.

Bizim verimizde bir başlık olmadığından Title kısmında Empty string seçeneğini işaretleyin. Text kısmında sınıflandıracağımız karakter dizisini seçin ve son olarak ta Meta Information kısmında Use authors from column seçeneğini kaldırıp Use categories from column seçeneğini seçin ve Document category column kısmında kategori bilgisini içeren kolonu seçin. Tokenization kısmında ise Word tokenizer seçenekleri arasından Türkçe için Zemberek Turkish Tokenizer seçeneğini seçin.
Node 18: Column Filter
 Node 18: Column Filter
Node 18: Column FilterBu düğüm Knime içerisinde en çok kullanacağınız düğümlerden biridir. Veri tablonuz içerisinde istemediğiniz sütunları filtre etmekte kullanabilirsiniz. Ben de bu uygulamada bu şekilde kullandım. İhtiyacım olan tüm bilgiyi oluşturduğum dökümanlar içine yazdığım için ilk sütunlara artık ihtiyacım kalmadı. Bu düğümü kullanarak ihtiyacım olmayan sütunlardan kurtuldum.

Node 17: Punctuation Erasure
 Node 17: Punctuation Erasure
Node 17: Punctuation ErasureArtık ön işleme aşamasına geldik. Bu düğüm de yüklediğimiz eklenti ile gelen bir düğüm ve dökümanlar içerisindeki alfa-numerik olmayan özel karakterlerden kurtulmak için kullanıyoruz.

Node 18: N Chars Filter
Bu düğümü ise döküman içerisinde bulunmasını istediğimiz en küçük karakter sayısına sahip kelimeleri filtrelemek için kullanıyoruz. Burada girdiğimiz değerden daha düşük karakter sayısına sahip kelimeler filtreleniyor.

Node 20: Number Filter
Bu düğüm ile de döküman içerisindeki numerik karakterlerden kurtuluyoruz.

Node 21: Case Converter
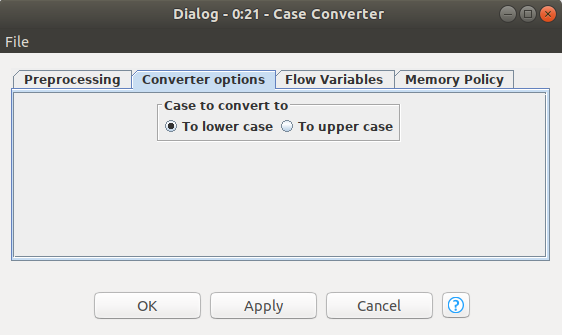
Bu düğüm de yine son bir kaç kullandığımız düğüm gibi basit bir amaca hizmet ediyor. Bu düğüm ile dökümanlar içerisindeki tüm karakterleri küçük harfe veya büyük harfe dönüştürebiliyoruz. Bu uygulamada tüm karakterleri küçük harfe dönüştürdüm.
Node 22: Stop Word Filter
Etkisiz kelimeler (stop words); acaba, ancak, ama gibi bir dilde çok sık kullanılan muhtemelen sınıflandırmak istediğimiz bu dökümanların hepsinde epey bir görebileceğimiz kelimelerdir. Bu gibi uygulamalarda genelde bu kelimeleri istemeyiz. Bu düğüm de bu kelimeleri filtrelemek yani dökümandan çıkarmak için kullanılıyor. Burada yalnızca Stopword lists kısmından Turkish seçeneğini seçmemiz gerekiyor. Eğer kendi etkisiz kelimeler listenizi ekleyecekseniz bunu düğümün alttaki girişinden ekleyerek yapabilirsiniz.

Node 39: Zemberek POS Tagger
 Node 39: Zemberek POS Tagger
Node 39: Zemberek POS TaggerBurada POS, Part Of Speech yani Türkçede bildiğimiz adıyla Cümlenin öğeleri anlamına geliyor. Bu düğümü kullanarak döküman içerisindeki cümlelerin öğelerini işaretliyoruz. Burada Word tokenizer kısmından Zemberek Turkish Tokenizer seçeneğini seçmemiz gerekiyor.

Node 55: Tag Filter
Bu düğüm ile de bir önceki düğümde işaretlediğimiz öğeleri filtreleyeceğiz. Bu uygulamada yalnızca isimleri seçmeyi tercih ediyorum. Bunu yapmak için öncelikle Zemberek kullandığımız için Tag type kısmından ZEMNLP seçeneğinisonra da Tags kısmından NOUN seçeneğini seçiyoruz.

Node 40: Zemberek Stemmer
Geldik ön işleme kısmının son düğümüne. Bu düğümde de son olarak kelimeleri köklerine ayırıyoruz. Çünkü aynı kelimenin ekler ile oluşmuş farklı varyasyonları çok fazla değişken oluşmasına yol açacaktır.

Node 47: Keygraph Keyword Extractor
 Node 47: Keygraph Keyword Extractor
Node 47: Keygraph Keyword ExtractorBu düğümü kullanarak dökümanlarımız içerisindeki önemli kelimeleri otomatik olarak bulduracağız. Burada her döküman için elde edilecek kelime sayısını 15 olarak seçtim. Bu parametreyi değiştirerek modelin doğruluğu üzerinde nasıl bir etkisi olduğunu gözlemleyebilirsiniz.

Node 51: Document Vector
 Node 51: Document Vector
Node 51: Document VectorDökümanlar üzerinde bir sınıflandırma yapabilmek için sayısal değerler içeren değişkenlere ihtiyacımız var. Bu düğüm ile dökümanlarımızı vektörlere dönüştürüyoruz.
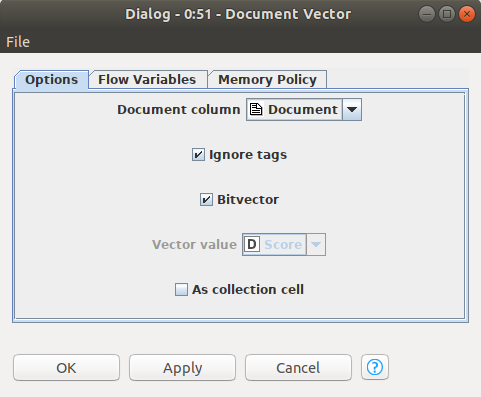
Node 52: Category To Class
 Node 52: Category To Class
Node 52: Category To ClassŞimdi modelimizi eğitebilmek için bir de hedef sütununa ihtiyacımız var. Bu hedef sütununu ise en başta dökümanlarımızın metadatalarına yazdığımız sınıf kısmından geri çekeceğiz.

Node 49: Color Manager
 Node 49: Color Manager
Node 49: Color ManagerBu düğüm aslında bu uygulamada bir etkisi olmayan, çok da gerekli olmayan bir düğüm yalnızca göstermek için ekledim. Bu düğümü kullanarak tablo içerisindeki verilerinize renkler atayabiliyorsunuz. Burada hedef kategorilere renkler atayarak tabloya baktığımızda daha rahat ayırt edebilmeyi sağlamış olduk. Bunu kullanmasaydık da birşey değişmeyecekti.

Node 54: Partitioning
En başta kullandığımız bu düğümü burada bu sefer gerçek amacı için yani verimizi test edebilmek için eğitim ve test verisine bölmek amacıyla kullandım. Burada verinin %70’lik kısmını eğitim, %30’luk kısmını ise test için ayırmış olduk.

Node 44: SVM Learner
 Node 44: SVM Learner
Node 44: SVM LearnerArtık eğitim aşamasına geçebiliriz. Bu uygulamada SVM (Support Vector Machines) algoritmasını kullanmayı tercih ettim. Hazırladığımız veriye uygun diğer sınıflandırma algoritmalarını da siz uygulayıp test edebilirsiniz. Bu düğüm ile eğitim için ayırdığımız veriyi kullanarak modelimizi eğitiyoruz. Burada Overlapping penalty parametresi için GridSearch gibi bir yöntem ile en uygun değeri belirleyebilirsiniz.

Node 48: SVM Predictor
 Node 48: SVM Predictor
Node 48: SVM PredictorBu düğüm ile de tahminlerimizi yapıyoruz. Üstteki girişinden eğittiğimiz modeli ve alttaki girişinden ise de tahmin yapacağımız test verisini veriyoruz.

Node 45: Scorer
 Node 45: Scorer
Node 45: ScorerGeldik uygulamamızın son kısmına. Bu düğüm ile oluşturduğumuz model ile yaptığımız test tahminlerinin sonuçlarını değerlendiriyoruz.

Değerlendirme
Verimizi içeri aktardık, gerekli ön işleme adımlarından geçirdik, veriyi sayısallaştırdık, modelimizi oluşturduk, eğittik ve test ettik. Şimdi ortaya çıkan sonuca bakalım. Scorer düğümüne sağ tıklayıp View: Confusion Matrix butonuna tıklayın. Aşağıdaki gibi bir pencereyle karşılaşacaksınız.

Burada karşınıza çıkan şey bir Karışıklık Matrisi (Confusion Matrix). Bu matris içerisinde sınıflandırma sonucunda bulunan kategorilerin kaç tanesinin diğer kategoriler ile karıştığını görebilirsiniz. Tüm dökümanların doğru sınıflandırıldığı durumda bu matrisin birim matris gibi görünmesi gerektiğini anlamışsınızdır. Bu pencerenin alt kısmında yer alan başarı kriterlerinden ise bizim için önemli iki kriter var bunlardan biri Doğruluk (Accuracy) diğeri is Cohen’s kappa (k). Doğruluk değeri test verimizin ne kadarlık bölümünü doğru sınıflandırdığımızı veriyor. Burada elde ettiğimiz %87.075 gayet güzel bir sonuç. Önceki aşamalarda seçtiğimiz parametreleri değiştirerek bu sonucu nasıl etkileyeceğini gözlemleyebilirsiniz. Diğer bir önemli kriter olan k ise yapılan tahmin sonucunda bulunan sınıfların doğruluğunun tesadüfi olup olmadığını gösteriyor. Buradaki k değerinin alacağı aralıkların karşılıkları aşağıdaki gibi diyebiliriz.
- < 0 : Hiç uyuşma olmaması
- 0.0–0.20 : Önemsiz uyuşma olması
- 0.21–0.40 : Orta derecede uyuşma olması
- 0.41–0.60 : Ekseriyetle uyuşma olması
- 0.61–0.80 : Önemli derecede uyuşma olması
- 0.81–1.00 : Neredeyse mükemmel uyuşma olması
Buna göre bizim elde ettiğimiz 0.849’lık k değeri sonucumuzda neredeyse mükemmel bir uyuşma olduğunu gösteriyor.
Bence basitçe anlatacağım diye başladığım bu yazı için yeterli denebilecek bir noktaya ulaştık. Knime ile yapılabilecek daha fazla şey için bir sonraki yazımı bekleyin. Umarım VBO’da yazığım bu ilk yazımda sizi sıkmamışımdır.
Kaynaklar
https://www.statisticshowto.datasciencecentral.com/cohens-kappa-statistic/



emeklerinize sağlık. çok açıklayıcı ve bir o kadar da faydalı bir çalışma olmuş.
Gökhan Bey, ellerinize sağlık, harika anlatmışsınız. Bir sorum olacak; input dosyasındaki gerçek kategorinin yanına tahminlenen sonucu getirmek istiyorum, bunu nasıl yapabilirim. Saygılarımla.
Teşekkürler, oldukça anlaşılır anlatmışsınız
Merhaba https://www.veribilimiokulu.com/kesifci_veri_analizi/#post-authorbu veri seti ve içinde kullanılan kodları nasıl ulaşa bilirim acil lazım bana